基于RocketMQ推拉模式详解
消费者客户端有两种方式从消息中间件获取消息并消费。严格意义上来讲,RocketMQ并没有实现PUSH模式,而是对拉模式进行一层包装,名字虽然是 Push 开头,实际在实现时,使用 Pull 方式实现。
通过 Pull 不断轮询 Broker 获取消息。当不存在新消息时,Broker 会挂起请求,直到有新消息产生,取消挂起,返回新消息。
1、概述
1.1、PULL方式
由消费者客户端主动向消息中间件(MQ消息服务器代理)拉取消息;采用Pull方式,如何设置Pull消息的拉取频率需要重点去考虑,举个例子来说,可能1分钟内连续来了1000条消息,然后2小时内没有新消息产生(概括起来说就是“消息延迟与忙等待”)。
如果每次Pull的时间间隔比较久,会增加消息的延迟,即消息到达消费者的时间加长,MQ中消息的堆积量变大;若每次Pull的时间间隔较短,但是在一段时间内MQ中并没有任何消息可以消费,那么会产生很多无效的Pull请求的RPC开销,影响MQ整体的网络性能;
1.2、PUSH方式
由消息中间件(MQ消息服务器代理)主动地将消息推送给消费者;采用Push方式,可以尽可能实时地将消息发送给消费者进行消费。
但是,在消费者的处理消息的能力较弱的时候(比如,消费者端的业务系统处理一条消息的流程比较复杂,其中的调用链路比较多导致消费时间比较久。
概括起来地说就是“慢消费问题”),而MQ不断地向消费者Push消息,消费者端的缓冲区可能会溢出,导致异常;
2、PUSH模式
主动推送的模式实现起来简单,避免了拉取的消费端业务逻辑的复杂度,消息的消费可以认为是实时的,同时也存在一定的弊端,要求消费端要有很强的消费能力。
2.1、代码实现
public class Consumer1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_push");
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
SimpleDateFormat sd = new SimpleDateFormat("YYYY-MM-dd HH:mm:ss");
Date date = new Date(msg.getStoreTimestamp());
System.out.println("Consumer1=== 存入时间 : "+ sd.format(date) +" == MessageBody: "+ msgbody);//输出消息内容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再试
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消费成功
}
});
consumer.start();
System.out.println("Consumer1===启动成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
PUSH消费方式,需要注册一个监听器Listener,,用来监听最新的消息,进行业务处理,同时反馈消息的消费状态,消费成功(CONSUME_SUCCESS)、消费重试(RECONSUME_LATER),消息重试会根据配置的消息的延迟等级的时间间隔,定时重新发送消费失败的记录。(PS:延迟消息中会重点讨论)
PUSH消息方式由于返回了消息的状态,服务端会维护每个消费端的消费进度,内部会记录消费进度,消息发送成功后会更新消费进度。
PUSH消息方式的局限性,是在HOLD住Consumer请求的时候需要占用资源,它适合用在消息队列这种客户端连接数可控的场景中。
上一个章节说明了服务端存储的每个主题对应的消费组的每个消息队列的偏移量
查看服务器文件上的消费进度信息:
/usr/local/rocketmq-all-4.2.0/store/config/consumerOffset.json

3、PULL模式
3.1、代码实现(1)
public class PullConsumer {
private static final Map<MessageQueue, Long> offseTable = new HashMap<MessageQueue, Long>();
public static void main(String[] args) throws MQClientException {
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("pullConsumer");
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.start();
Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("TopicTest");
for (MessageQueue mq : mqs) {
SINGLE_MQ: while (true) {
try {
PullResult pullResult =
consumer.pullBlockIfNotFound(mq, null, getMessageQueueOffset(mq), 32);
System.out.println("=============================================================");
System.out.println("Consume from the queue: " + mq + "offset:" + getMessageQueueOffset(mq) + "结果:" + pullResult.getPullStatus());
putMessageQueueOffset(mq, pullResult.getNextBeginOffset());
switch (pullResult.getPullStatus()) {
case FOUND:
List<MessageExt> messageExtList = pullResult.getMsgFoundList();
for (MessageExt m : messageExtList) {
System.out.print(new String(m.getBody()) +" == ");
}
System.out.println("");
case NO_MATCHED_MSG:
break;
case NO_NEW_MSG:
break SINGLE_MQ;
case OFFSET_ILLEGAL:
break;
default:
break;
}
}
catch (Exception e) {
e.printStackTrace();
}
}
}
consumer.shutdown();
}
private static void putMessageQueueOffset(MessageQueue mq, long offset) {
offseTable.put(mq, offset);
}
private static long getMessageQueueOffset(MessageQueue mq) {
Long offset = offseTable.get(mq);
if (offset != null)
return offset;
return 0;
}
}
结果:
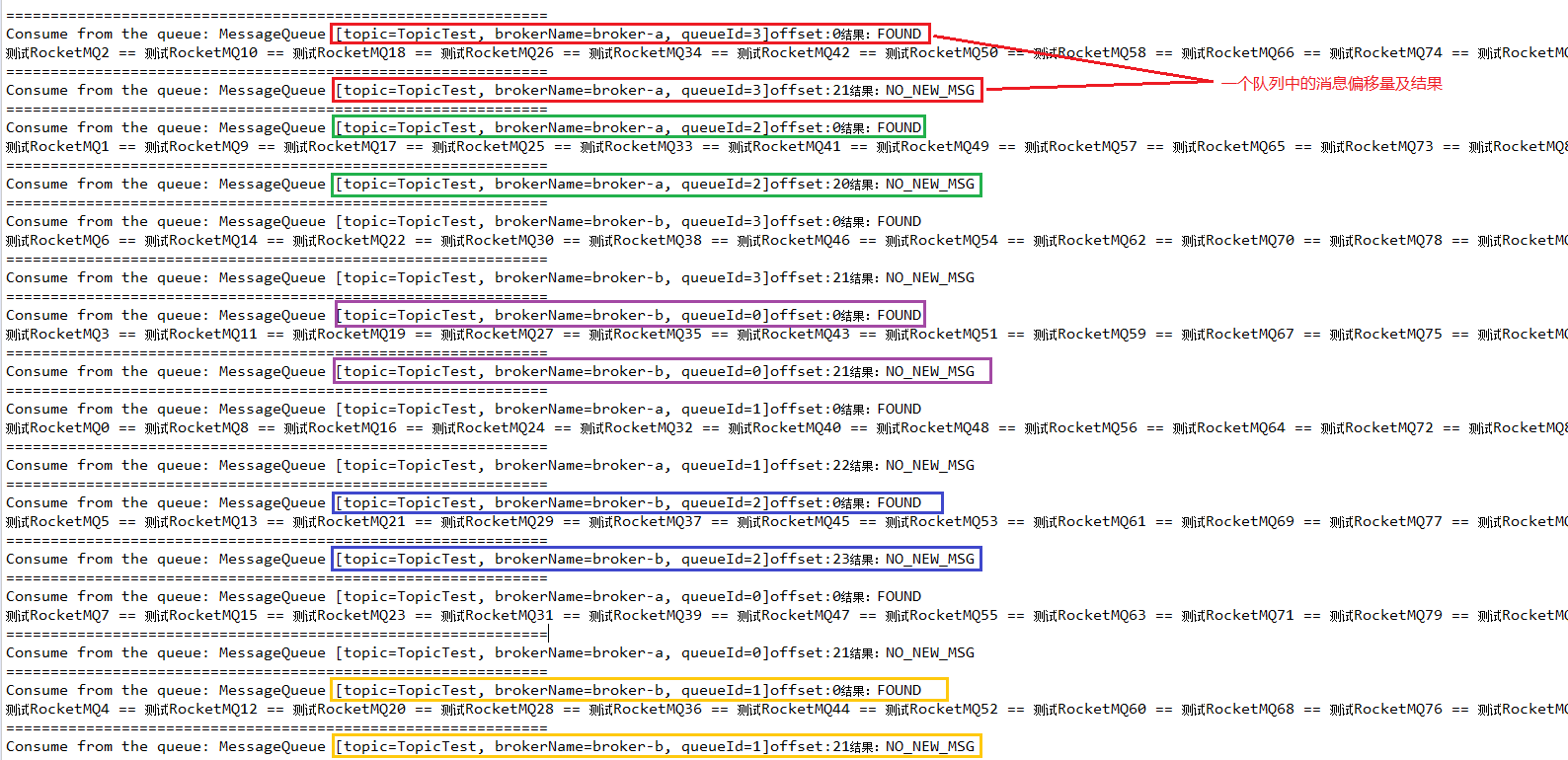
每次拉取消息的时候需要提供偏移量和拉取的消息的个数,需要自己业务实现每个主题下的队列的消费进度。
代码实现(1)这种方式只能拉取历史的消息,最新的消息拉取不了,也可以进行改造,来实现一直拉取。
3.2、代码实现(2)
在MQPullConsumer这个类里面,有一个MessageQueueListener,它的目的就是当queue发生变化的时候,通知Consumer。也正是这个借口,帮助我们在Pull模式里面,实现负载均衡。
注意,这个接口在MQPushConsumer里面是没有的,那里面有的是上面代码里的MessageListener。
void registerMessageQueueListener(final String topic, final MessageQueueListener listener);
public interface MessageQueueListener {
void messageQueueChanged(final String topic, final Set<MessageQueue> mqAll,
final Set<MessageQueue> mqDivided);
}
有了这个Listener,我们就可以动态的知道当前的Consumer分摊到了几个MessageQueue。然后对这些MessageQueue,我们可以开个线程池来消费。
public class PullConsumerExtend {
public static void main(String[] args) throws MQClientException {
//消费组
final MQPullConsumerScheduleService scheduleService = new MQPullConsumerScheduleService("pullConsumer");
//MQ NameService地址
scheduleService.getDefaultMQPullConsumer().setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
//负载均衡模式
scheduleService.setMessageModel(MessageModel.CLUSTERING);
//需要处理的消息topic
scheduleService.registerPullTaskCallback("TopicTest", new PullTaskCallback() {
@Override
public void doPullTask(MessageQueue mq, PullTaskContext context) {
MQPullConsumer consumer = context.getPullConsumer();
try {
long offset = consumer.fetchConsumeOffset(mq, false);
if (offset < 0)
offset = 0;
PullResult pullResult = consumer.pull(mq, "*", offset, 32);
System.out.println("");
System.out.println("Consume from the queue: " + mq + "offset:" + offset + "结果:" + pullResult.getPullStatus());
switch (pullResult.getPullStatus()) {
case FOUND:
List<MessageExt> messageExtList = pullResult.getMsgFoundList();
for (MessageExt m : messageExtList) {
System.out.print(new String(m.getBody()) +" == ");
}
break;
case NO_MATCHED_MSG:
break;
case NO_NEW_MSG:
case OFFSET_ILLEGAL:
break;
default:
break;
}
consumer.updateConsumeOffset(mq, pullResult.getNextBeginOffset());
//设置下一下拉取的间隔时间
context.setPullNextDelayTimeMillis(10000);
} catch (Exception e) {
e.printStackTrace();
}
}
});
scheduleService.start();
}
}
结果:

比较**代码实现(1)**这种方式改进了很多,不需要业务维护每个消费队列的消费进度,可以更新到服务端的。
弊端也很明显就是每次队列拉取消息的时间间隔,时间长导致消息挤压,时间段消息少,影响服务端性能。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

基于rocketmq的有序消费模式和并发消费模式的区别说明
rocketmq消费者注册监听有两种模式 有序消费MessageListenerOrderly和并发消费MessageListenerConcurrently,这两种模式返回值不同. MessageListenerOrderly 正确消费返回 ConsumeOrderlyStatus.SUCCESS 稍后消费返回 ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT MessageListenerConcurrently 正确消费返回 Consu
-
RocketMQ消息过滤与查询的实现
消息过滤 RocketMQ分布式消息队列的消息过滤方式有别于其它MQ中间件,是在Consumer端订阅消息时再做消息过滤的. RocketMQ这么做是还是在于其Producer端写入消息和Consomer端订阅消息采用分离存储的机制来实现的,Consumer端订阅消息是需要通过ConsumeQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,所以说到底也是还绕不开其存储结构. 其ConsumeQueue的存储结构如下,可以看到其中有8个字节存储的M
-
使用RocketMQTemplate发送带tags的消息
RocketMQTemplate发送带tags的消息 RocketMQTemplate是RocketMQ集成到Spring cloud之后提供的个方便发送消息的模板类,它是基本Spring 的消息机制实现的,对外只提供了Spring抽象出来的消息发送接口. 在单独使用RocketMQ的时候,发送消息使用的Message是'org.apache.rocketmq.common.message'包下面的Message,而使用RocketMQTemplate发送消息时,使用的Message是org.s
-
解决SpringBoot整合RocketMQ遇到的坑
应用场景 在实现RocketMQ消费时,一般会用到@RocketMQMessageListener注解定义Group.Topic以及selectorExpression(数据过滤.选择的规则)为了能支持动态筛选数据,一般都会使用表达式,然后通过apollo或者cloud config进行动态切换. 引入依赖 <!-- RocketMq Spring Boot Starter--> <dependency> <groupId>org.apache.rocketmq<
-
RocketMQTemplate 注入失败的解决
RocketMQTemplate 注入失败 在使用rocketmq 发送消息时,会发现 @Autowired private RocketMQTemplate rocketMQTemplate; 注入RocketMQTemplate 失败. 解决方案 究其原因是因为,配置文件中,我们没有添加 上图中蓝色的两行代码,指定发送的组名.写上后,问题解决. 好了,再来说说RocketMQTemplate 的基本使用吧~ RocketMQTemplate的使用 1.pom.xml依赖 <dependenc
-
RocketMQ-延迟消息的处理流程介绍
概述 RocketMQ 支持发送延迟消息,但不支持任意时间的延迟消息的设置,仅支持内置预设值的延迟时间间隔的延迟消息: 预设值的延迟时间间隔为: 1s. 5s. 10s. 30s. 1m. 2m. 3m. 4m. 5m. 6m. 7m. 8m. 9m. 10m. 20m. 30m. 1h. 2h: 在消息创建的时候,调用 setDelayTimeLevel(int level) 方法设置延迟时间: broker在接收到延迟消息的时候会把对应延迟级别的消息先存储到对应的延迟队列中,等延迟消息时间到
-
RocketMQ 延时级别配置方式
RocketMQ 支持定时消息,但是不支持任意时间精度,仅支持特定的 level,例如定时 5s, 10s, 1m 等. 其中,level=0 级表示不延时,level=1 表示 1 级延时,level=2 表示 2 级延时,以此类推. 如何配置: 在服务器端(rocketmq-broker端)的属性配置文件中加入以下行: messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h 描述了各级别与延时时
-
基于RocketMQ推拉模式详解
消费者客户端有两种方式从消息中间件获取消息并消费.严格意义上来讲,RocketMQ并没有实现PUSH模式,而是对拉模式进行一层包装,名字虽然是 Push 开头,实际在实现时,使用 Pull 方式实现. 通过 Pull 不断轮询 Broker 获取消息.当不存在新消息时,Broker 会挂起请求,直到有新消息产生,取消挂起,返回新消息. 1.概述 1.1.PULL方式 由消费者客户端主动向消息中间件(MQ消息服务器代理)拉取消息:采用Pull方式,如何设置Pull消息的拉取频率需要重点去考虑,举个
-
基于ROS 服务通信模式详解
ROS 服务通信模式 摘自<ROS机器人开发实践> 服务(services)是节点之间通讯的另一种方式.服务允许节点发送请求(request) 并获得一个响应(response) AddTwoInts.h文件是根据AddTwoInts.srv文件生成的 还会自动生成 AddTwoIntsRequest.h AddTwoIntsResponse.h AddTwoInts.h所在的目录是 \catkin_ws\devel AddTwoInts.srv int64 a int64 b --- int
-
基于RabbitMQ几种Exchange 模式详解
AMQP协议中的核心思想就是生产者和消费者隔离,生产者从不直接将消息发送给队列.生产者通常不知道是否一个消息会被发送到队列中,只是将消息发送到一个交换机.先由Exchange来接收,然后Exchange按照特定的策略转发到Queue进行存储.同理,消费者也是如此.Exchange 就类似于一个交换机,转发各个消息分发到相应的队列中. RabbitMQ提供了四种Exchange模式:fanout,direct,topic,header . header模式在实际使用中较少,本文只对前三种模式进行比
-
基于JavaScript表单脚本(详解)
什么是表单? 一个表单有三个基本组成部分: 表单标签:这里面包含了处理表单数据所用CGI程序的URL以及数据提交到服务器的方法. 表单域:包含了文本框.密码框.隐藏域.多行文本框.复选框.单选框.下拉选择框和文件上传框等. 表单按钮:包括提交按钮.复位按钮和一般按钮:用于将数据传送到服务器上的CGI脚本或者取消输入,还可以用表单按钮来控制其他定义了处理脚本的处理工作. JavaScript与表单间的关系:JS最初的应用就是用于分担服务器处理表单的责任,打破依赖服务器的局面,尽管目前web和jav
-
基于RabbitMQ的简单应用(详解)
虽然后台使用了读写分离技术,能够在一定程度上抗击高并发,但是如果并发量特别巨大时,主数据库不能同时处理高并发的请求,这时数据库容易宕机. 问题: 现在的问题是如何既能保证数据库正常运行,又能实现用户数据的入库操作? 解决方案: 引入rabbitMQ技术: 说明: 当数据库的访问压力过载时,这时会将过载以后的数据先保存到rabbitMQ中.其中的数据结构是队列的形式,先进先出.这时数据库从队列中取数据执行.一直到队列中的数据全部操作完成为止. RabbitMQ就是消息的中间件. RabbitMQ介
-
基于Jexus-5.6.3使用详解
一.Jexus Web Server配置 在 jexus 的工作文件夹中(一般是"/usr/jexus")有一个基本的配置文件,文件名是"jws.conf". jws.conf 中至少有 SiteConfigDir 和 SiteLogDir 两行信息: SiteConfigDir=siteconf #指的是存放网站配置文件放在siteconf这个文件夹中,可以使用基于jws.exe文件的相对路径 SiteLogDir=log #指的是jexus日志文件放在log这个
-
基于python图书馆管理系统设计实例详解
写完这个项目后,导师说这个你完全可以当作毕业项目使用了,写的很全,很多的都设计考虑周全,但我的脚步绝不止于现在,我想要的是星辰大海!与君共勉! 这个项目不是我的作业, 只是无意中被拉进来了,然后就承担了所有,肝了一周多,终于完成,但这个也算是一个很大的项目了吧,对于我现在来说,写这个项目遇到了很多困难,这是真的,其中涉及到数据库的使用,就遇到了一点瓶颈, 但这不算什么,还是要被我搞定的. 梦想就像这个远处夕阳,终究触手可及! Python项目: 项目前提: 这个项目涉及到的知识点有很多, 知识串
-
rabbitmq五种模式详解(含实现代码)
一.五种模式详解 1.简单模式(Queue模式) 当生产端发送消息到交换机,交换机根据消息属性发送到队列,消费者监听绑定队列实现消息的接收和消费逻辑编写.简单模式下,强调的一个队列queue只被一个消费者监听消费. 1.1 结构 生产者:生成消息,发送到交换机交换机:根据消息属性,将消息发送给队列消费者:监听这个队列,发现消息后,获取消息执行消费逻辑 1.2应用场景 常见的应用场景就是一发,一接的结构 例如: 手机短信邮件单发 2.争抢模式(Work模式) 强调的也是后端队列与消费者绑定的结构
-
Go语言中的数据竞争模式详解
目录 前言 Go在goroutine中通过引用来透明地捕获自由变量 切片会产生难以诊断的数据竞争 并发访问Go内置的.不安全的线程映射会导致频繁的数据竞争 Go开发人员常在pass-by-value时犯错并导致non-trivial的数据竞争 消息传递(通道)和共享内存的混合使用使代码变得复杂且易受数据竞争的影响 Add和Done方法的错误放置会导致数据竞争 并发运行测试会导致产品或测试代码中的数据竞争 小结 前言 本文主要基于在Uber的Go monorepo中发现的各种数据竞争模式,分析了其
-
JavaScript设计模式之中介者模式详解
目录 中介者模式 现实中的中介者 中介者模式的例子 泡泡堂游戏 为游戏增加队伍 玩家增多带来的困扰 用中介者模式改造泡泡堂游戏 小结 中介者模式 在我们生活的世界中,每个人每个物体之间都会产生一些错综复杂的联系.在应用程序里也是一样,程序由大大小小的单一对象组成,所有这些对象都按照某种关系和规则来通信. 平时我们大概能记住 10 个朋友的电话.30 家餐馆的位置.在程序里,也许一个对象会和其他 10 个对象打交道,所以它会保持 10 个对象的引用.当程序的规模增大,对象会越来越多,它们之间的关系