Python实战练习之终于对肯德基下手
准备工作
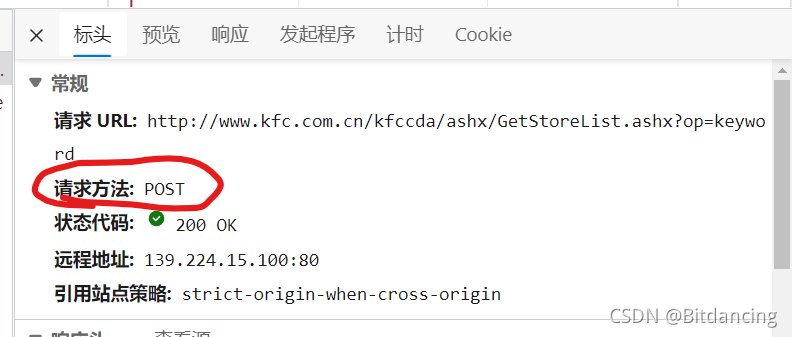
查看肯德基官网的请求方法:post请求。
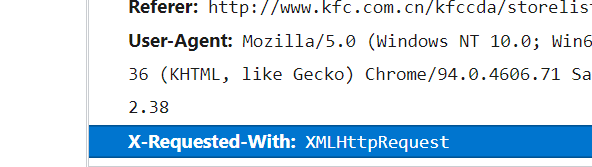
X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求
通过这两个准备步骤,明确本次爬虫目标:
ajax的post请求肯德基官网 获取上海肯德基地点前10页。
分析
获取上海肯德基地点前10页,那就需要先对每页的url进行分析。
第一页
# page1 # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname # POST # cname: 上海 # pid: # pageIndex: 1 # pageSize: 10
第二页
# page2 # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname # POST # cname: 上海 # pid: # pageIndex: 2 # pageSize: 10
第三页依次类推。
程序入口
首先回顾urllib爬取的基本操作:
# 使用urllib获取百度首页的源码
import urllib.request
# 1.定义一个url,就是你要访问的地址
url = 'http://www.baidu.com'
# 2.模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
# 3.获取响应中的页面的源码 content内容
# read方法 返回的是字节形式的二进制数据
# 将二进制数据转换为字符串
# 二进制-->字符串 解码 decode方法
content = response.read().decode('utf-8')
# 4.打印数据
print(content)
- 定义一个url,就是你要访问的地址
- 模拟浏览器向服务器发送请求 response响应
- 获取响应中的页面的源码 content内容
if __name__ == '__main__':
start_page = int(input('请输入起始页码: '))
end_page = int(input('请输入结束页码: '))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载数据
down_load(page, content)
对应的,我们在主函数中也类似声明方法。
url组成数据定位
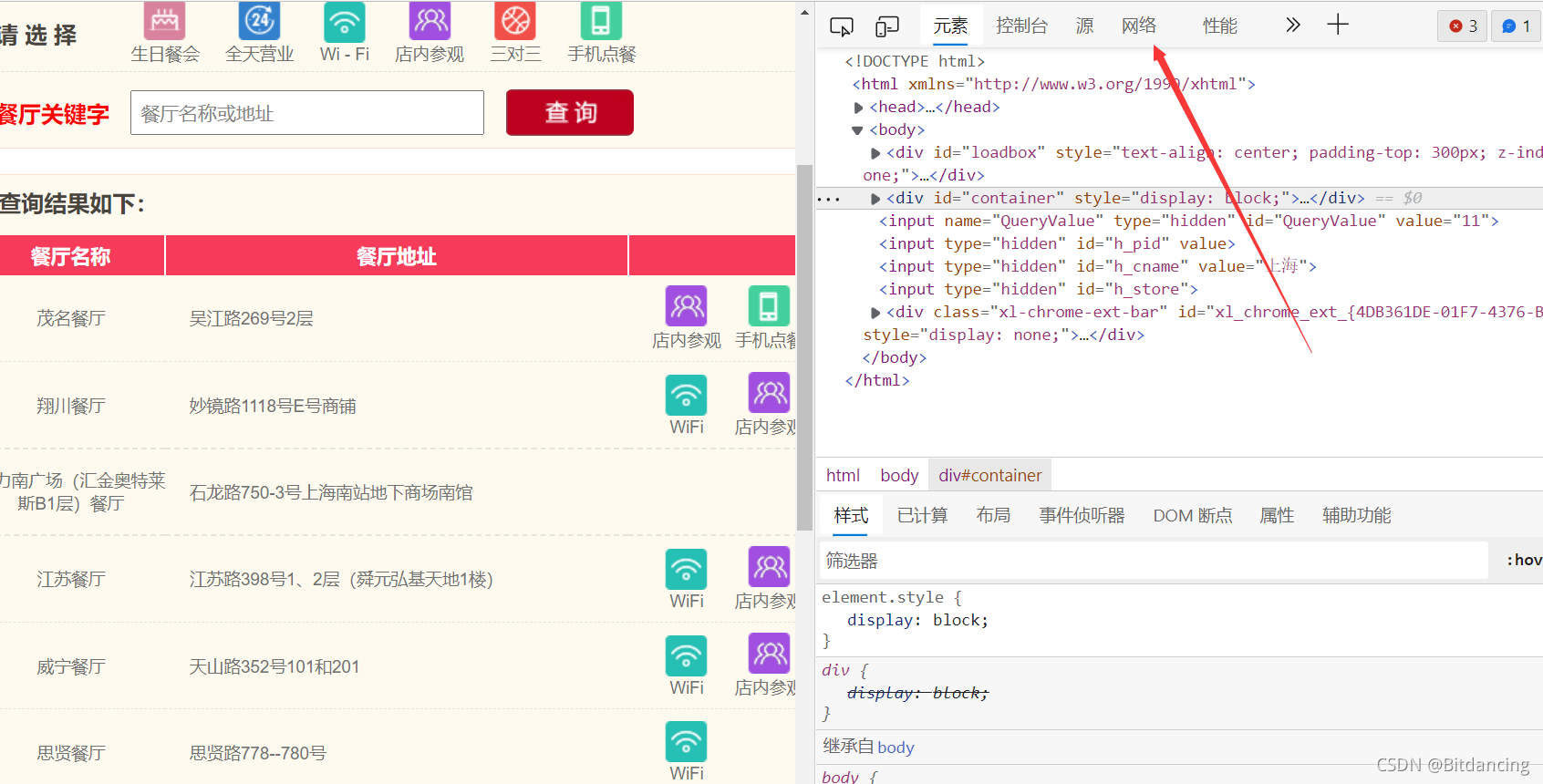
爬虫的关键在于找接口。对于这个案例,在预览页可以找到页面对应的json数据,说明这是我们要的数据。
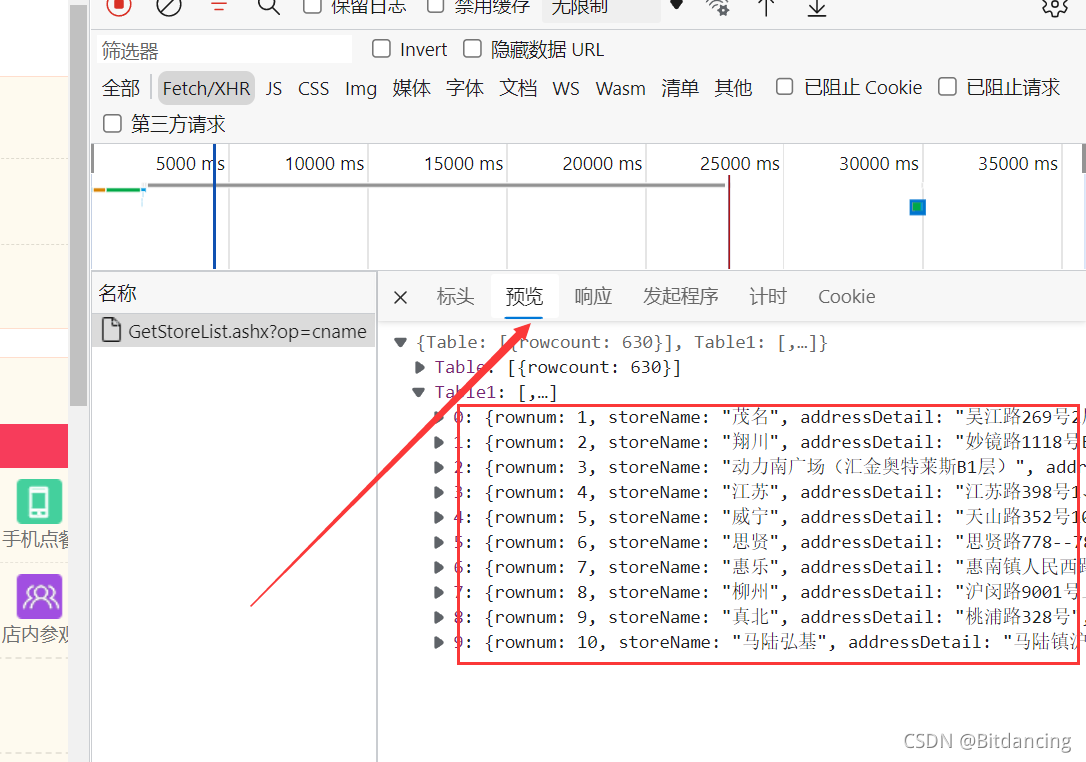
构造url
不难发现,肯德基官网的url的一个共同点,我们把它保存为base_url。
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
参数
老样子,找规律,只有'pageIndex'和页码有关。
data = {
'cname': '上海',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
post请求
- post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
- 编码之后必须调用encode方法
- 参数放在请求对象定制的方法中:post的请求的参数,是不会拼接在url后面的,而是放在请求对象定制的参数中
所以将data进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
标头获取(防止反爬的一种手段)
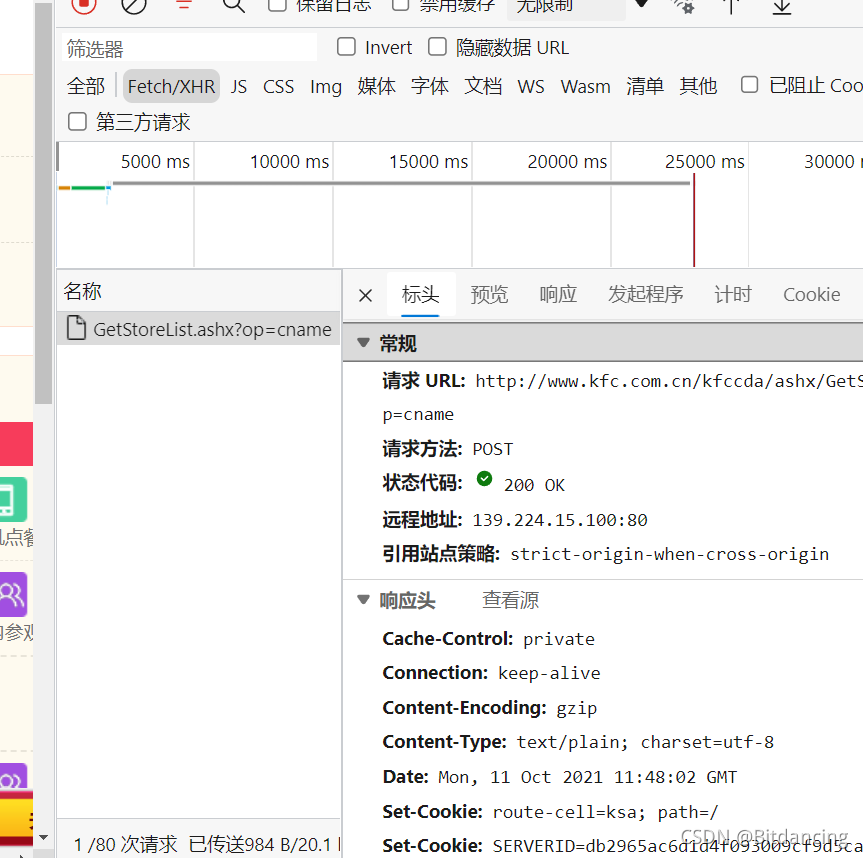
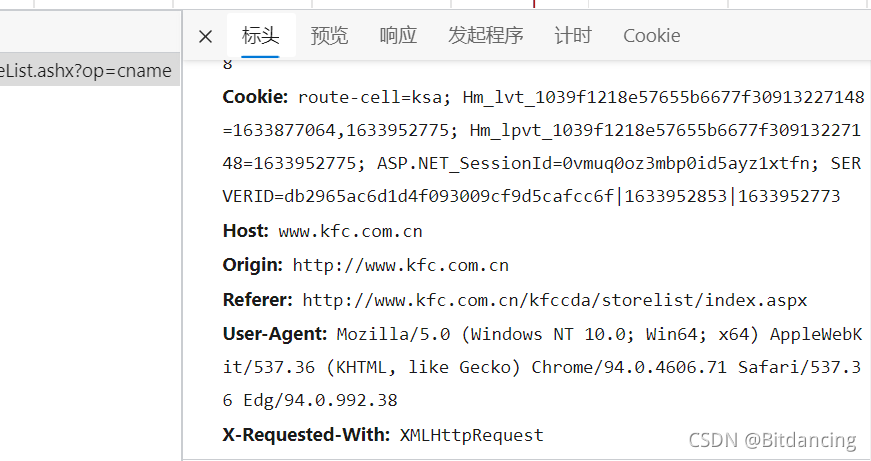
即 响应头中UA部分。
User Agent,用户代理,特殊字符串头,使得服务器能够识别客户使用的操作系统及版本,CPU类型,浏览器及版本,浏览器内核,浏览器渲染引擎,浏览器语言,浏览器插件等。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38'
}
请求对象定制
参数,base_url,请求头都准备得当后,就可以进行请求对象定制了。
request = urllib.request.Request(base_url, headers=headers, data=data)
获取网页源码
把request请求作为参数,模拟浏览器向服务器发送请求 获得response响应。
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
获取响应中的页面的源码,下载数据
使用 read()方法,得到字节形式的二进制数据,需要使用 decode进行解码,转换为字符串。
content = response.read().decode('utf-8')
然后我们将下载得到的数据写进文件,使用 with open() as fp 的语法,系统自动关闭文件。
def down_load(page, content):
with open('kfc_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
全部代码
# ajax的post请求肯德基官网 获取上海肯德基地点前10页
# page1
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# POST
# cname: 上海
# pid:
# pageIndex: 1
# pageSize: 10
# page2
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# POST
# cname: 上海
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request, urllib.parse
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '上海',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38'
}
request = urllib.request.Request(base_url, headers=headers, data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open('kfc_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码: '))
end_page = int(input('请输入结束页码: '))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载数据
down_load(page, content)
爬取后结果
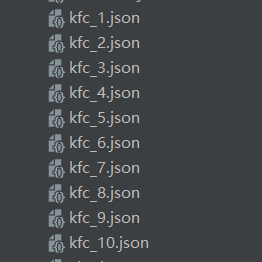
鞠躬!!!其实还爬过Lisa的照片,想看爬虫代码的欢迎留言 !!!
到此这篇关于Python实战练习之终于对肯德基下手的文章就介绍到这了,更多相关Python 肯德基官网内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实战爬虫之女友欲买文胸不知何色更美
目录 情景再现 本文关键词 挑个"软柿子" 单页爬取 数据处理 翻页操作 撸代码 主调度函数 页面抓取函数 解析保存函数 可视化 颜色分布 评价词云图 情景再现 今日天气尚好,女友忽然欲买文胸,但不知何色更美,遂命吾剖析何色买者益众,为点议,事后而奖励之. 本文关键词 协程并发
-
python实战练习之最新男女颜值打分小系统
导语 哈喽!我是木木子,今天又想我了嘛? 之前不是出过一期Python美颜相机嘛?不知道你们还记得不?这一期的话话题还是围绕上期关于颜值方面来走. 还是原来的配方,还是原来的味道. 偶尔有女生或者说男生都有过这样的经历,偶然照镜子的时候觉得自己美.帅到爆炸.[小编打死不会承认的.jpg] 但打开无美颜的前置摄像头无滤镜,或者看到真正的漂亮小姐姐,又会感慨自己怎么能这么丑! 颜值打分其实是个很有争议,并且人人都感兴趣的话题,那么今天木木子就带着Python颜值打分神器走来了! 如果满
-
python实战之Scrapy框架爬虫爬取微博热搜
前言:大概一年前写的,前段时间跑了下,发现还能用,就分享出来了供大家学习,代码的很多细节不太记得了,也尽力做了优化. 因为毕竟是微博,反爬技术手段还是很周全的,怎么绕过反爬的话要在这说都可以单独写几篇文章了(包括网页动态加载,ajax动态请求,token密钥等等,特别是二级评论,藏得很深,记得当时想了很久才成功拿到),直接上代码. 主要实现的功能: 0.理所应当的,绕过了各种反爬. 1.爬取全部的热搜主要内容. 2.爬取每条热搜的相关微博. 3.爬取每条相关微博的评论,评论用户的各种详细信息.
-
python实战小游戏之考验记忆力
导语 哈喽!大家好,我是木木子. 今日游戏更新系列来啦,是不是很想知道今天的游戏是什么类型的?立马安排上-- 随着年纪的不断上升,我们开始丢三落四,忘东忘西,记忆力越来越差了! 这不止大人随着年纪增大记忆力退却,其实很多小孩子也是一样~ 很多家长是不是经常抱怨: "我家孩子背课文特别慢,常常背了几十遍都背不下来,昨晚又背到一点多,我都要崩溃了: 在给孩子辅导课后作业,明明很简单的古诗词填空,孩子的第一反应就是打开书照抄,如果不翻课本,半天写不出来: 昨晚单词背得还好好的,第二天早上抽查的时候,1
-
python网络爬虫实战
目录 一.概述 二.原理 三.爬虫分类 1.传统爬虫 2.聚焦爬虫 3.通用网络爬虫(全网爬虫) 四.网页抓取策略 1.宽度优先搜索: 2.深度优先搜索: 3.最佳优先搜索: 4.反向链接数策略: 5.Partial PageRank策略: 五.网页抓取的方法 1.分布式爬虫 现在比较流行的分布式爬虫: 2.Java爬虫 3.非Java爬虫 六.项目实战 1.抓取指定网页 抓取某网首页 2.抓取包含关键词网页 3.下载贴吧中图片 4.股票数据抓取 六.结语 一.概述 网络爬虫(Web crawl
-
Python实战练习之终于对肯德基下手
准备工作 查看肯德基官网的请求方法:post请求. X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求 通过这两个准备步骤,明确本次爬虫目标: ajax的post请求肯德基官网 获取上海肯德基地点前10页. 分析 获取上海肯德基地点前10页,那就需要先对每页的url进行分析. 第一页 # page1 # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname # POST # cnam
-
Vue实战教程之仿肯德基宅急送App
Vue学习有一段时间了,就想着用Vue来写个项目练练手,弄了半个月,到今天为止也算勉强能看了. 由于不知道怎么拿手机App的接口,并且KFC电脑端官网真的...一言难尽,所以项目所有数据都是我截图然后写在EasyMock里的,有需要的同学可以自取 首页 商品页 外卖页 技术栈 vue + webpack + vuex + axios 文件目录 │ App.vue │ main.js │ ├─assets │ logo.png │ ├─components │ │ cartcontrol.vue
-
Python爬取肯德基官网ajax的post请求实现过程
目录 准备工作 分析 程序入口 url组成数据定位 构造url 参数 post请求 标头获取(防止反爬的一种手段) 请求对象定制 获取网页源码 获取响应中的页面的源码,下载数据 全部代码 爬取后结果 准备工作 查看肯德基官网的请求方法:post请求. X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求 通过这两个准备步骤,明确本次爬虫目标: ajax的post请求肯德基官网 获取上海肯德基地点前10页. 分析 获取上海肯德基地点前10页,那就需要先对
-
java Gui实现肯德基点餐收银系统
大家应该都去麦当劳或肯德基吃过快餐,参考肯德基官网的信息模拟肯德基快餐店的收银系统,简单的java Gui模拟的肯德基收银系统. 1.系统介绍 同学们应该都去麦当劳或肯德基吃过快餐吧?请同学们参考肯德基官网的信息模拟肯德基快餐店的收银系统,合理使用C++/python/Java,结合设计模式(2种以上)至少实现系统的以下功能: 1.正常餐品结算和找零. 2.基本套餐结算和找零. 3.使用优惠劵购买餐品结算和找零. 4.可在一定时间段参与店内活动(自行设计或参考官网信息). 5.模拟打印小票的功能
-
java实现肯德基收银系统
参考肯德基官网的信息模拟肯德基快餐店的收银系统,合理使用C++或Java或Python结合设计模式(2种以上)至少实现系统的以下功能: 1.正常餐品结算和找零. 2.基本套餐结算和找零. 3.使用优惠券购买餐品结算和找零. 4.可在一定时间段参与店内活动(自行设计或参考官网信息). 5.模拟打印小票的功能(写到文件中). 小票信息保存 class print{ String s=""; //存订单信息 } 食物工厂 interface FoodFactory{ public Hambu
-
python实战串口助手_解决8串口多个发送的问题
今晚终于解决了串口发送的问题,更改代码如下: def write(self, data): if self.alive: if self.serSer.isOpen(): self.serSer.write(data) def m_send1butOnButtonClick( self, event ): if self.ser.alive: send_data = '' send_data += str(self.m_textCtrl5.GetValue()) self.ser.write(s
-
Python实战项目之MySQL tkinter pyinstaller实现学生管理系统
终极版终于有时间给大家分享了!!!. 我们先看一下效果图. 1:登录界面: 2:查询数据库所有的内容! 3:链接数据库: 4:最终的打包! 话不多说直接上代码!!!! from tkinter import * import pymysql from tkinter.messagebox import * from tkinter import ttk def get_connect(): conn = pymysql.connect(host='localhost', user="root&q
-
Python实战之天气预报系统的实现
目录 前言 一.前期准备 二.代码展示 三.效果展示 前言 鼎鼎大名的南方城市长沙很早就入冬了,街上各种大衣,毛衣,棉衣齐齐出动. 这段时间全国各地大风呜呜地吹,很多地方断崖式降温. 虽然前几天短暂的温度回升,但肯定是为了今天的超级降温,一大早的就开始狂风四起. 周五早晨,终于体验了一把久违冷冷的冰雨在脸上胡乱的拍!昨天还有10几度的天气,今天就 只有2-3°了,真真是老天爷的脸七十二变~ 广东的朋友们,听说你们哪儿最低温度都是10几度,我实名羡慕了——(要我说从哪儿听说的,昨天跟刺激战场打游
-
Python实战小程序利用matplotlib模块画图代码分享
Python中的数据可视化 matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地进行制图.而且也可以方便地将它作为绘图控件. 实战小程序:画出y=x^3的散点图 样例代码如下: #coding=utf-8 import pylab as y #引入pylab模块 x = y.np.linspace(-10, 10, 100) #设置x横坐标范围和点数 y.plot(x, x*x*x,'or') #生成图像 ax = y.gca() a
-
python实战之实现excel读取、统计、写入的示例讲解
背景 图像领域内的一个国内会议快要召开了,要发各种邀请邮件,之后要录入.统计邮件回复(参会还是不参会等).如此重要的任务,老师就托付给我了.ps: 统计回复邮件的时候,能知道谁参会或谁不参会. 而我主要的任务,除了录入邮件回复,就是统计理事和普通会员的参会情况了(参会的.不参会的.没回复的).录入邮件回复信息没办法只能人工操作,但如果统计也要人工的话,那工作量就太大了(比如在上百人的列表中搜索另外上百人在不在此列表中!!),于是就想到了用python来帮忙,花两天时间不断修改,写了6个版本...