python工具之清理 Markdown 中没有引用的图片
目录
- 灵感来源
- Python
- 如何使用
- 源码
前言:
之前,我写笔记的工具一直都是 notion,而且没有写博客的习惯。但是一是由于 notion 的服务器在国外,有时候很不稳定;二是由于 notion 的分享很不方便,把笔记分享给别人点开链接之后还要先登录才能查看内容。于是我又在 掘金 平台写了几篇随笔,但是掘金的文章无法通过本地 Markdown 上传直接发表,也无法下载之前上传过的文章,这样一来数据不保存在本地,以后迁移文章到别的平台的成本也更高。
后来在 Bilibili up主 TheCW 的推荐下学会使用了 Linux 和 vim,然后就喜欢上了使用 vim 写 Markdown 这种双手不需要离开键盘的感觉。而且博客园也开放了 Metaweblog 接口,可以很方便的将本地的笔记发表到自己的博客园。
灵感来源
使用 vim 写笔记不像 notion 一样,可以随时将不需要的图片删除而不会在本地留下垃圾文件,(typora 没怎么用过,不知道有没有类似的功能)而删除了本地笔记的图片引用之后还是会在文件夹留下垃圾图片残留,之前的做法是每次删除完图片都在文件夹里寻找名字相同的图片之后删除,这种方法低效费时,于是便萌生了写一个自动清理无引用图片小工具的想法。
Python
本着不重复造轮子的原则,我先在国内互联网搜寻了一番(看不懂英语),只看到 其他网站上有人用 java 写了一个类似的工具,但是内容不太看得懂,而且没有提供现成的工具包下载,只有源码。(本人比较懒...)
这种小工具当然还是用 Python 更友好啦~ 而且我是为了写这么一个东西才从头看的 Python,可以说之前对这门语言一无所知,只知道很火...... 小工具只有一个 .py 文件:
# utf-8
如何使用
因为只有一个文件,所以大家花一分钟看下源码大概就知道了,原理极其简单。(一个学了一下午 python 的人能写出什么复杂的东西)
- 将
.py文件 拷贝/移动到自己喜欢的位置,将该路径设置为 环境变量 路径,或者使用软链接到/usr/bin目录下 - 因为能力有限且开发时间较短,工作目录必须严格遵循以下形式(未来可能会优化)
. ├── imgs │ ├── a.jpg │ ├── b.png │ └── c.png ├── list.md ├── note.md └── time.md

这里的意思是说:所有的 Markdown 文件需要位于当前目录下,而所有的图片文件需要位于
./imgs路径下 (图片文件夹的名字可以是任意,不是必须叫imgs)
移动到你想要清理无引用图片的上级目录(该目录下应该有 a.md b.md ...... imgs/),例如我这里有一个从 Notion 上下载下来的 Vue 笔记,但是我不小心在里面加了许多其他没用的图片,现在想删掉这些图片

该目录下只有一个 Vue-notion.md 和一个放有图片的文件夹 vuedir
使用:
python $APP_HOME/img-cleaner.py # 原谅我这种愚蠢的写法
这里会提示需要你输入放置图片文件夹的名称:
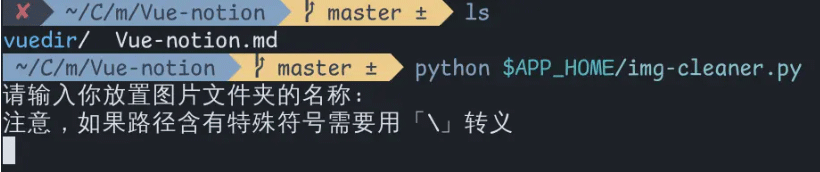
输入之后按回车:
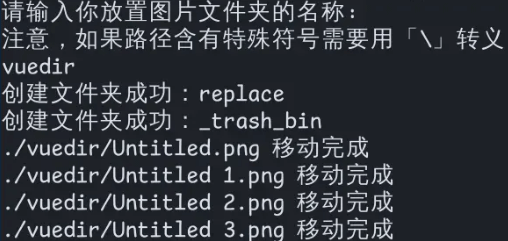
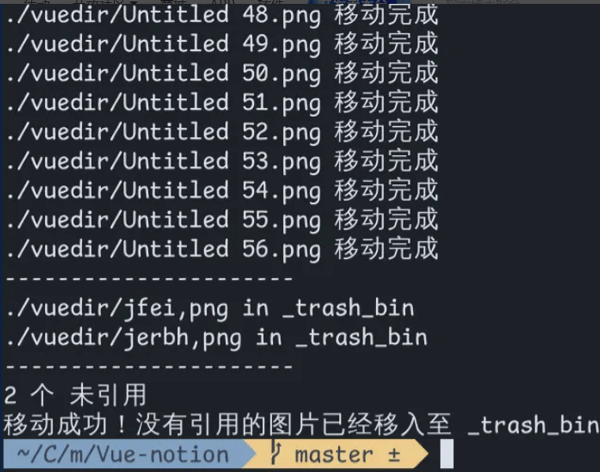
没有引用过的图片就会被移动到 ./_trash_bin 目录下
注意点:
- 每行最多包含一个图片标签
![](),因为没有关闭正则的贪婪匹配,如果多个图片写在一行的话则会报错 2022-6-2 更新:所引用图片的文件名可以带 空格符 ,代码会自动将 Markdown 内引用路径的文件名中的%20转码为 空格符,不过只允许在文件名中出现一次 空格符
源码
# -*-coding:utf-8 -*-
import re
import shutil
import os
# 获取工作路径
print("请输入你放置图片文件夹的名称: ")
print("注意,如果路径含有特殊符号需要用「\」转义")
_input = input()
# 创建 replace _trash_bin文件夹
if os.path.exists('./replace') == False:
os.mkdir('./replace')
print("创建文件夹成功:replace")
else:
raise Exception("请删除当前目录下的 replace 文件夹后重试")
if os.path.exists('./_trash_bin') == False:
os.mkdir('./_trash_bin')
print("创建文件夹成功:_trash_bin")
else:
raise Exception("请删除当前目录下的 _trash_bin 文件夹后重试")
# 撰写正则表达式
# pattern = re.compile('\(.*img\/.*\..*\)')
# pattern = re.compile('\(' + _input + '\/.*\..*\)')
pattern = re.compile('\!\[.*\]\(' + _input + '\/.*\)')
# 创建需要被移动的文件列表
find_list = []
# 获取当前路径下的 .md 文件
md_finder = os.listdir('./')
md_list = []
for item in md_finder:
# 寻找 markdown 文件
if item.endswith('.md') == True:
md_list.append(item)
# 逐个读取 .md 文件
for md_item in md_list:
f = open(md_item)
md_str = f.read()
f.close()
result = pattern.findall(md_str)
for i in range(len(result)):
# 将图片路径逐个添加至 find_list
index = result[i].find("]")
# 将拿到的原始图片路径加工成 ./<imgs_name>/xxx.png 的形式
add_item = "./" + _input + "/" + result[i][index + 3 + len(_input): len(result[i]) - 1]
space_index = add_item.find("%20")
# 如果路径中存在 空格符
if space_index != -1:
add_item = add_item[0: space_index] + " " + add_item[space_index + 3:]
# 将图片路径添加至 find_list
find_list.append(add_item)
# 将所有 markdown中 引用过路径的图片移动至 ./replace
for item in find_list:
shutil.move(item, './replace')
print(item + " 移动完成")
print("----------------------")
# 将没有引用的图片移至 _trash_bin
img_trashs = os.listdir('./' + _input)
trash_flag = 0
for item_trash in img_trashs:
item_trash = "./" + _input + "/" + item_trash
trash_flag = trash_flag + 1
shutil.move(item_trash, './_trash_bin')
print(item_trash + " in _trash_bin")
print("----------------------")
# 删除原本的 img 文件夹,并更改文件夹名称
os.removedirs('./' + _input + '/')
os.rename('./replace', _input)
print(str(trash_flag) + " 个 未引用")
print("移动成功!没有引用的图片已经移入至 _trash_bin")
到此这篇关于python工具之清理 Markdown 中没有引用的图片的文章就介绍到这了,更多相关python Markdown 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实战之markdown转pdf(包含公式转换)
目录 一.Pandoc转换 1.1 问题 1.2 下载 1.3 md转docx 1.4 md转pdf 二.python库实现 2.1 安装 wkhtmltopdf 2.2 安装 mdutils 2.3 引入数学公式 2.4 网页转pdf 2.5 进度条转换 一.Pandoc转换 1.1 问题 由于我们markdown编辑器比较特殊,一般情况下,我们不太好看,如果转换成pdf的话,我们就不需要可以的去安装各种编辑器才可以看了,所以我们有了md转pdf或者是docx的需求. 1.2 下载 资源地址
-
Python实现Word文档转换Markdown的示例
随着SaaS服务的流行,越来越多的人选择在各个平台上编写文档,制作表格并进行分享. 同时,随着Markdown语法的破圈,很多平台开始集成支持这种简洁的书写标记语言,这样可以保证平台上用户文档样式的统一性. 但是在一些场景下,我们还是会在本地的Office软件上写有很多文档,或者历史遗留了很多本地文档. 如果我们需要将其上传到各大平台,直接复制粘贴,大概率是会造成文档内容结构和样式的丢失.于此我们需要将其转换为 Markdown 语法. 很多桌面软件(比如Typora)都提供了导入 Word 文
-
Python3自动生成MySQL数据字典的markdown文本的实现
为啥要写这个脚本 五一前的准备下班的时候,看到同事为了做数据库的某个表的数据字典,在做一个复杂的人工操作,就是一个字段一个字段的纯手撸,那速度可想而知是多么的折磨和锻炼人的意志和耐心,反正就是很耗时又费力的活,关键是工作效率太低了,于是就网上查了一下,能否有在线工具可用,但是并没有找到理想和如意的,于是吧,就干脆自己撸一个,一劳永逸,说干就干的那种-- 先屡一下脚本思路 第一步:输入或修改数据库连接配置信息,以及输入数据表名 第二步:利用pymysql模块连接数据库,并判断数据表是否存在 第三步
-
Python爬虫爬取微博热搜保存为 Markdown 文件的源码
什么是爬虫? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫. 其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据 爬虫可以做什么? 你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到. 爬虫的本质是什么? 上面关于爬虫可以做什么,定义了一个前提
-
Python实现截图生成符合markdown的链接
目录 背景 思路 实现 背景 之前是用的是typora来写的文章,最近typora最近开始收费了,所以就不想用了,于是找到了一个替代品MarkText,感觉跟typora差不多 整体样子就像上面,简约风,个人挺喜欢的.唯一的一个问题就是粘贴图片的时候,图片只能放在本地,虽然marktext有图片上传的功能,但是只支持GitHub的图床,设置了过后经常会上传失败,导致还是存在本地,存在本地的弊端就是文章在转移的需要把图片都带上或者复制到掘金等平台的时候,图片会失效.于是打算用python写个自动生
-
获取CSDN文章内容并转换为markdown文本的python
自己写的小工具,可以直接获取csdn文章并转换为markdown格式 效果图 核心代码 from PySide2.QtWidgets import QApplication,QMainWindow,QPushButton,QPlainTextEdit,QMessageBox import re import parsel import tomd import requests class CSDN(): def __init__(self): self.windows = QMainWindow
-
python使用html2text库实现从HTML转markdown的方法详解
如果PyPi上搜html2text的话,找到的是另外一个库:Alir3z4/html2text.这个库是从aaronsw/html2text fork过来,并在此基础上对功能进行了扩展.因此是直接用pip安装的,因此本文主要来讲讲这个库. 首先,进行安装: pip install html2text 命令行方式使用html2text 安装完后,就可以通过命令html2text进行一系列的操作了. html2text命令使用方式为:html2text [(filename|url) [encodi
-
python工具之清理 Markdown 中没有引用的图片
目录 灵感来源 Python 如何使用 源码 前言: 之前,我写笔记的工具一直都是 notion,而且没有写博客的习惯.但是一是由于 notion 的服务器在国外,有时候很不稳定:二是由于 notion 的分享很不方便,把笔记分享给别人点开链接之后还要先登录才能查看内容.于是我又在 掘金 平台写了几篇随笔,但是掘金的文章无法通过本地 Markdown 上传直接发表,也无法下载之前上传过的文章,这样一来数据不保存在本地,以后迁移文章到别的平台的成本也更高.后来在 Bilibili up主 TheC
-
Python一键查找iOS项目中未使用的图片、音频、视频资源
前言 在iOS项目开发的过程中,如果版本迭代开发的时间比较长,那么在很多版本开发以后或者说有多人开发参与以后,工程中难免有一些垃圾资源,未被使用却占据着api包的大小! 这里我通过Python脚本来查找项目中未被使用的图片.音频.视频资源,然后删除掉:以达到减小APP包大小的目的! 代码 先查找项目中所以的资源文件存到你数组里面 def searchAllResName(file_dir): global _resNameMap fs = os.listdir(file_dir) for dir
-
python如何实现从视频中提取每秒图片
我是在做行人检测中需要将一段视频变为图片数据集,然后想将视频每秒钟的图片提取出来. 语言:python 所需要的库:cv2,numpy (自行安装) opencv中提供了读取视频每帧图片的函数,下面的代码可以将视频的每帧图片提取出来.注:我的视频名字叫 2.mp4 ,提取图片保存目录 需要自己建一个名字叫 output 的文件夹. # 导入所需要的库 import cv2 import numpy as np # 定义保存图片函数 # image:要保存的图片名字 # addr:图片地址与相片
-
基于Python编写微信清理工具的示例代码
目录 主要功能 运行环境 核心代码 完整代码 前几天网上找了一款 PC 端微信自动清理工具,用了一下,电脑释放了 30GB 的存储空间,而且不会删除文字的聊天记录,很好用,感觉很多人都用得到,就在此分享一下,而且是用 Python 写的,喜欢 Python 的小伙伴可以探究一下. 主要功能 它可以自动删除 PC 端微信自动下载的大量文件.视频.图片等数据内容,释放几十 G 的空间占用,而且不会删除文字的聊天记录,可以放心使用. 工作以后,微信的群聊实在太多了,动不动就被拉入一个群中,然后群聊里大
-
Python中的引用知识点总结
本篇介绍Python中的引用. 首先想一想如图示例. 在python中,值是靠引用来传递来的. 用id()来判断两个变量是否为同一个值的引用.如图. 图解引用.如图. 可变类型与不可变类型.如图.
-
Python中的引用和拷贝实例解析
这篇文章主要介绍了python中的引用和拷贝实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.引用 a = ['a', 'b', 'c'] b = a print(id(a)) print(id(b)) 135300560 135300560 可以看到,变量a 和 b 的 id是完全一样的,这就说明a和b是同时指向内存的同一个区域的,即b随a的变化而变化. a = ['a', 'b', 'c'] b = a a[1] = 'd' pr
-
Python中的引用与copy介绍
目录 Python中的引用和copy 1.引用整型数据及列表 2.传递引用 3.copy模块中的copy()和deepcopy() Python中的引用和copy 1.引用整型数据及列表 这里以整型数据类型及列表为例 对于赋值字符串.整型.元组等不可更改数据的变量,其保存的仅是值,改变新变量中的值并不会影响原来变量中的值 origin = 1 new = origin print("new = ",new) new = 2 print("origin = ",ori
-
python游戏测试工具自动化遍历游戏中所有关卡
目录 场景 思路 实现细节 1.卡住的判定和处理 2.GAutomator 调用游戏内部的 GM 指令 unity 中: python 中: 3.最终输出的报告 详细代码 AutoBattleTest.py 用来实现核心逻辑 ExcelTool.py 用来读写表格 后记 场景 游戏里有很多关卡(可能有几百个了),理论上每次发布到外网前都要遍历各关卡看看会不会有异常,上次就有玩家在打某个关卡时卡住不动了,如果每个关卡要人工遍历这样做会非常的耗时,所以考虑用自动化的方式来实现. 思路 游戏的战斗是有
-
Python实现删除排序数组中重复项的两种方法示例
本文实例讲述了Python实现删除排序数组中重复项的两种方法.分享给大家供大家参考,具体如下: 对于给定的有序数组nums,移除数组中存在的重复数字,确保每个数字只出现一次并返回新数组的长度 注意:不能为新数组申请额外的空间,只允许申请O(1)的额外空间修改输入数组 Example 1: Given nums = [1,1,2], Your function should return length = 2, with the first two elements of nums being 1
-
Python实现自动清理电脑垃圾文件详解
经常存在在我们的电脑中的垃圾文件主要是指系统在运行过程中产生的tmp临时文件.日志文件.临时备份文件等.垃圾清理器的作用其实也是对这些文件进行清理,不会影响到我们使用产生的数据文件.如果是手动删除的话要一个一个的找出来去删除就比较麻烦了,用python写一个脚本直接启动就大功告成了. 在这个脚本的实现过程中使用到的内置库就是os库,没有通过其他的三方插件进行实现.所以也不用下载其他的python模块,直接调用内置库就OK了. import os 因为我们使用界面化的处理,这里导入一下pyqt5的