python实现交并比IOU教程
交并比(Intersection-over-Union,IoU),目标检测中使用的一个概念,是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值。最理想情况是完全重叠,即比值为1。

计算公式:
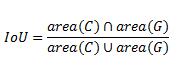
Python实现代码:
def cal_iou(box1, box2): """ :param box1: = [xmin1, ymin1, xmax1, ymax1] :param box2: = [xmin2, ymin2, xmax2, ymax2] :return: """ xmin1, ymin1, xmax1, ymax1 = box1 xmin2, ymin2, xmax2, ymax2 = box2 # 计算每个矩形的面积 s1 = (xmax1 - xmin1) * (ymax1 - ymin1) # C的面积 s2 = (xmax2 - xmin2) * (ymax2 - ymin2) # G的面积 # 计算相交矩形 xmin = max(xmin1, xmin2) ymin = max(ymin1, ymin2) xmax = min(xmax1, xmax2) ymax = min(ymax1, ymax2) w = max(0, xmax - xmin) h = max(0, ymax - ymin) area = w * h # C∩G的面积 iou = area / (s1 + s2 - area) return iou
# -*-coding: utf-8 -*- """ @Project: IOU @File : IOU.py @Author : panjq @E-mail : pan_jinquan@163.com @Date : 2018-10-14 10:44:06 """ def calIOU_V1(rec1, rec2): """ computing IoU :param rec1: (y0, x0, y1, x1), which reflects (top, left, bottom, right) :param rec2: (y0, x0, y1, x1) :return: scala value of IoU """ # 计算每个矩形的面积 S_rec1 = (rec1[2] - rec1[0]) * (rec1[3] - rec1[1]) S_rec2 = (rec2[2] - rec2[0]) * (rec2[3] - rec2[1]) # computing the sum_area sum_area = S_rec1 + S_rec2 # find the each edge of intersect rectangle left_line = max(rec1[1], rec2[1]) right_line = min(rec1[3], rec2[3]) top_line = max(rec1[0], rec2[0]) bottom_line = min(rec1[2], rec2[2]) # judge if there is an intersect if left_line >= right_line or top_line >= bottom_line: return 0 else: intersect = (right_line - left_line) * (bottom_line - top_line) return intersect/(sum_area - intersect) def calIOU_V2(rec1, rec2): """ computing IoU :param rec1: (y0, x0, y1, x1), which reflects (top, left, bottom, right) :param rec2: (y0, x0, y1, x1) :return: scala value of IoU """ # cx1 = rec1[0] # cy1 = rec1[1] # cx2 = rec1[2] # cy2 = rec1[3] # gx1 = rec2[0] # gy1 = rec2[1] # gx2 = rec2[2] # gy2 = rec2[3] cx1,cy1,cx2,cy2=rec1 gx1,gy1,gx2,gy2=rec2 # 计算每个矩形的面积 S_rec1 = (cx2 - cx1) * (cy2 - cy1) # C的面积 S_rec2 = (gx2 - gx1) * (gy2 - gy1) # G的面积 # 计算相交矩形 x1 = max(cx1, gx1) y1 = max(cy1, gy1) x2 = min(cx2, gx2) y2 = min(cy2, gy2) w = max(0, x2 - x1) h = max(0, y2 - y1) area = w * h # C∩G的面积 iou = area / (S_rec1 + S_rec2 - area) return iou if __name__=='__main__': rect1 = (661, 27, 679, 47) # (top, left, bottom, right) rect2 = (662, 27, 682, 47) iou1 = calIOU_V1(rect1, rect2) iou2 = calIOU_V2(rect1, rect2) print(iou1) print(iou2)
参考:https://www.jb51.net/article/184542.htm
补充知识:Python计算多分类的混淆矩阵,Precision、Recall、f1-score、mIOU等指标
直接上代码,一看很清楚
import os
import numpy as np
from glob import glob
from collections import Counter
def cal_confu_matrix(label, predict, class_num):
confu_list = []
for i in range(class_num):
c = Counter(predict[np.where(label == i)])
single_row = []
for j in range(class_num):
single_row.append(c[j])
confu_list.append(single_row)
return np.array(confu_list).astype(np.int32)
def metrics(confu_mat_total, save_path=None):
'''
:param confu_mat: 总的混淆矩阵
backgound:是否干掉背景
:return: txt写出混淆矩阵, precision,recall,IOU,f-score
'''
class_num = confu_mat_total.shape[0]
confu_mat = confu_mat_total.astype(np.float32) + 0.0001
col_sum = np.sum(confu_mat, axis=1) # 按行求和
raw_sum = np.sum(confu_mat, axis=0) # 每一列的数量
'''计算各类面积比,以求OA值'''
oa = 0
for i in range(class_num):
oa = oa + confu_mat[i, i]
oa = oa / confu_mat.sum()
'''Kappa'''
pe_fz = 0
for i in range(class_num):
pe_fz += col_sum[i] * raw_sum[i]
pe = pe_fz / (np.sum(confu_mat) * np.sum(confu_mat))
kappa = (oa - pe) / (1 - pe)
# 将混淆矩阵写入excel中
TP = [] # 识别中每类分类正确的个数
for i in range(class_num):
TP.append(confu_mat[i, i])
# 计算f1-score
TP = np.array(TP)
FN = col_sum - TP
FP = raw_sum - TP
# 计算并写出precision,recall, f1-score,f1-m以及mIOU
f1_m = []
iou_m = []
for i in range(class_num):
# 写出f1-score
f1 = TP[i] * 2 / (TP[i] * 2 + FP[i] + FN[i])
f1_m.append(f1)
iou = TP[i] / (TP[i] + FP[i] + FN[i])
iou_m.append(iou)
f1_m = np.array(f1_m)
iou_m = np.array(iou_m)
if save_path is not None:
with open(save_path + 'accuracy.txt', 'w') as f:
f.write('OA:\t%.4f\n' % (oa*100))
f.write('kappa:\t%.4f\n' % (kappa*100))
f.write('mf1-score:\t%.4f\n' % (np.mean(f1_m)*100))
f.write('mIou:\t%.4f\n' % (np.mean(iou_m)*100))
# 写出precision
f.write('precision:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(TP[i]/raw_sum[i])*100))
f.write('\n')
# 写出recall
f.write('recall:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(TP[i] / col_sum[i])*100))
f.write('\n')
# 写出f1-score
f.write('f1-score:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(f1_m[i])*100))
f.write('\n')
# 写出 IOU
f.write('Iou:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(iou_m[i])*100))
f.write('\n')
以上这篇python实现交并比IOU教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python计算二维矩形IOU实例
计算交并比:交的面积除以并的面积. 要求矩形框的长和宽应该平行于图片框.不然不能用这样的公式计算. 原理,从一维上来理解:两条红线的距离之和减去黑色线之间的距离就是相交的距离.两条红线之和很容易算,两条黑线之间的距离就是最小的起点到到最大的末点,最小的起点好算,最大的末点就是两点加上各自长度之后的最大值.这就算出了一维的情况,二维的情况一样,计算二次而已. def iou(rect1,rect2): ''' 计算两个矩形的交并比 :param rect1:第一个矩形框.表示为x,y,w,h,其中
-
python不使用for计算两组、多个矩形两两间的iou方式
解决问题: 不使用for计算两组.多个矩形两两间的iou 使用numpy广播的方法,在python程序中并不建议使用for语句,python中的for语句耗时较多,如果使用numpy广播的思想将会提速不少. 代码: def calc_iou(bbox1, bbox2): if not isinstance(bbox1, np.ndarray): bbox1 = np.array(bbox1) if not isinstance(bbox2, np.ndarray): bbox2 = np.arr
-
python:目标检测模型预测准确度计算方式(基于IoU)
训练完目标检测模型之后,需要评价其性能,在不同的阈值下的准确度是多少,有没有漏检,在这里基于IoU(Intersection over Union)来计算. 希望能提供一些思路,如果觉得有用欢迎赞我表扬我~ IoU的值可以理解为系统预测出来的框与原来图片中标记的框的重合程度.系统预测出来的框是利用目标检测模型对测试数据集进行识别得到的. 计算方法即检测结果DetectionResult与GroundTruth的交集比上它们的并集,如下图: 蓝色的框是:GroundTruth 黄色的框是:Dete
-
Python计算机视觉里的IOU计算实例
其中x1,y1;x2,y2分别表示两个矩形框的中心点 def calcIOU(x1, y1, w1, h1, x2, y2, w2, h2): if((abs(x1 - x2) < ((w1 + w2)/ 2.0)) and (abs(y1-y2) < ((h1 + h2)/2.0))): left = max((x1 - (w1 / 2.0)), (x2 - (w2 / 2.0))) upper = max((y1 - (h1 / 2.0)), (y2 - (h2 / 2.0))) righ
-
python实现的Iou与Giou代码
最近看了网上很多博主写的iou实现方法,但Giou的代码似乎比较少,于是便自己写了一个,新手上路,如有错误请指正,话不多说,上代码: def Iou(rec1,rec2): x1,x2,y1,y2 = rec1 #分别是第一个矩形左右上下的坐标 x3,x4,y3,y4 = rec2 #分别是第二个矩形左右上下的坐标 area_1 = (x2-x1)*(y1-y2) area_2 = (x4-x3)*(y3-y4) sum_area = area_1 + area_2 w1 = x2 - x1#第
-
python shapely.geometry.polygon任意两个四边形的IOU计算实例
在目标检测中一个很重要的问题就是NMS及IOU计算,而一般所说的目标检测检测的box是规则矩形框,计算IOU也非常简单,有两种方法: 1. 两个矩形的宽之和减去组合后的矩形的宽就是重叠矩形的宽,同比重叠矩形的高 2. 右下角的minx减去左上角的maxx就是重叠矩形的宽,同比高 然后 IOU = 重叠面积 / (两矩形面积和-重叠面积) 然,不规则四边形就不能通过这种方式来计算,找了好久数学资料,还是没找到答案(鄙人数学渣渣),最后看了白翔老师的textBoxes++论文源码后,知道python
-
浅谈Python3实现两个矩形的交并比(IoU)
一.前言 因为最近刚好被问到这个问题,但是自己当时特别懵逼,导致没有做出来.所以下来后自己Google了很多IoU的博客,但是很多博客要么过于简略,要么是互相转载的,有一些博客图和代码还有点问题,也导致自己这个萌新走了不少弯路.所以自己重新整理了看的博客,力求以更简单的方式展现这个问题的解答办法,方便日后自己回顾.如果朋友们觉得写的有问题的地方,非常欢迎大家在下面留言交流,避免因为我的问题导致读者走弯路. 二.交并比的概念及应用 假设平面坐标中有一个矩形,并且这个矩形的长和宽均分别与x轴和y轴平
-
python实现IOU计算案例
计算两个矩形的交并比,通常在检测任务里面可以作为一个检测指标.你的预测bbox和groundtruth之间的差异,就可以通过IOU来体现.很简单的算法实现,我也随便写了一个,嗯,很简单. 1. 使用时,请注意bbox四个数字的顺序(y0,x0,y1,x1),顺序不太一样. #!/usr/bin/env python # encoding: utf-8 def compute_iou(rec1, rec2): """ computing IoU :param rec1: (y0
-
python实现交并比IOU教程
交并比(Intersection-over-Union,IoU),目标检测中使用的一个概念,是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值.最理想情况是完全重叠,即比值为1. 计算公式: Python实现代码: def cal_iou(box1, box2): """ :param box1: = [xmin1, ymin1, xmax1, ymax1] :param box2: = [xm
-
python中numpy包使用教程之数组和相关操作详解
前言 大家应该都有所了解,下面就简单介绍下Numpy,NumPy(Numerical Python)是一个用于科学计算第三方的Python包. NumPy提供了许多高级的数值编程工具,如:矩阵数据类型.矢量处理,以及精密的运算库.专为进行严格的数字处理而产生.下面本文将详细介绍关于python中numpy包使用教程之数组和相关操作的相关内容,下面话不多说,来一起看看详细的介绍: 一.数组简介 Numpy中,最重要的数据结构是:多维数组类型(numpy.ndarray) ndarray由两部分组成
-

python常见排序算法基础教程
前言:前两天腾讯笔试受到1万点暴击,感觉浪费我两天时间去牛客网做题--这篇博客介绍几种简单/常见的排序算法,算是整理下. 时间复杂度 (1)时间频度一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道.但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了.并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多.一个算法中的语句执行次数称为语句频度或时间频度.记为T(n). (2)时间复
-
Python常用算法学习基础教程
本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出.如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题.不同的算法可能用不同的时间.空间或效率来完成同样的任务.一个算法的优劣可以用空间复杂度与时间复杂度来衡量. 一个算法应该具有以下七个重要的特征: ①有穷性(Fin
-
Python装饰器入门学习教程(九步学习)
装饰器(decorator)是一种高级Python语法.装饰器可以对一个函数.方法或者类进行加工.在Python中,我们有多种方法对函数和类进行加工,比如在Python闭包中,我们见到函数对象作为某一个函数的返回结果.相对于其它方式,装饰器语法简单,代码可读性高.因此,装饰器在Python项目中有广泛的应用. 这是在Python学习小组上介绍的内容,现学现卖.多练习是好的学习方式. 第一步:最简单的函数,准备附加额外功能 # -*- coding:gbk -*- '''示例1: 最简单的函数,表
-
Python之Django环境搭建教程(MAC+pycharm+Django++postgreSQL)
搭建Django环境似乎是一件很简单的事情,其实不然,苦命的我折腾了大半天才好, 遂在此总结下整个搭建过程,同时也愿刚入门的同行少走弯路~ 现在开始,所需工具: MAC电脑 Pycharm 2017 for MAC jdk1.8 Python3.6 postgreSQL 9.6.6 Toad/navicat/pgAdmin 数据库工具 (非必须) 大致需要这些东西,至于为什么要装jdk,大概是Pycharm本身部分依赖于java环境,可以看看产品说明可略窥一二: 嗯~,还有postgreSQL如
-
Windows环境下python环境安装使用图文教程
Windows环境下python的安装与使用 一.python如何运行程序 首先说一下python解释器,它是一种让其他程序运行起来的程序.当你编写了一段python程序,python解释器将读取程序,并按照其中的命令执行,得出结果,实际上,解释器是代码与机器的计算机硬件之间的软件逻辑层. 通俗来说,我们的计算机是基于二进制进行运算的,无论你用什么语言来写程序,无论你的程序写的多么简单或多么复杂,最终交给计算机运行的一定是 0或1,因为计算机只能识别0和1. 我们目前使用的大多数编程语言都是高级
-
python操作oracle的完整教程分享
1. 连接对象 操作数据库之前,首先要建立数据库连接. 有下面几个方法进行连接. >>>import cx_Oracle >>>db = cx_Oracle.connect('hr', 'hrpwd', 'localhost:1521/XE') >>>db1 = cx_Oracle.connect('hr/hrpwd@localhost:1521/XE') >>>dsn_tns = cx_Oracle.makedsn('localho
-
Python 机器学习库 NumPy入门教程
NumPy是一个Python语言的软件包,它非常适合于科学计算.在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础库. 本文是对它的一个入门教程. 介绍 NumPy是一个用于科技计算的基础软件包,它是Python语言实现的.它包含了: 强大的N维数组结构 精密复杂的函数 可集成到C/C++和Fortran代码的工具 线性代数,傅里叶变换以及随机数能力 除了科学计算的用途以外,NumPy也可被用作高效的通用数据的多维容器.由于它适用于任意类型的数据,这使得NumPy可以无缝和
-
Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.