Python datacompy 找出两个DataFrames不同的地方
本篇博客解决在两个几乎完全相同的DataFrame当中如何找出不相同的元素,并使用datacompy直观的显示出来。
x表:
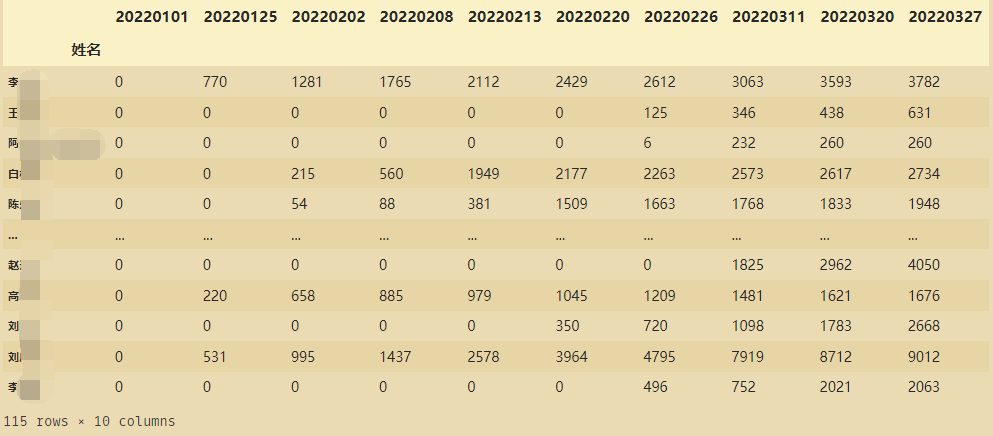
让x1和x2都是x的副本,则此时x1和x2的值是相同:
x1=x.copy() x2=x.copy()
将其中x2的一个数据赋值为2000
x2.loc['罗梓烜']['20220125']=2000
x1[x1==x2].head(25) # 如何对不相等的数据进行纠正
此时可以看到下图这个数据是NaN值,说明对于这个数据来说x1和x2是不相同的
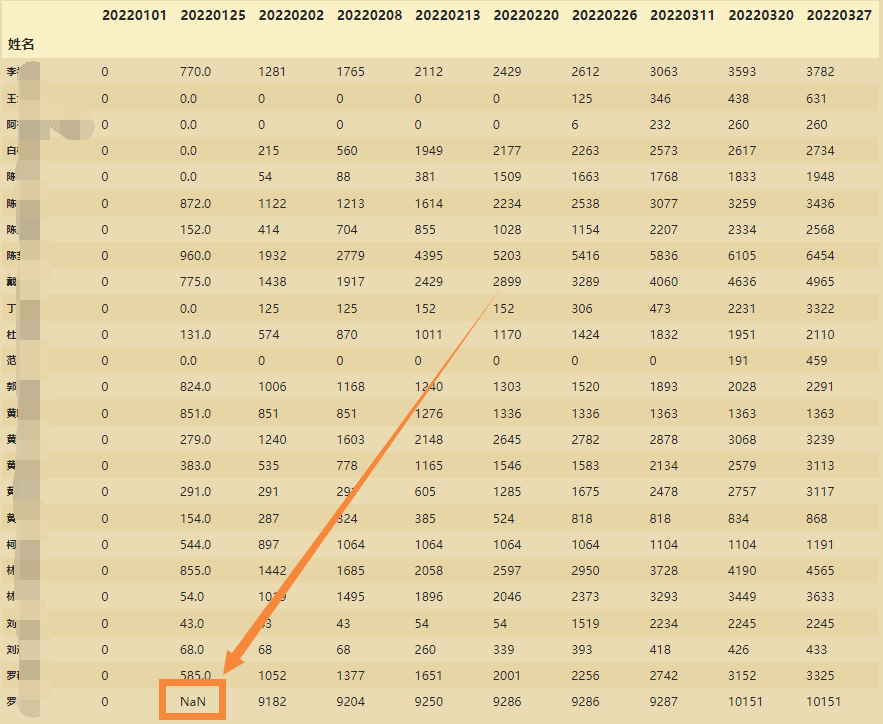
x1[x1==x2].isnull().sum()
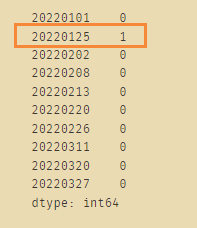
下图说明在20220125这一列当中存在一个NaN值,也就是我们刚刚赋值的地方:
但是现在还是不能确定出有异常值(也就是不相等的值的那行数据),因此我们考虑使用datacompy
安装:
pip install datacompy
import datacompy,pandas as pd,sys compy=datacompy.Compare(x1,x2,on_index=True) compy print(compy.matches()) print(compy.report())
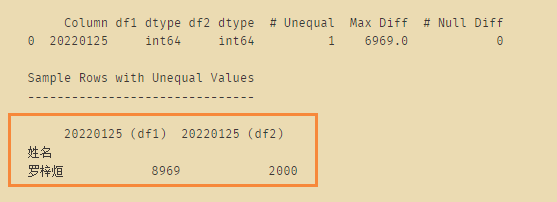
此时就可以很清晰的看到两个DataFrame当中不相同的值了:
到此这篇关于Python datacompy 找出两个DataFrames不同的地方 的文章就介绍到这了,更多相关Python 两个Dataframe不同内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python pandas.DataFrame.loc函数使用详解
官方函数 DataFrame.loc Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs are: # 可以接受单个的label,多个label的列表,多个label的切片 A singl
-
Python DataFrame.groupby()聚合函数,分组级运算
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个键(可以是函数.数组或DataFrame列名)拆分pandas对象.计算分组摘要统计,如计数.平均值.标准差,或用户自定义函数.对DataFrame的列应用各种各样的函数.应用组内转换或其他运算,如规格化.线性回归.排名或选取子集等.计算透视表或交叉表.执行分位数分析以及其他分组分析. groupby分组函数: 返回值:返回重构格式的DataFrame,特别注意,grou
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
python 创建一个空dataframe 然后添加行数据的实例
实例如下所示: import pandas as pd import re import math dframe1 = pd.read_excel("window regulator分析报告数据对比源.xlsx", sheetname="Sheet1") #读取数据 dframe2 = pd.read_excel("window regulator分析报告数据对比源.xlsx", sheetname="Sheet2")# df
-
python之DataFrame实现excel合并单元格
在工作中经常遇到需要将数据输出到excel,且需要对其中一些单元格进行合并,比如如下表表格,需要根据A列的值,合并B.C列的对应单元格 pandas中的to_excel方法只能对索引进行合并,而xlsxwriter中,虽然提供有merge_range方法,但是这只是一个和基础的方法,每次都需要编写繁琐的测试才能最终调好,而且不能很好的重用.所以想自己写一个方法,结合dataframe和merge_range.大概思路是: 1.定义一个MY_DataFrame类,继承DataFrame类,这样能很
-
Python将DataFrame的某一列作为index的方法
下面代码实现了将df中的column列作为index df.set_index(["Column"], inplace=True) 以上这篇Python将DataFrame的某一列作为index的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 对Python中DataFrame按照行遍历的方法 使用DataFrame删除行和列的实例讲解 Python中的index()方法使用教程 Python中List.index()方法的使用
-
python DataFrame获取行数、列数、索引及第几行第几列的值方法
1.df=DataFrame([{'A':'11','B':'12'},{'A':'111','B':'121'},{'A':'1111','B':'1211'}]) print df.columns.size#列数 2 print df.iloc[:,0].size#行数 3 print df.ix[[0]].index.values[0]#索引值 0 print df.ix[[0]].values[0][0]#第一行第一列的值 11 print df.ix[[1]].values[0][1]
-
Python pandas.DataFrame 找出有空值的行
0.摘要 pandas中DataFrame类型中,找出所有有空值的行,可以使用.isnull()方法和.any()方法. 1.找出含有空值的行 方法:DataFrame[DataFrame.isnull().T.any()] 其中,isnull()能够判断数据中元素是否为空值:T为转置:any()判断该行是否有空值. import pandas as pd import numpy as np n = np.arange(20, dtype=float).reshape(5,4) n[2,3]
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
-

Python datacompy 找出两个DataFrames不同的地方
本篇博客解决在两个几乎完全相同的DataFrame当中如何找出不相同的元素,并使用datacompy直观的显示出来. x表: 让x1和x2都是x的副本,则此时x1和x2的值是相同: x1=x.copy() x2=x.copy() 将其中x2的一个数据赋值为2000 x2.loc['罗梓烜']['20220125']=2000 x1[x1==x2].head(25) # 如何对不相等的数据进行纠正 此时可以看到下图这个数据是NaN值,说明对于这个数据来说x1和x2是不相同的 x1[x1==x2].
-
python 如何快速找出两个电子表中数据的差异
最近刚接触python,找点小任务来练练手,希望自己在实践中不断的锻炼自己解决问题的能力. 公司里会有这样的场景:有一张电子表格的内容由两三个部门或者更多的部门用到,这些员工会在维护这些表格中不定期的跟新一些自己部门的数据,时间久了,大家的数据就开始打架了,非常不利于管理.怎样快速找到两个或者多个电子表格中数据的差异呢? 解决办法: 1. Excel自带的方法(有兴趣的自行百度) 2. python 写一个小脚本 #!/usr/bin/env python # -*- coding: utf-8
-
Python实现找出数组中第2大数字的方法示例
本文实例讲述了Python实现找出数组中第2大数字的方法.分享给大家供大家参考,具体如下: 题目比较简单直接看实现即可,具体的注释在代码中都有: #!usr/bin/env python #encoding:utf-8 ''''' __Author__:沂水寒城 功能:找出数组中第2大的数字 ''' def find_Second_large_num(num_list): ''''' 找出数组中第2大的数字 ''' #直接排序,输出倒数第二个数即可 tmp_list=sorted(num_lis
-
Python pandas找出、删除重复的数据实例
目录 前言 一.duplicated() 二.drop_duplicates() 总结 前言 当我们使用pandas处理数据的时候,经常会遇到数据重复的问题,如何找出重复数据进而分析重复原因,或者如何直接删除重复的数据是一个关键的步骤,pandas提供了很方便的方法:duplicated()和drop_duplicates(). 一.duplicated() duplicated()可以被用在DataFrame的三种情况下,分别是pandas.DataFrame.duplicated.panda
-
python中找出numpy array数组的最值及其索引方法
在list列表中,max(list)可以得到list的最大值,list.index(max(list))可以得到最大值对应的索引 但在numpy中的array没有index方法,取而代之的是where,其又是list没有的 首先我们可以得到array在全局和每行每列的最大值(最小值同理) >>> a = np.arange(9).reshape((3,3)) >>> a array([[0, 1, 2], [9, 4, 5], [6, 7, 8]]) >>&
-
使用Python+wxpy 找出微信里把你删除的好友实例
之前看到好友在发各种"群发"来检验对方是不是把自己删除了,好吧,其实那个没啥用处. 所以决定自己动手做一个 百度了一下,检测是否被删除,总结出大概网上的一些方法 第一种方法: 拉群法 就是拉一定数量的人进群,再审查群里的人是否和拉进群的名单相对,缺失的即已经将你删除(因为删除了你的人你无法拉入群聊),然后再移除这一批好友,再拉进来另一批,这样只要不发信息,也不会对你的好友产生困扰. 但是.... 这个方法是好几年前的了,web微信已经把拉群这个功能去掉了,所以在使用wxpy的add_m
-
Python Dict找出value大于某值或key大于某值的所有项方式
对于一个Dict: test_dict = {1:5, 2:4, 3:3, 4:2, 5:1} 想要求key值大于等于3的所有项: print({k:v for k, v in test_dict.items() if k>=3}) 得到 {3: 3, 4: 2, 5: 1} 想要求value值大于等于3的所有项: print({k:v for k, v in test_dict.items() if v>=3}) {1: 5, 2: 4, 3: 3} 如果想要求k或者v某一个就取一个即可:
-
python opencv 找出图像中的最大轮廓并填充(生成mask)
本文主要介绍了python opencv 找出图像中的最大轮廓并填充,分享给大家,具体如下: import cv2 import numpy as np from PIL import Image from joblib import Parallel from joblib import delayed # Parallel 和 delayed是为了使用多线程处理 # 使用前需要安装joblib:pip install joblib # img_stack的shape为:num, h, w #
-
java实现找出两个文件中相同的单词(两种方法)
java实现找出两个文件中相同的单词,具体代码如下所示: package com.zy.DesignPrinciples.singleresponsibility; import javax.print.DocFlavor; import java.io.BufferedReader; import java.io.FileReader; import java.util.HashSet; /** * @ClassName: ReaderComplete * @Author: Tiger * @
-
js如何找出两个数组中不同的元素
目录 js找出两个数组中不同的元素 js找出两个数组中不同元素和相同元素的几种方法 找出不同元素 找出相同的元素 总结 js找出两个数组中不同的元素 function getNewArr(a,b){ const arr = [...a,...b]; const newArr = arr.filter(item => { return !(a.includes(item) && b.includes(item)); }); return newArr; } console.log(ge