基于TensorFlow中自定义梯度的2种方式
前言
在深度学习中,有时候我们需要对某些节点的梯度进行一些定制,特别是该节点操作不可导(比如阶梯除法如 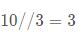 ),如果实在需要对这个节点进行操作,而且希望其可以反向传播,那么就需要对其进行自定义反向传播时的梯度。在有些场景,如[2]中介绍到的梯度反转(gradient inverse)中,就必须在某层节点对反向传播的梯度进行反转,也就是需要更改正常的梯度传播过程,如下图的
),如果实在需要对这个节点进行操作,而且希望其可以反向传播,那么就需要对其进行自定义反向传播时的梯度。在有些场景,如[2]中介绍到的梯度反转(gradient inverse)中,就必须在某层节点对反向传播的梯度进行反转,也就是需要更改正常的梯度传播过程,如下图的  所示。
所示。
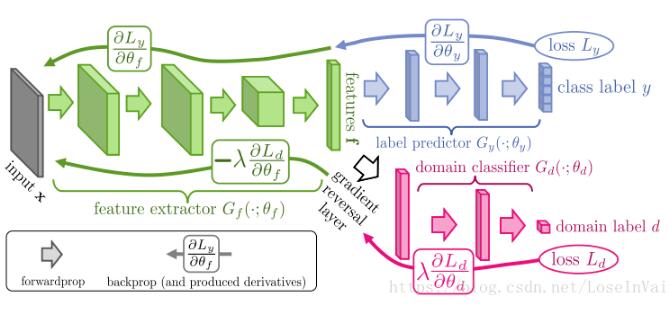
在tensorflow中有若干可以实现定制梯度的方法,这里介绍两种。
1. 重写梯度法
重写梯度法指的是通过tensorflow自带的机制,将某个节点的梯度重写(override),这种方法的适用性最广。我们这里举个例子[3].
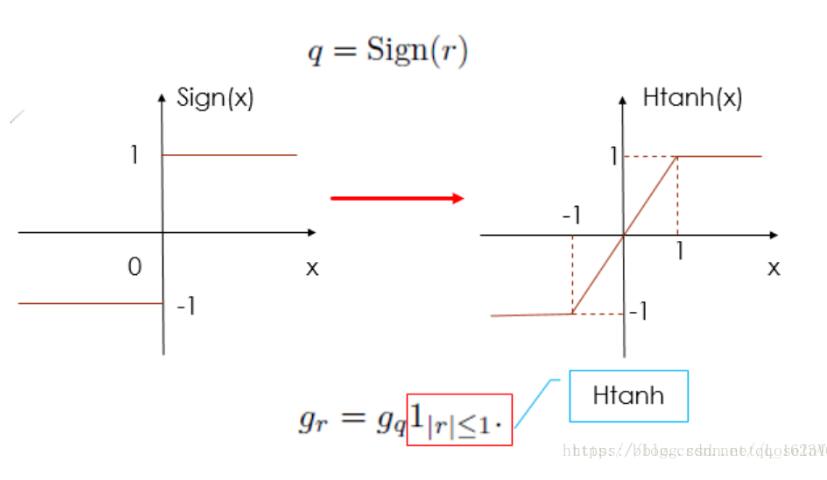
符号函数的前向传播采用的是阶跃函数y=sign(x) y = \rm{sign}(x)y=sign(x),如下图所示,我们知道阶跃函数不是连续可导的,因此我们在反向传播时,将其替代为一个可以连续求导的函数y=Htanh(x) y = \rm{Htanh(x)}y=Htanh(x),于是梯度就是大于1和小于-1时为0,在-1和1之间时是1。
使用重写梯度的方法如下,主要是涉及到tf.RegisterGradient()和tf.get_default_graph().gradient_override_map(),前者注册新的梯度,后者重写图中具有名字name='Sign'的操作节点的梯度,用在新注册的QuantizeGrad替代。
#使用修饰器,建立梯度反向传播函数。其中op.input包含输入值、输出值,grad包含上层传来的梯度
@tf.RegisterGradient("QuantizeGrad")
def sign_grad(op, grad):
input = op.inputs[0] # 取出当前的输入
cond = (input>=-1)&(input<=1) # 大于1或者小于-1的值的位置
zeros = tf.zeros_like(grad) # 定义出0矩阵用于掩膜
return tf.where(cond, grad, zeros)
# 将大于1或者小于-1的上一层的梯度置为0
#使用with上下文管理器覆盖原始的sign梯度函数
def binary(input):
x = input
with tf.get_default_graph().gradient_override_map({"Sign":'QuantizeGrad'}):
#重写梯度
x = tf.sign(x)
return x
#使用
x = binary(x)
其中的def sign_grad(op, grad):是注册新的梯度的套路,其中的op是当前操作的输入值/张量等,而grad指的是从反向而言的上一层的梯度。
通常来说,在tensorflow中自定义梯度,函数tf.identity()是很重要的,其API手册如下:
tf.identity( input, name=None )
其会返回一个形状和内容都和输入完全一样的输出,但是你可以自定义其反向传播时的梯度,因此在梯度反转等操作中特别有用。
这里再举个反向梯度[2]的例子,也就是梯度为  而不是
而不是 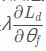
import tensorflow as tf
x1 = tf.Variable(1)
x2 = tf.Variable(3)
x3 = tf.Variable(6)
@tf.RegisterGradient('CustomGrad')
def CustomGrad(op, grad):
# tf.Print(grad)
return -grad
g = tf.get_default_graph()
oo = x1+x2
with g.gradient_override_map({"Identity": "CustomGrad"}):
output = tf.identity(oo)
grad_1 = tf.gradients(output, oo)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(grad_1))
因为-grad,所以这里的梯度输出是[-1]而不是[1]。有一个我们需要注意的是,在自定义函数def CustomGrad()中,返回的值得是一个张量,而不能返回一个参数,比如return 0,这样会报错,如:
AttributeError: 'int' object has no attribute 'name'
显然,这是因为tensorflow的内部操作需要取返回值的名字而int类型没有名字。
PS:def CustomGrad()这个函数签名是随便你取的。
2. stop_gradient法
对于自定义梯度,还有一种比较简洁的操作,就是利用tf.stop_gradient()函数,我们看下例子[1]:
t = g(x) y = t + tf.stop_gradient(f(x) - t)
这里,我们本来的前向传递函数是f(x),但是想要在反向时传递的函数是g(x),因为在前向过程中,tf.stop_gradient()不起作用,因此+t和-t抵消掉了,只剩下f(x)前向传递;而在反向过程中,因为tf.stop_gradient()的作用,使得f(x)-t的梯度变为了0,从而只剩下g(x)在反向传递。
我们看下完整的例子:
import tensorflow as tf x1 = tf.Variable(1) x2 = tf.Variable(3) x3 = tf.Variable(6) f = x1+x2*x3 t = -f y1 = t + tf.stop_gradient(f-t) y2 = f grad_1 = tf.gradients(y1, x1) grad_2 = tf.gradients(y2, x1) with tf.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) print(sess.run(grad_1)) print(sess.run(grad_2))
第一个输出为[-1],第二个输出为[1],显然也实现了梯度的反转。
以上这篇基于TensorFlow中自定义梯度的2种方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
tensorflow 实现自定义layer并添加到计算图中
目的 将用户自定义的layer结合tensorflow自带的layer组成多层layer的计算图. 实现功能 对2D图像进行滑动窗口平均,并通过自定义的操作layer返回结果. import tensorflow as tf import numpy as np sess = tf.Session() #将size设为[1, 4, 4, 1]是因为tf中图像函数是处理四维图片的. #这四维依次是: 图片数量,高度, 宽度, 颜色通道 x_shape = [1,4,4,1] x_val = np.
-
TensorFlow设置日志级别的几种方式小结
TensorFlow中的log共有INFO.WARN.ERROR.FATAL 4种级别.有以下几种设置方式. 1. 通过设置环境变量控制log级别 可以通过环境变量TF_CPP_MIN_LOG_LEVEL进行设置,TF_CPP_MIN_LOG_LEVEL的不同值的含义分别如下: Level Level for Humans Level Description 0 DEBUG all messages are logged (Default) 1 INFO INFO messages are no
-
tensorflow使用指定gpu的方法
TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief [1] . Tensorflow拥有多层级结构,可部署于各类服务器.PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究 . TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括Ten
-
tensorflow 查看梯度方式
1. 为什么要查看梯度 对于初学者来说网络经常不收敛,loss很奇怪(就是不收敛),所以怀疑是反向传播中梯度的问题 (1)求导之后的数(的绝对值)越来越小(趋近于0),这就是梯度消失 (2)求导之后的数(的绝对值)越来越大(特别大,发散),这就是梯度爆炸 所以说呢,当loss不正常时,可以看看梯度是否处于爆炸,或者是消失了,梯度爆炸的话,网络中的W也会很大,人工控制一下(初始化的时候弄小点等等肯定还有其它方法,只是我不知道,知道的大神也可以稍微告诉我一下~~),要是梯度消失,可以试着用用resn
-
TensorFlow实现自定义Op方式
『写在前面』 以CTC Beam search decoder为例,简单整理一下TensorFlow实现自定义Op的操作流程. 基本的流程 1. 定义Op接口 #include "tensorflow/core/framework/op.h" REGISTER_OP("Custom") .Input("custom_input: int32") .Output("custom_output: int32"); 2. 为Op实现
-
TensorFlow梯度求解tf.gradients实例
我就废话不多说了,直接上代码吧! import tensorflow as tf w1 = tf.Variable([[1,2]]) w2 = tf.Variable([[3,4]]) res = tf.matmul(w1, [[2],[1]]) grads = tf.gradients(res,[w1]) with tf.Session() as sess: tf.global_variables_initializer().run() print sess.run(res) print se
-
基于TensorFlow中自定义梯度的2种方式
前言 在深度学习中,有时候我们需要对某些节点的梯度进行一些定制,特别是该节点操作不可导(比如阶梯除法如 ),如果实在需要对这个节点进行操作,而且希望其可以反向传播,那么就需要对其进行自定义反向传播时的梯度.在有些场景,如[2]中介绍到的梯度反转(gradient inverse)中,就必须在某层节点对反向传播的梯度进行反转,也就是需要更改正常的梯度传播过程,如下图的 所示. 在tensorflow中有若干可以实现定制梯度的方法,这里介绍两种. 1. 重写梯度法 重写梯度法指的是通过tensorf
-
基于keras中训练数据的几种方式对比(fit和fit_generator)
一.train_on_batch model.train_on_batch(batchX, batchY) train_on_batch函数接受单批数据,执行反向传播,然后更新模型参数,该批数据的大小可以是任意的,即,它不需要提供明确的批量大小,属于精细化控制训练模型,大部分情况下我们不需要这么精细,99%情况下使用fit_generator训练方式即可,下面会介绍. 二.fit model.fit(x_train, y_train, batch_size=32, epochs=10) fit的
-
在Tensorflow中实现梯度下降法更新参数值
我就废话不多说了,直接上代码吧! tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) TensorFlow经过使用梯度下降法对损失函数中的变量进行修改值,默认修改tf.Variable(tf.zeros([784,10])) 为Variable的参数. train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy,var_list=
-
tensorflow 实现自定义梯度反向传播代码
以sign函数为例: sign函数可以对数值进行二值化,但在梯度反向传播是不好处理,一般采用一个近似函数的梯度作为代替,如上图的Htanh.在[-1,1]直接梯度为1,其他为0. #使用修饰器,建立梯度反向传播函数.其中op.input包含输入值.输出值,grad包含上层传来的梯度 @tf.RegisterGradient("QuantizeGrad") def sign_grad(op, grad): input = op.inputs[0] cond = (input>=-1
-

Angularjs 自定义服务的三种方式(推荐)
AngularJS简介: AngularJS 通过新的属性和表达式扩展了 HTML. AngularJS 可以构建一个单一页面应用程序(SPAs:Single Page Applications). AngularJS 学习起来非常简单. angularjs 中可通过三种($provider,$factory,$service)方式自定义服务,以下是不同的实现形式: // 定义module , module中注入$provide var starterApp = angular.module('
-
在Android TextView中显示图片的4种方式详解
我们知道,TextView控件一般是用来显示文本的,而图片一般是用ImageView控件来显示. 那TextView能否显示图片呢?答案是肯定的!下面列出常见的4种方式. 1.XML文件中指定属性值 这种方式应该是最常用的了,在TextView的左上右下显示图片,可用 android:drawableLeft android:drawableTop android:drawableRight android:drawableBottom 比如我们要在TextView的顶部设置图片,代码如
-
详解Angular Forms中自定义ngModel绑定值的方式
在 Angular 应用中,我们有两种方式来实现表单绑定--"模板驱动表单"与"响应式表单".这两种方式通常能够很好的处理大部分的情况,但是对于一些特殊的表单控件,例如 input[type=datetime] . input[type=file] ,我们需要重写默认的表单绑定方式,让我们绑定的变量不再仅仅只是一个字符串,而是一个 Date 或者 File 对象.为了达成这一目的,我们需要自定义表单控件的 ControlValueAccessor . Control
-
linux服务中开启防火墙的两种方式
存在以下两种方式: 一.service方式 查看防火墙状态: [root@centos6 ~]# service iptables status iptables:未运行防火墙. 开启防火墙: [root@centos6 ~]# service iptables start 关闭防火墙: [root@centos6 ~]# service iptables stop 二.iptables方式 先进入init.d目录,命令如下: [root@centos6 ~]# cd /etc/init.d/
-
Spring中自动装配的4种方式
Spring容器可以在不使用<constructor-arg>和<property>元素的情况下自动装配相互协作的bean之间的关系,助于减少编写一个大的基于Spring的应用程序的XML配置的数量使用<bean>元素的autowire属性为一个bean定义指定自动装配模式. 在Spring中,我们有4种方式可以装配Bean的属性. 1,byName 通过byName方式自动装配属性时,是在定义Bean的时候,在property标签中设置autowire属性为byNam