Python文字截图识别OCR工具实例解析
一、简介
你一定用过那种“OCR神器”,可以把图片中的文字提取出来,极大的提高工作效率。
今天,我们就来做一款实时截图识别的小工具。顾名思义,运行程序时,可以实时把你截出来的图片中的文字识别出来。
二、模块
import keyboard # 用于监控键盘按下,触发事件(pip install keyboard) import time from aip import AipOcr # 调用百度接口(pip install baidu-aip) from PIL import ImageGrab # 用于保存屏幕截图
三、获取百度应用接口
AI开放平台文档中心
查看python语言的SDK文档
点击右上角(控制台),登录自己的百度账号,创建“文字识别”的应用
四、代码实现
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
# Author : MaYi
# Blog : http://www.cnblogs.com/mayi0312/
# Date : 2020-03-02
# Name : test_ocr
# Software : PyCharm
# Note : 用Python开发截图识别OCR小工具
import keyboard # 用于监控键盘按下,触发事件(pip install keyboard)
import time
from aip import AipOcr # 调用百度接口(pip install baidu-aip)
from PIL import ImageGrab # 用于保存屏幕截图
# 百度识别接口配置信息
APP_ID = '你的App ID'
API_KEY = '你的API Key'
SECRET_KEY = '你的Secret Key'
while True:
# 1、利用QQ截图到剪贴板
# 输入键盘的触发事件
keyboard.wait(hotkey="ctrl+alt+a")
keyboard.wait(hotkey="enter")
time.sleep(0.1)
# 2、保存截图
image = ImageGrab.grabclipboard()
image.save("screen.png")
# 3、利用百度API识别截图中的文字
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
with open("screen.png", 'rb') as f:
image = f.read()
# 调用百度API通用文字识别(高精度版),提取图片中的内容
text = client.basicAccurate(image)
result = text["words_result"]
for i in result:
print(i["words"])
# 我是分隔线
print("-" * 50)
运行结果预览:
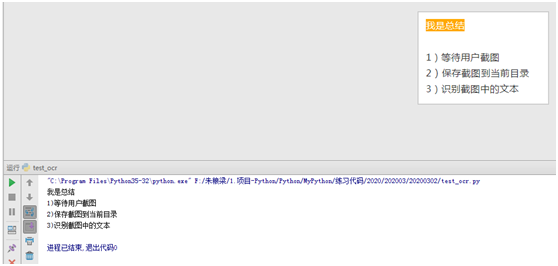
五、总结
1)等待用户截图
2)保存截图到当前目录
3)识别截图中的文本
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
win10安装tesserocr配置 Python使用tesserocr识别字母数字验证码
链接:https://pan.baidu.com/s/1l2yiba7ZTPUTf41ZnJ4PYw 提取码:t3bq win10安装tesserocr 首先需要下载tesseract,它为tesserocr提供底层支持.具体下载官方路径:https://github.com/UB-Mannheim/tesseract/wiki,选择对应的系统版本,可以选择一个相对不带dev的稳定版本下载,如:tesseract-ocr-setup-3.05.02-20180621.exe.然后一路安装,唯一记
-
初探利用Python进行图文识别(OCR)
话说什么是OCR????? 简介 OCR技术是光学字符识别的缩写(Optical Character Recognition),是通过扫描等光学输入方式将各种票据.报刊.书籍.文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术.可应用于银行票据.大量文字资料.档案卷宗.文案的录入和处理领域.适合于银行.税务等行业大量票据表格的自动扫描识别及长期存储.相对一般文本,通常以最终识别率.识别速度.版面理解正确率及版面还原满意度4个方面作为OCR技术的评测依
-
如何使用Python进行OCR识别图片中的文字
朋友需要一个工具,将图片中的文字提取出来.我帮他在网上找了一些OCR的应用,都不好用.所以准备自己研究,写一个Web APP供他使用. OCR1,全称Optical character recognition,或者optical character reader,中文译名叫做光学文字识别.它是把图像文件中的手写文本,打印文本转换为机器编码文本的一种方法. OCR技术广泛用于识别打印纸张中的文字数据 -- 比如护照,支票,银行声明,收据,统计表单,邮件等.OCR的早期版本,需要对图片中的每个文字都
-

Python3实现腾讯云OCR识别
废话不多说,在网上找了下腾讯云OCR识别的,示例不多,用Python的还是Python2.7,花了点时间改成Python3的. 先上图,腾讯自己的示例图: 下面是代码: import requests import hmac import hashlib import base64 import time import random import re appid = "你自己的appid" bucket = " 这个是优图上面的,可以不填" #参考本文开头提供的链
-
python实现百度OCR图片识别过程解析
这篇文章主要介绍了python实现百度OCR图片识别过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 import base64 import requests class CodeDemo: def __init__(self,AK,SK,code_url,img_path): self.AK=AK self.SK=SK self.code_url=code_url self.img_path=img_path self.ac
-
Python3使用腾讯云文字识别(腾讯OCR)提取图片中的文字内容实例详解
百度OCR体验地址: https://ai.baidu.com/tech/imagerecognition/general 腾讯OCR体验地址: https://cloud.tencent.com/act/event/ocrdemo 测试结果是:腾讯的效果要比百度的好 腾讯云目前额度是: 每个接口 1,000次/月免费,有6个文字识别的接口,一共是6,000次/月 百度接口调用之前写过文章 python实现百度OCR图片识别过程解析 使用步骤 1.注册账号: https://cloud.tenc
-
详解Python安装tesserocr遇到的各种问题及解决办法
Tesseract的安装及配置 在Python爬虫过程中,难免遇到各种各样的验证码问题,最简单的就是这种验证码了,那么在遇到验证码的时候该怎么办呢?我们就需要OCR技术了,OCR-即Optical Character Recognition光学字符识别,是指通过扫描字符,然后将其形状翻译成电子文本的过程.而tesserocr是Python的一个OCR识别库,所以在安装tesserocr之前,我们需要安装tesseract这个东西 下载地址:https://digi.bib.uni-mannhe
-
python3光学字符识别模块tesserocr与pytesseract的使用详解
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程,对应图形验证码来说,它们都是一些不规则的字符,这些字符是由字符稍加扭曲变换得到的内容,我们可以使用OCR技术来讲其转化为电子文本,然后将结果提取交给服务器,便可以达到自动识别验证码的过程 tesserocr与pytesseract是Python的一个OCR识别库,但其实是对tesseract做的一层Python API封装,pytesseract是Goog
-
Python文字截图识别OCR工具实例解析
一.简介 你一定用过那种"OCR神器",可以把图片中的文字提取出来,极大的提高工作效率. 今天,我们就来做一款实时截图识别的小工具.顾名思义,运行程序时,可以实时把你截出来的图片中的文字识别出来. 二.模块 import keyboard # 用于监控键盘按下,触发事件(pip install keyboard) import time from aip import AipOcr # 调用百度接口(pip install baidu-aip) from PIL import Imag
-
基于Python实现图像文字识别OCR工具
目录 引言 功能列表 OCR部分 界面部分 软件代码 参考链接 引言 最近在技术交流群里聊到一个关于图像文字识别的需求,在工作.生活中常常会用到,比如票据.漫画.扫描件.照片的文本提取. 博主基于 PyQt + PaddleOCR 写了一个桌面端的OCR工具,用于快速实现图片中文本区域自动检测+文本自动识别. 识别效果如下图所示: 所有框选区域为OCR算法自动检测,右侧列表有每个框对应的文字内容: 点击右侧"识别结果"中的文本记录,然后点击"复制到剪贴板"即可复制该
-
Python用imghdr模块识别图片格式实例解析
imghdr模块 功能描述:imghdr模块用于识别图片的格式.它通过检测文件的前几个字节,从而判断图片的格式. 唯一一个API imghdr.what(file, h=None) 第一个参数file可以是用rb模式打开的file对象或者表示路径的字符串和PathLike对象.h参数是一段字节串.函数返回表示图片格式的字符串. >>> import imghdr >>> imghdr.what('test.jpg') 'jpeg' 具体的返回值和描述如下: 返回值 描述
-
python cv2在验证码识别中应用实例解析
这篇文章主要介绍了python cv2在验证码识别中应用实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用函数cv2.imread(filepath,flags)读入一副图片 filepath:要读入图片的完整路径 flags:读入图片的标志 cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道 cv2.IMREAD_GRAYSCALE:读入灰度图片 cv2.IMREAD_UNCHANGED:顾名思义,读入
-
Python通用验证码识别OCR库之ddddocr验证码识别
目录 前言 传统验证码 滑动验证码 文字点选验证码 总结 前言 相信做自动化测试的同学一定不可忽视的问题就是验证码,他几乎是一个网站登录的标配,当然,我一般是不建议在这上面浪费时间去做识别的. 举个例子,现在你的目的是进入自己家的房子,房子为了防止小偷进入于是上了一把锁.我们没必要花费力气去研究开锁技术.去找锁匠配置一把万能钥匙(让开发设置验证码的万能码),或者干脆先去上锁匠把验证码去掉(让开发暂时屏蔽验证码).严格来说识别验证码不是我们自动化测试的重点.除非你是验证码厂商的员工,破解识别验证码
-
Python通用验证码识别OCR库ddddocr的安装使用教程
目录 前言 一.安装ddddocr 二.使用ddddocr 1. 使用举例 2. 完整代码 3. 验证码样例 4. 识别结果 三.代码说明 总结 前言 在使用自动化登录网站的时候,经常输入用户名和密码后会遇到验证码.今天介绍一款通用验证码识别 OCR库,对验证码识别彻底说拜拜,它的名字是 ddddocr(带带弟弟 OCR ).这里主要以字母数字类验证码进行说明. 项目地址:https://github.com/sml2h3/ddddocr 一.安装ddddocr 通过命令将自动安装符合自己电脑环
-
Python建立Map写Excel表实例解析
本文主要研究的是用Python语言建立Map写Excel表的相关代码,具体如下. 前言:我们已经能够很熟练的写Excel表相关的脚本了.大致的操作就是,从数据库中取数据,建立Excel模板,然后根据模板建立一个新的Excel表,把数据库中的数据写入.最后发送邮件.之前的一篇记录博客,写的很标准了.这里我们说点遇到的新问题. 我们之前写类似脚本的时候,有个问题没有考虑过,为什么要建立模板然后再写入数据呢?诶-其实也不算是没考虑过,只是懒没有深究罢了.只求快点完成任务... 这里对这个问题进行思考阐
-
Python多线程threading和multiprocessing模块实例解析
本文研究的主要是Python多线程threading和multiprocessing模块的相关内容,具体介绍如下. 线程是一个进程的实体,是由表示程序运行状态的寄存器(如程序计数器.栈指针)以及堆栈组成,它是比进程更小的单位. 线程是程序中的一个执行流.一个执行流是由CPU运行程序代码并操作程序的数据所形成的.因此,线程被认为是以CPU为主体的行为. 线程不包含进程地址空间中的代码和数据,线程是计算过程在某一时刻的状态.所以,系统在产生一个线程或各个线程之间切换时,负担要比进程小得多. 线程是一
-
python使用json序列化datetime类型实例解析
使用python的json模块序列化时间或者其他不支持的类型时会抛异常,例如下面的代码: # -*- coding: cp936 -*- from datetime import datetime import json if __name__=='__main__': now = datetime.now() json.dumps({'now':now}) 运行会出现下面的错误信息: Traceback (most recent call last): File "C:\Users\xx\De
-
python删除过期log文件操作实例解析
本文研究的主要是python删除过期log文件的相关内容,具体介绍如下. 1. 用Python遍历目录 os.walk方法可以很方便的得到目录下的所有文件,会返回一个三元的tupple(dirpath, dirnames, filenames),其中,dirpath是代表目录的路径,dirnames是一个list,包含了dirpath下的所有子目录的名字,filenames是一个list,包含了非目录的文件,如果需要得到全路径,需要使用os.path.join(dirpath,name).例如t