Python实现非正太分布的异常值检测方式
工作中,我们经常会遇到数据异常,比如说浏览量突增猛降,交易量突增猛降,但是这些数据又不是符合正太分布的,如果用几倍西格玛就不合适,那么我们如何来判断这些变化是否在合理的范围呢?
小白查阅一些资料后,发现可以用箱形图,具体描述如下:
箱形图(英文:Box plot),又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。箱形图最大的优点就是不受异常值的影响,能够准确稳定地描绘出数据的离散分布情况,同时也利于数据的清洗。
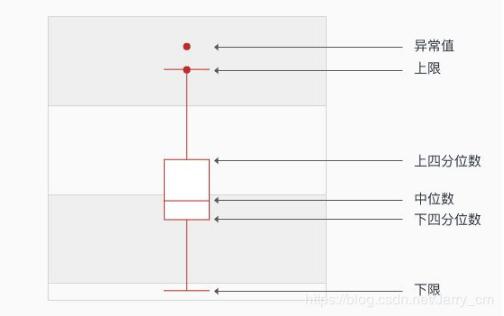
异常值可以设置为上四分位数的1.25倍,也可以设置为1.5倍,具体的要通过实验可得。
1、下四分位数Q1
(1)确定四分位数的位置。Qi所在位置=i(n+1)/4,其中i=1,2,3。n表示序列中包含的项数。
(2)根据位置,计算相应的四分位数。
例中:Q1所在的位置=(14+1)/4=3.75,Q1=0.25×第三项+0.75×第四项=0.25×17+0.75×19=18.5;
2、中位数(第二个四分位数)Q2中位数,即一组数由小到大排列处于中间位置的数。若序列数为偶数个,该组的中位数为中间两个数的平均数。
例中:Q2所在的位置=2(14+1)/4=7.5,Q2=0.5×第七项+0.5×第八项=0.5×25+0.5×28=26.5
3、上四分位数Q3计算方法同下四分位数。
例中:Q3所在的位置=3(14+1)/4=11.25,Q3=0.75×第十一项+0.25×第十二项=0.75×34+0.25×35=34.25。
4、上限上限是非异常范围内的最大值。
首先要知道什么是四分位距如何计算的?四分位距IQR=Q3-Q1,那么上限=Q3+1.5IQR5、下限下限是非异常范围内的最小值。下限=Q1-1.5IQR
我这里是使用上四分位数的1.5倍作为上限,下四分位数的1.5倍作为下限。
这里是拿历史一个月每天的产量和间夜量作为参考,统计出历史的箱线图的各个指标,然后将要比较的数据,来进行循环判断,若超过上限/下限那么抛出1和0.
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 30 10:52:37 2019
@author: chen_lib
"""
import pandas as pd
catering_sale = 'D:/Users/chen_lib/Desktop/ceshi.csv' #读取历史数据
datax = pd.read_csv(catering_sale) #读取数据
#取出不是昨天的数据
data = datax.loc[datax['orderdate'] != datetime][:]
'''
import time
## yyyy-mm-dd格式
print (time.strftime("%Y-%m-%d"))
'''
#时间减一天
import datetime
datetime = (datetime.datetime.now()+datetime.timedelta(days=-1)).strftime("%Y-%m-%d")
#保存基本统计量,将常见的统计信息保存为数据框
statistics = data.describe()
#添加行标签 计算出每个指标的上线下线和四分位间距
statistics.loc['IQR'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距
statistics.loc['UP'] = statistics.loc['75%'] + 1.5*statistics.loc['IQR'] #上限
statistics.loc['DAWN'] = statistics.loc['25%'] - 1.5*statistics.loc['IQR']#下限
#取出data的列名
columns = data.columns.values.tolist()
'''取出要比较的数值,放在统计信息表'''
a = data.loc[data['orderdate'] == datetime][columns[1]]#取出第一列
b = data.loc[data['orderdate'] == datetime][columns[2]]#取出第二列
statistics.loc['res'] = [a[1],b[1]]#取出需要比较的当天的数据 放入统计信息中
'''循环取出结果是否满足要求'''
ret = []
for i in range(2):
res = statistics.loc['res'][i]
max = statistics.loc['UP'][columns[i+1]]#最大值
min = statistics.loc['DAWN'][columns[i+1]]#最小值
'''
#重建三个值的索引,以便比较大小
res.index = ['ordernum']
max.index = max['ordernum']
min.index = min['ordernum']
#判断异常值,若大于最大值或者小于最小值则抛出结果为1
'''
result1 = res>max
result2 = res<min
if result1 =='False' or result2 == 'False':
ret.append([columns[i+1],1])
else:
ret.append([columns[i+1],0])
df = pd.DataFrame(ret)
#将文件写入excel表中
df.to_excel("d:/Users/chen_lib/Desktop/ceshi.xlsx",sheet_name="total",index=False,header=False)
以上这篇Python实现非正太分布的异常值检测方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
解析Python中的异常处理
在程序运行的过程中,如果发生了错误,可以事先约定返回一个错误代码,这样,就可以知道是否有错,以及出错的原因.在操作系统提供的调用中,返回错误码非常常见.比如打开文件的函数open(),成功时返回文件描述符(就是一个整数),出错时返回-1. 用错误码来表示是否出错十分不便,因为函数本身应该返回的正常结果和错误码混在一起,造成调用者必须用大量的代码来判断是否出错: def foo(): r = some_function() if r==(-1): return (-1) # do somethin
-
python 自定义异常和异常捕捉的方法
异常捕捉: try: XXXXX1 raise Exception("xxxxx2") except (Exception1,Exception2,--): xxxx3 else: xxxxx4 finally: xxxxxxx5 1.raise 语句可以自定义报错信息,如上. 2. raise后的语句是不会被执行了,因为已经抛出异常,控制流将会跳到异常捕捉模块. 3. except 语句可以一个except后带多个异常,也可以用多个语句捕捉多个异常,分别做不同处理. 4. excep
-
python实现数据清洗(缺失值与异常值处理)
1. 将本地sql文件写入mysql数据库 本文写入的是python数据库的taob表 source [本地文件] 其中总数据为9616行,列分别为title,link,price,comment 2.使用python链接并读取数据 查看数据概括 #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplotlib.pylab as plt import mysql.connector
-
Python实现非正太分布的异常值检测方式
工作中,我们经常会遇到数据异常,比如说浏览量突增猛降,交易量突增猛降,但是这些数据又不是符合正太分布的,如果用几倍西格玛就不合适,那么我们如何来判断这些变化是否在合理的范围呢? 小白查阅一些资料后,发现可以用箱形图,具体描述如下: 箱形图(英文:Box plot),又称为盒须图.盒式图.盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图.因型状如箱子而得名.箱形图最大的优点就是不受异常值的影响,能够准确稳定地描绘出数据的离散分布情况,同时也利于数据的清洗. 异常值可以设置为上四分位数的1
-

Python数据分析基础之异常值检测和处理方式
目录 1 什么是异常值? 2 异常值的检测方法 1. 简单统计 2. 3∂原则 3. 箱型图 4. 基于模型检测 5. 基于近邻度的离群点检测 6. 基于聚类的方法来做异常点检测 7. 专门的离群点检测 3 异常值的处理方法 4 异常值总结 1 什么是异常值? 在机器学习中,异常检测和处理是一个比较小的分支,或者说,是机器学习的一个副产物,因为在一般的预测问题中,模型通常是对整体样本数据结构的一种表达方式,这种表达方式通常抓住的是整体样本一般性的性质,而那些在这些性质上表现完全与整体样本不一致的
-
python+openCV利用摄像头实现人员活动检测
本文实例为大家分享了python+openCV利用摄像头实现人员活动检测的具体代码,供大家参考,具体内容如下 1.前言 最近在做个机器人比赛,其中一项要求是让机器人实现对是否有人员活动的检测,所以就先拿PC端写一下,准备移植到机器人的树莓派. 2.工具 工具还是简单的python+视觉模块openCV,代码量也比较少.很简单就可以实现 3.人员检测的原理 从图书馆借了一本<特征提取与图像处理(第二版)>,是Mark S.Nixon和Alberto S.Aguado写的,其中讲了跟多关于检测
-
python 实现非极大值抑制算法(Non-maximum suppression, NMS)
NMS 算法在目标检测,目标定位领域有较广泛的应用. 算法原理 非极大值抑制算法(Non-maximum suppression, NMS)的本质是搜索局部极大值,抑制非极大值元素. 算法的作用 当算法对一个目标产生了多个候选框的时候,选择 score 最高的框,并抑制其他对于改目标的候选框 适用场景 一幅图中有多个目标(如果只有一个目标,那么直接取 score 最高的候选框即可). 算法的输入 算法对一幅图产生的所有的候选框,以及每个框对应的 score (可以用一个 5 维数组 dets 表
-
Python使用Opencv实现边缘检测以及轮廓检测的实现
边缘检测 Canny边缘检测器是一种被广泛使用的算法,并被认为是边缘检测最优的算法,该方法使用了比高斯差分算法更复杂的技巧,如多向灰度梯度和滞后阈值化. Canny边缘检测器算法基本步骤: 平滑图像:通过使用合适的模糊半径执行高斯模糊来减少图像内的噪声. 计算图像的梯度:这里计算图像的梯度,并将梯度分类为垂直.水平和斜对角.这一步的输出用于在下一步中计算真正的边缘. 非最大值抑制:利用上一步计算出来的梯度方向,检测某一像素在梯度的正方向和负方向上是否是局部最大值,如果是,则抑制该像素(像素不属于
-
Python实战之OpenCV实现猫脸检测
开发工具 Python版本:3.6.4 相关模块: cv2模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 原理简介 简单地讲一讲Haar分类器,也就是Viola-Jones识别器. 详细的原理说明可参考相关文件中的两篇论文: Rapid Object Detection using a Boosted Cascade of Simple Features; Robust Real-Time Face Detection. (1
-
Python+OpenCV内置方法实现行人检测
您是否知道 OpenCV 具有执行行人检测的内置方法? OpenCV 附带一个预训练的 HOG + 线性 SVM 模型,可用于在图像和视频流中执行行人检测. 今天我们使用Opencv自带的模型实现对视频流中的行人检测,只需打开一个新文件,将其命名为 detect.py ,然后加入代码: # import the necessary packages from __future__ import print_function import numpy as np import argparse i
-
Python双端队列实现回文检测
目录 一.双端队列 二.回文检测 补充 一.双端队列 双端队列 Deque 是一种有次序的数据集,跟队列相似,其两端可以称作"首" 和 "尾"端,但 Deque 中数据项既可以从队首加入,也可以从队尾加入:数据项也可以从两端移除.某种意义上说,双端队列集成了栈和队列的能力. 但双端队列并不具有内在的 LIFO 或者 FIFO 特性,如果用双端队列来模拟栈或队列,需要由使用者自行维护操作的一致性. 用 Python 实现抽象数据类型Deque,Deque定义的操作如下
-
Python正则表达式非贪婪、多行匹配功能示例
本文实例讲述了Python正则表达式非贪婪.多行匹配功能.分享给大家供大家参考,具体如下: 一些regular的tips: 1 非贪婪flag >>> re.findall(r"a(\d+?)","a23b") # 非贪婪模式 ['2'] >>> re.findall(r"a(\d+)","a23b") ['23'] 注意比较这种情况: >>> re.findall(r&q
-
python在非root权限下的安装方法
以前在使用Python的时候,都是使用root用户安装好的全局python,现在,因为root用户安装的Python版本太低,同时自己没有root权限去对全局Python升级,所以要在非root用户下安装自己指定的Python.因此,就重新整理了一份如何在Linux环境下使用非root用户安装python及其相关的库,以备不时之需. 安装python python版本库https://www.python.org/ftp/python/,此处我选择2.7.5版本的,在安装python的时候,使用