Python re正则表达式元字符分组()用法分享
分组小括号() 有直接分组和命名分组
直接分组: ()分组只显示小括号括起来的内容
re.findall(r"(name)+","namename")
这里匹配到了namename 但是值显示括号中的name

直接分组实例
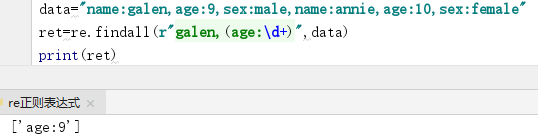
re.search()方法: 搜索结果返回对象,可以用ret.group()方法打印结果
它跟findall不同在于找到一个结果就不再往下找了

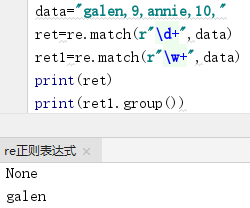
re.match()方法: 只匹配字符串开始的位置
有名分组: 给分组取名?P<name>,可以用名字取匹配的结果

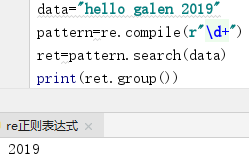
re.compile() 编译正则表达式,提高效率
以上就是我们小编整理的相关知识点内容,感谢大家的学习和对我们的支持。
相关推荐
-
Python re正则表达式元字符分组()用法分享
分组小括号() 有直接分组和命名分组 直接分组: ()分组只显示小括号括起来的内容 re.findall(r"(name)+","namename") 这里匹配到了namename 但是值显示括号中的name 直接分组实例 re.search()方法: 搜索结果返回对象,可以用ret.group()方法打印结果 它跟findall不同在于找到一个结果就不再往下找了 re.match()方法: 只匹配字符串开始的位置 有名分组: 给分组取名?P<name>
-
python中正则表达式 re.findall 用法
Python 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数. 本文主要给大家介绍
-
python中正则表达式findall的用法实例
正则口径:知道前后取中间,如果最后$结束 python中则这表达式的方法通常由re.match re.search re.findall re.findall匹配的时候,会把结果放到list返回,如果没有匹配到返回空list不会报错 import re s1=re.compile('\d+') # 匹配数字 r1=s1.findall('sahduasu27bhsagd7236vbcsahg923') print(r1) s2=re.compile('\d+') r2=re.findall(s2
-

Python正则表达式匹配中文用法示例
本文实例讲述了Python正则表达式匹配中文用法.分享给大家供大家参考,具体如下: #!/usr/bin/python #-*- coding:cp936-*-#思路,将str转换成unicode,方可用正则表达式,前提是,要知道文件的编码,本例中是gbk import cPickle as mypickle import re import sys if (__name__=='__main__'): fid1=file('demo.txt','r');#demo.txt写入字符如:我们 p=
-
javascript正则表达式之分组概念与用法实例
本文实例讲述了javascript正则表达式之分组概念与用法.分享给大家供大家参考,具体如下: function matchDemo(){ var s; //该表达式分了三个组:d(b+)(d).(b+).(d)这个三个组(实际上是四个组,包括本身所有的表达式) //从最左边数第一个括号为第一个组,第二个括号为第二组,以此类推,分别对应的值为RegExp.$1和RegExp.$2的值 var re = new RegExp("(d(b+)(d))","ig"); v
-
JS正则表达式之非捕获分组用法实例分析
本文实例讲述了JS正则表达式非捕获分组用法.分享给大家供大家参考,具体如下: 最近在看JsonSQL的时候,通过源码中的一段正则表达式,了解到了什么是非捕获分组以及它的使用场景.在js中,正常的捕获分组格式是(XX),非捕获分组格式为(?:XX).我们先从正则表达式数量词说起,如果我们要求字符b至少出现一次,可以使用正则/b+/:如果要求ab至少出现一次,那么必需使用/(ab)+/,不能用/ab+/.也就是说,如果想对多个字符使用数量词,必需要用圆括号. var str = "a1***ab1c
-
Python松散正则表达式用法分析
本文实例讲述了Python松散正则表达式用法.分享给大家供大家参考,具体如下: Python 允许用户利用所谓的 松散正则表达式来完成这个任务.一个松散正则表达式和一个紧凑正则表达式主要区别表现在两个方面: 1. 忽略空白符.空格符,制表符,回车符不匹配它们自身,他们根本不参与匹配.(如果你想在松散正则表达式中匹配一个空格符,你必须在它前面添加一个反斜线符号对他进行转义) 2. 忽略注释.在松散正则表达式中的注释和在普通Python代码中的一样:开始于一个#符号,结束于行尾.这种情况下,采用在一
-
Python元字符的用法实例解析
反斜杠的作用: 要想将一个元字符^当一个普通字符处理,加反斜杠 例如: >>>import re >>>r=r'\^abc' >>>re.findall(r,'^abc ^abc ^abc') ['^abc','^abc','^abc'] \d匹配任何十进制数,它相当于类[0-9]. \D匹配任何非数字字符,它相当于类[^0-9] \s匹配任何空白字符,他相当于类[\t\n\r\f\v] \S匹配任何非空白字符,它相当于类[^\t\n\r\f\v] \
-
python正则表达式re.group()用法
目录 re.group()用法 re.group()用法 在正则表达式中,re.group()方法是用来提取出分组截获的字符串,匹配模式里的括号用于分组. 举例说明: #!/usr/bin/env python # -*- coding:utf-8 -*- import re if __name__ == '__main__': # 匹配模式 test_pattern = r"(\d{2}年)(\d{4}年)(\d{4}年)" # 待匹配的字符串 test = "18年201
-
Python正则表达式re.search()用法详解
re.search():匹配整个字符串,并返回第一个成功的匹配.如果匹配失败,则返回None pattern: 匹配的规则, string : 要匹配的内容, flags 标志位 这个是可选的,就是可以不写,可以写, 比如要忽略字符的大小写就可以使用标志位 flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为: re.I 忽略大小写 re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境 re.M 多行模式 re.S 即为 . 并且包括换行符