深入了解Java虚拟机栈以及内存模型
1、结合字节码指令理解Java虚拟机栈和栈帧
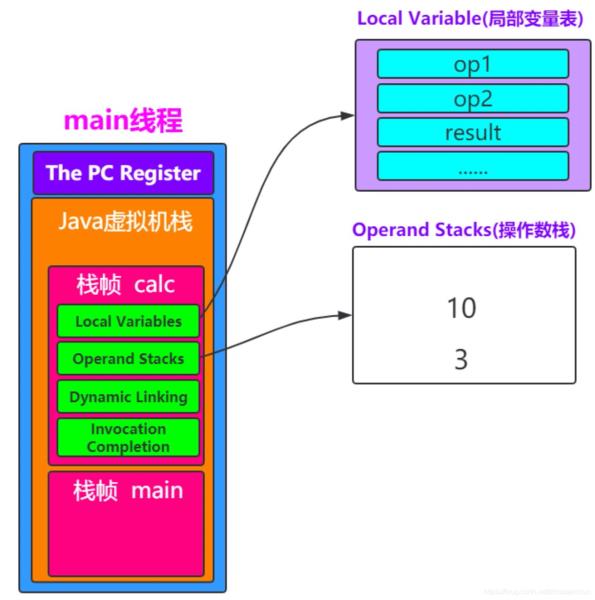
栈帧:每个栈帧对应一个被调用的方法,可以理解为一个方法的运行空间。
每个栈帧中包括局部变量表(Local Variables)、操作数栈(Operand Stack)、指向运行时常量池的引用(A reference to the run-time constant pool)、方法返回地址(Return Address)和附加信息。
局部变量表:方法中定义的局部变量以及方法的参数存放在这张表中,局部变量表中的变量不可直接使用,如需要使用的话,必须通过相关指令将其加载至操作数栈中作为操作数使用。
操作数栈:以压栈和出栈的方式存储操作数的。
动态链接:每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接(Dynamic Linking)。
方法返回地址:当一个方法开始执行后,只有两种方式可以退出,一种是遇到方法返回的字节码指令;一种是遇见异常,并且这个异常没有在方法体内得到处理。

class Person{
private String name="Jack";
private int age;
private final double salary=100;
private static String address;
private final static String hobby="Programming";
public void say(){
System.out.println("person say...");
}
public static int calc(int op1,int op2){
op1=3;
int result=op1+op2;
return result;
}
public static void order(){
}
public static void main(String[] args){
calc(1,2);
order();
}
}
Compiled from "Person.java" class Person {
...
public static int calc(int, int);
Code:
0: iconst_3 //将int类型常量3压入[操作数栈]
1: istore_0 //将int类型值存入[局部变量0]
2: iload_0 //从[局部变量0]中装载int类型值入栈
3: iload_1 //从[局部变量1]中装载int类型值入栈
4: iadd //将栈顶元素弹出栈,执行int类型的加法,结果入栈
【For example, the iadd instruction (§iadd) adds two int values together. It requires that the int values to be added be the top two values of the operand stack, pushed there by previous instructions. Both of the int values are popped from the operand stack. They are added, and their sum is pushed back onto the operand stack. Subcomputations may be nested on the operand stack, resulting in values that can be used by the encompassing computation.】
5: istore_2 //将栈顶int类型值保存到[局部变量2]中
6: iload_2 //从[局部变量2]中装载int类型值入栈
7: ireturn //从方法中返回int类型的数据
...
}
2、深入分析
2.1 栈指向堆
如果在栈帧中有一个变量,类型为引用类型,比如 Object obj=new Object(),这时候就是典型的栈中元素指向堆中的对象。

2.2 方法区指向堆
方法区中会存放静态变量,常量等数据。如果是下面这种情况,就是典型的方法区中元素指向堆中的对象。
private static Object obj=new Object();

2.3 堆指向方法区
方法区中会包含类的信息,堆中会有对象,那怎么知道对象是哪个类创建的呢?
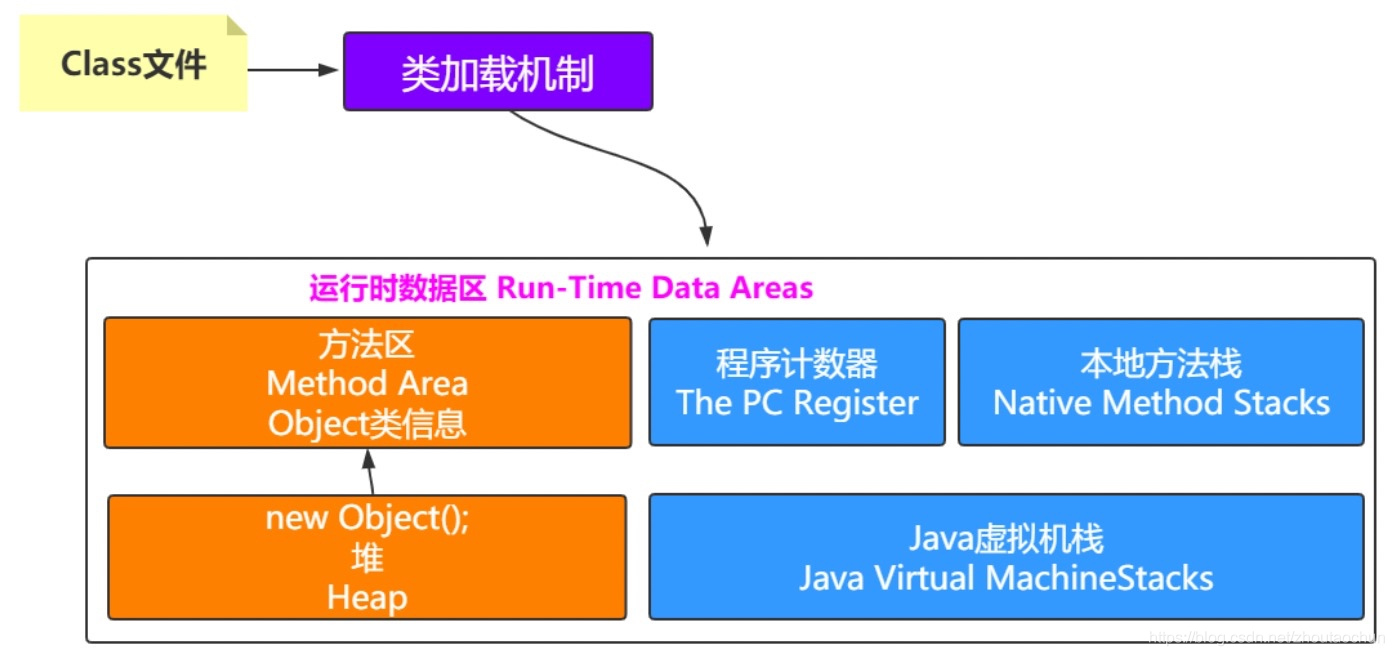
思考:一个对象怎么知道它是由哪个类创建出来的?怎么记录?这就需要了解一个Java对象的具体信息咯。
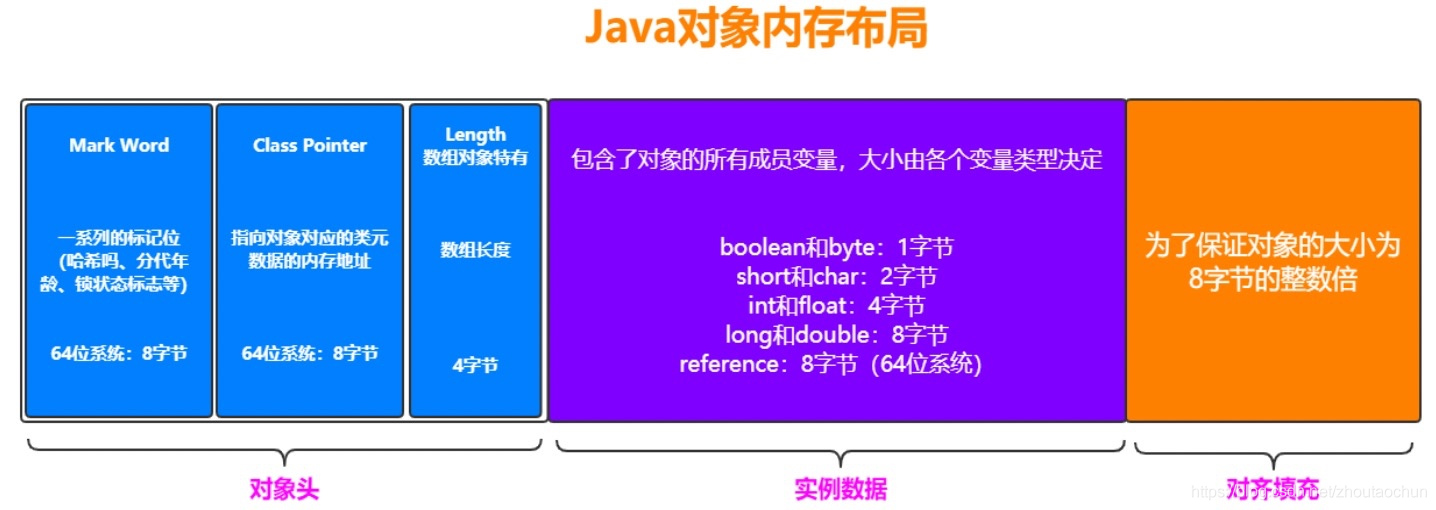
2.4 Java对象内存布局
一个Java对象在内存中包括3个部分:对象头、实例数据和对齐填充。
3、内存模型
3.1 图解
一块是非堆区,一块是堆区。
堆区分为两大块,一个是Old区,一个是Young区。 Young区分为两大块,一个是Survivor区(S0+S1),一块是Eden区。 Eden:S0:S1=8:1:1 S0和S1一样大,也可以叫From和To。

根据之前对于Heap的介绍可以知道,一般对象和数组的创建会在堆中分配内存空间,关键是堆中有这么多区域,那一个对象的创建到底在哪个区域呢?
3.2 对象创建所在区域
一般情况下,新创建的对象都会被分配到Eden区,一些特殊的大的对象会直接分配到Old区。
比如有对象A,B,C等创建在Eden区,但是Eden区的内存空间肯定有限,比如有100M,假如已经使用了 100M 或者达到一个设定的临界值,这时候就需要对Eden内存空间进行清理,即垃圾收集(Garbage Collect), 这样的GC我们称之为Minor GC,Minor GC指的是Young区的GC。
经过GC之后,有些对象就会被清理掉,有些对象可能还存活着,对于存活着的对象需要将其复制到Survivor 区,然后再清空Eden区中的这些对象。
3.3 Survivor区详解
由图解可以看出,Survivor区分为两块S0和S1,也可以叫做From和To。 在同一个时间点上,S0和S1只能有一个区有数据,另外一个是空的。
接着上面的GC来说,比如一开始只有Eden区和From中有对象,To中是空的。 此时进行一次GC操作,From区中对象的年龄就会+1,我们知道Eden区中所有存活的对象会被复制到To区,
From区中还能存活的对象会有两个去处。
若对象年龄达到之前设置好的年龄阈值,此时对象会被移动到Old区,EdenFrom没有达到阈值的 对象会被复制到To区。 此时Eden区和From区已经被清空(被GC的对象肯定没了,没有被GC的对象都有了各自的去处)。
这时候From和To交换角色,之前的From变成了To,之前的To变成了From。 也就是说无论如何都要保证名为To的Survivor区域是空的。
Minor GC会一直重复这样的过程,直到To区被填满,然后会将所有对象复制到老年代中。
3.4 Old区详解
从上面的分析可以看出,一般Old区都是年龄比较大的对象,或者相对超过了某个阈值的对象。
在Old区也会有GC的操作,Old区的GC我们称作为Major GC。
3.5 对象的一辈子理解
我是一个普通的Java对象,我出生在Eden区,在Eden区我还看到和我长的很像的小兄弟,我们在Eden区中玩了挺长时间。有 一天Eden区中的人实在是太多了,我就被迫去了Survivor区的“From”区,自从去了Survivor区,我就开始漂了,有时候在 Survivor的“From”区,有时候在Survivor的“To”区,居无定所。直到我18岁的时候,爸爸说我成人了,该去社会上闯闯了。于是我就去了年老代那边,年老代里,人很多,并且年龄都挺大的,我在这里也认识了很多人。在年老代里,我生活了20年(每次 GC加一岁),然后被回收。

3.6 常见问题
- 如何理解Minor/Major/Full GC
Minor GC:新生代
Major GC:老年代
Full GC:新生代+老年代
- 为什么需要Survivor区?只有Eden不行吗?
如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。 这样一来,老年代很快被填满,触发Major GC(因为Major GC一般伴随着Minor GC,也可以看做触发了Full GC)。 老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多。执行时间长有什么坏处?频发的Full GC消耗的时间很长,会影响大型程序的执行和响应速度。
可能你会说,那就对老年代的空间进行增加或者较少咯。假如增加老年代空间,更多存活对象才能填满老年代。虽然降低Full GC频率,但是随着老年代空间加大,一旦发生Full GC,执行所需要的时间更长。
假如减少老年代空间,虽然Full GC所需时间减少,但是老年代很快被存活对象填满,Full GC频率增加。
所以Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16 次Minor GC还能在新生代中存活的对象,才会被送到老年代。
- 为什么需要两个Survivor区?
最大的好处就是解决了碎片化。也就是说为什么一个Survivor区不行?第一部分中,我们知道了必须设置Survivor区。假设,现在只有一个Survivor区,我们来模拟一下流程:
刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的,存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
永远有一个Survivor space是空的,另一个非空的Survivor space无碎片。
- 新生代中Eden:S1:S2为什么是8:1:1?
新生代中的可用内存:复制算法用来担保的内存为9:1
可用内存中Eden:S1区为8:1
即新生代中Eden:S1:S2 = 8:1:1
4、验证
4.1 堆内存溢出
程序:
@RestController
public class HeapController {
List<Person> list=new ArrayList<Person>();
@GetMapping("/heap")
public String heap() throws Exception{
while(true){
list.add(new Person());
Thread.sleep(1);
}
}
}
记得设置参数比如-Xmx20M -Xms20M
运行结果:
Exception in thread "http-nio-8080-exec-2" java.lang.OutOfMemoryError: GC overhead limit exceeded
4.2 方法区内存溢出
比如向方法区中添加Class的信息
4.2.1 asm依赖和Class代码
<dependency>
<groupId>asm</groupId>
<artifactId>asm</artifactId>
<version>3.3.1</version>
</dependency>
public class MyMetaspace extends ClassLoader {
public static List<Class<?>> createClasses() {
List<Class<?>> classes = new ArrayList<Class<?>>();
for (int i = 0; i < 10000000; ++i) {
ClassWriter cw = new ClassWriter(0);
cw.visit(Opcodes.V1_1, Opcodes.ACC_PUBLIC, "Class" + i, null,
"java/lang/Object", null);
MethodVisitor mw = cw.visitMethod(Opcodes.ACC_PUBLIC, "<init>",
"()V", null, null);
mw.visitVarInsn(Opcodes.ALOAD, 0); mw.visitMethodInsn(Opcodes.INVOKESPECIAL, "java/lang/Object",
"<init>", "()V"); mw.visitInsn(Opcodes.RETURN);
mw.visitMaxs(1, 1);
mw.visitEnd();
Metaspace test = new Metaspace();
byte[] code = cw.toByteArray();
Class<?> exampleClass = test.defineClass("Class" + i, code, 0, code.length);
classes.add(exampleClass);
}
return classes;
}
}
4.2.2 代码
@RestController
public class NonHeapController {
List<Class<?>> list=new ArrayList<Class<?>>();
@GetMapping("/nonheap")
public String nonheap() throws Exception{
while(true){
list.addAll(MyMetaspace.createClasses());
Thread.sleep(5);
}
}
}
设置Metaspace的大小,比如-XX:MetaspaceSize=50M -XX:MaxMetaspaceSize=50M
运行结果:
java.lang.OutOfMemoryError: Metaspace at java.lang.ClassLoader.defineClass1(Native Method) ~[na:1.8.0_191] at java.lang.ClassLoader.defineClass(ClassLoader.java:763) ~[na:1.8.0_191]
4.3 虚拟机栈
4.3.1 代码演示StackOverFlow
public class StackDemo {
public static long count=0;
public static void method(long i){
System.out.println(count++);
method(i);
}
public static void main(String[] args) {
method(1);
}
}
运行结果:

4.3.2 理解和说明
Stack Space用来做方法的递归调用时压入Stack Frame(栈帧)。所以当递归调用太深的时候,就有可能耗尽Stack Space,爆出StackOverflow的错误。
-Xss128k:设置每个线程的堆栈大小。JDK 5以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
线程栈的大小是个双刃剑,如果设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大,如果该值设置过大,就有影响到创建栈的数量,如果是多线程的应用,就会出现内存溢出的错误。
到此这篇关于深入了解Java虚拟机栈以及内存模型的文章就介绍到这了,更多相关java虚拟机栈和内存模型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java 内存溢出的原因和解决方法
你是否遇到过Java应用程序卡顿或突然崩溃的情况?您可能遇到过Java内存泄漏.在本文中,我们将深入研究Java内存泄漏的确切原因,并推荐一些最好的工具来防止内存泄漏发生. 什么是JAVA内存泄漏? 简单地说,Java内存泄漏是指对象不再被应用程序使用,而是在工作内存中处于活动状态. 在Java和大多数其他编程语言中,垃圾收集器的任务是删除不再被应用程序引用的对象.如果不选中,这些对象将继续消耗系统内存,并最终导致崩溃.有时java内存泄漏崩溃不会输出错误,但通常错误会以java.lang.Ou
-
Java DWR内存泄漏问题解决方案
机器跑了一晚上,发现有崩溃现象,由于页面内有动态绘图功能,我怀疑是绘图原因,但是今天上午有人提醒我才想到,是不是间隔调用时DWR产生了内存泄漏问题? 网上查了一下貌似大家都在讨论这个问题,之前我也挺老手说过DWR有内存问题,可是没有遇到过.原来DWR在间隔调用这种情况下会有问题! 按照大家的说法,修改engine.js配置文件来解决问题,目前我也修改了一下,修改方法如下: 在 dwr.engine._sendData = function(batch) {} 内有,这样几行代码: // Get
-
java应用占用内存过高排查的解决方案
故障:收到服务器报警,内存使用率超过80% 1.查看 使用dstat和top查看内存使用最高的应用 使用dstat 查到内存占用最高的是java应用,使用2253M内存,但是这台服务器跑了好几个java,具体哪个进程使用top看下资源情况 使用top 可以看到java应用整体内存使用率超过了70%,其中pid为16494的进程 一个应用占了28.7的内存 2.定位线程问题 使用ps查看16494的线程情况 命令:ps p 16494 -L -o pcpu,pmem,pid,tid,time,tn
-
排查Java应用内存泄漏问题的步骤
什么是内存泄漏 内存泄漏是指java应用的堆内存使用率持续升高,直至内存溢出. 内存泄漏的的原因可能有多种 分配给应用程序的内存本身过小.而应用的业务代码,确实需要生成大量的对象 代码bug,某些需要被回收的对象,由于代码bug,却持续的被引用,导致java虚拟机无法回收这些对象.从而撑爆内存 无论哪种内存泄露,我们的解决方法都是要定位到具体是什么对象,占用了大量内存,从而方便我们基于此进行代码分析,debug,找出代码问题. 而能够帮助我们实现这一目的的方式就是获取java应用的内存 dump
-
Java内存释放实现代码案例
先贴代码: StringBuilder dada = null; for(int i=0; i<1000; i++){ dada = new StringBuilder(); for(int j=0; j<1000; j++){ dada.append("FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF"); } } System.out.println("释放前"); StringBuilder dad
-
快速定位Java 内存OOM的问题
Java服务出现了OOM(Out Of Memory)问题,总结了一些相对通用的方案,希望能帮助到Java技术栈的同学. 某Java服务(假设PID=10765)出现了OOM,最常见的原因为: 有可能是内存分配确实过小,而正常业务使用了大量内存 某一个对象被频繁申请,却没有释放,内存不断泄漏,导致内存耗尽 某一个资源被频繁申请,系统资源耗尽,例如:不断创建线程,不断发起网络连接 画外音:无非"本身资源不够""申请资源太多""资源耗尽"几个原因.
-
Java虚拟机使用jvisualvm工具远程监控tomcat内存
jdk中自带了很多工具可以用于性能分析,位于jdk的bin目录下,jvisualvm工具可以以图形化的方式更加直观的监控本地以及远程的java进程的内存占用,线程状态等信息. 一.配置tomcat 在tomcat的catalina.sh文件开头加上如下配置: JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.ssl=fa
-
windows java.exe内存暴涨解决、idea跑java\ tomcat内存无限增长
最近突然遇到个问题:用 idea 跑 Tomcat 服务,不到30分钟 内存就吃完了.用任务管理器查看,发现 java.exe占了10G内存!! 查了各种方法 一. idea Tomcat 配置 没用!!! 二.idea idea64.exe.vmoptions 安装目录下的 bin 下的 idea64.exe.vmoptions 配置,还是 C:\Users\Administrator\.IntelliJIdea2019.1\config 下的 idea64.exe.vmoptions 配置
-
Java程序执行过程及内存机制详解
本讲将介绍Java代码是如何一步步运行起来的,其中涉及的编译器,类加载器,字节码校验器,解释器和JIT编译器在整个过程中是发挥着怎样的作用.此外还会介绍Java程序所占用的内存是被如何管理的:堆.栈和方法区都各自负责存储哪些内容.最后用一小块代码示例来帮助理解Java程序运行时内存的变化. Java程序执行过程 步骤 1: 写源代码,源代码将以.java的文件格式保存在电脑硬盘中. 步骤 2: 编译器(compiler)检查是否存在编译期错误(例如缺少分号,关键字拼写错误等).若通过检测,编译器
-
java各种类型对象占用内存情况分析
前言 其实一般的程序猿根本不用了解这么深,只有当你到了一定层次,需要了解jvm内部运行机制,或者高并发多线程下,你写的代码对内存有影响,你想做性能优化.等等等等,一句话,当你想深入了解java对象在内存中,如何存储,或者每个对象占用多大空间时,你会感谢这篇文章 本文主要分析jvm中的情况,实验环境为64位window10系统.JDK1.8,使用JProfiler进行结论验证 很多描述以及 概念是基于你懂基本java知识的,如果你看起来有点吃力,要加油咯 本片更偏重验证,更多理论,请参考:http
-
JAVA内存模型和Happens-Before规则知识点讲解
我们在本篇内容里聊一聊JAVA的内存模型和Happens-Before规则. JAVA内存模型 这里的JAVA内存模型指的不是我们JVM专栏中提到的内存分布模型,而是针对并发编程的,小伙伴们不要混淆概念了. 我们已经知道,导致可见性问题的是缓存,导致有序性问题的是指令重排,那么禁用缓存和禁用指令重排不就可以避免出现这两种问题了吗. 但想想也知道,如果直接禁用掉,性能会大打折扣,所以正确的方式应该是按需禁用. 只有程序员才能分析出什么时候应该禁用,所以为了解决可见性和有序性,其实只要提供给程序员按
-
浅析JAVA中的内存结构、重载、this与继承
一.对象在JVM的内存结构 JAVA内存管理由JVM来管理. 1)堆,所有new出来的对象(包括成员变量) 2)栈,所有局部变量(包括方法的参数) 3)方法区,class字节码文件(包括方法,静态数据) 1.引用变量指向null时,会发生空指针异常 public class student { int age; String name; public student(int age,String name){ this.age=age; this.name=name; } public stat
-
java 进程是如何在Linux服务器上进行内存分配的
众所周知,Java进程在启动的时候我们可以通过 -Xms 和-Xmx来设置内存的上限和下限.直到我发现使用top命令监控的Java进程在-Xms设置4g的情况下占用的内存并不是4g,这就产生了一个疑问Linux服务器的内存到底是如何进行分配的. 于是乎,我查阅了一些知乎,课程以及Linux相关的书籍.这里分享并记录的一下相关的知识. 在Linux上运行的进程不仅限于Java.都有一个概念,逻辑内存(Logic Memory),而物理机真是持有的内存,我们称为 物理内存(Physic Memory