解析Tensorflow之MNIST的使用
要说2017年什么技术最火爆,无疑是google领衔的深度学习开源框架Tensorflow。本文简述一下深度学习的入门例子MNIST。
深度学习简单介绍
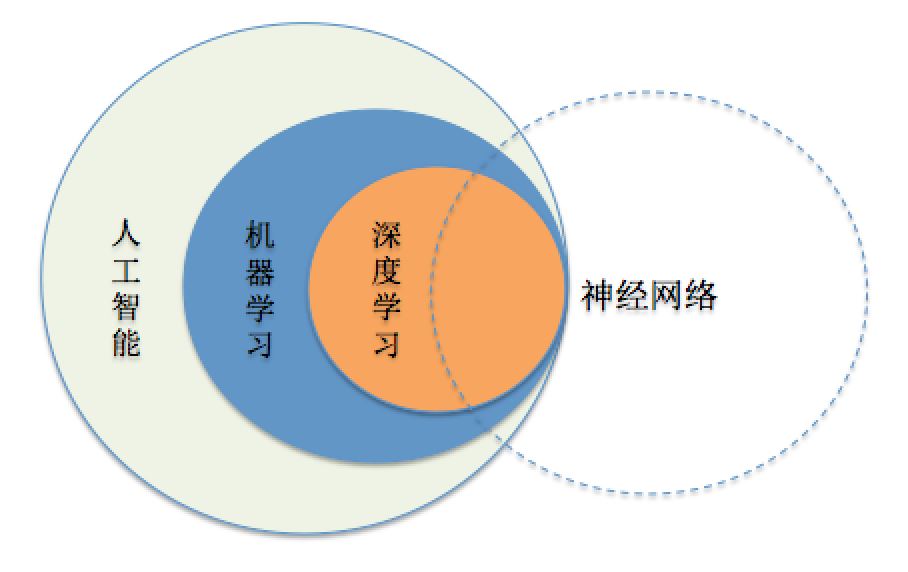
首先要简单区别几个概念:人工智能,机器学习,深度学习,神经网络。这几个词应该是出现的最为频繁的,但是他们有什么区别呢?
人工智能:人类通过直觉可以解决的问题,如:自然语言理解,图像识别,语音识别等,计算机很难解决,而人工智能就是要解决这类问题。
机器学习:如果一个任务可以在任务T上,随着经验E的增加,效果P也随之增加,那么就认为这个程序可以从经验中学习。
深度学习:其核心就是自动将简单的特征组合成更加复杂的特征,并用这些特征解决问题。
神经网络:最初是一个生物学的概念,一般是指大脑神经元,触点,细胞等组成的网络,用于产生意识,帮助生物思考和行动,后来人工智能受神经网络的启发,发展出了人工神经网络。
来一张图就比较清楚了,如下图:
MNIST解析
MNIST是深度学习的经典入门demo,他是由6万张训练图片和1万张测试图片构成的,每张图片都是28*28大小(如下图),而且都是黑白色构成(这里的黑色是一个0-1的浮点数,黑色越深表示数值越靠近1),这些图片是采集的不同的人手写从0到9的数字。TensorFlow将这个数据集和相关操作封装到了库中,下面我们来一步步解读深度学习MNIST的过程。

上图就是4张MNIST图片。这些图片并不是传统意义上.jpg或者jpg格式的图片,因.jpg或者jpg的图片格式,会带有很多干扰信息(如:数据块,图片头,图片尾,长度等等),这些图片会被处理成很简易的二维数组,如图:
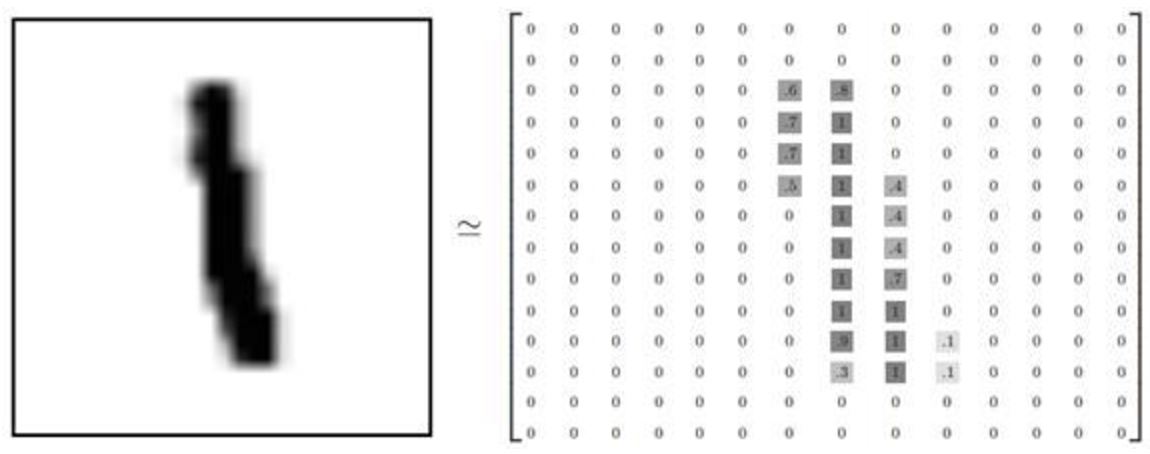
可以看到,矩阵中有值的地方构成的图形,跟左边的图形很相似。之所以这样做,是为了让模型更简单清晰。特征更明显。
我们先看模型的代码以及如何训练模型:
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
# x是特征值
x = tf.placeholder(tf.float32, [None, 784])
# w表示每一个特征值(像素点)会影响结果的权重
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + b
# 是图片实际对应的值
y_ = tf.placeholder(tf.float32, [None, 10])<br>
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# mnist.train 训练数据
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
#取得y得最大概率对应的数组索引来和y_的数组索引对比,如果索引相同,则表示预测正确
correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
首先第一行是获取MNIST的数据集,我们逐一解释一下:
x(图片的特征值):这里使用了一个28*28=784列的数据来表示一个图片的构成,也就是说,每一个点都是这个图片的一个特征,这个其实比较好理解,因为每一个点都会对图片的样子和表达的含义有影响,只是影响的大小不同而已。至于为什么要将28*28的矩阵摊平成为一个1行784列的一维数组,我猜测可能是因为这样做会更加简单直观。
W(特征值对应的权重):这个值很重要,因为我们深度学习的过程,就是发现特征,经过一系列训练,从而得出每一个特征对结果影响的权重,我们训练,就是为了得到这个最佳权重值。
b(偏置量):是为了去线性话(我不是太清楚为什么需要这个值)
y(预测的结果):单个样本被预测出来是哪个数字的概率,比如:有可能结果是[ 1.07476616 -4.54194021 2.98073649 -7.42985344 3.29253793 1.967506178.59438515 -6.65950203 1.68721473 -0.9658531 ],则分别表示是0,1,2,3,4,5,6,7,8,9的概率,然后会取一个最大值来作为本次预测的结果,对于这个数组来说,结果是6(8.59438515)
y_(真实结果):来自MNIST的训练集,每一个图片所对应的真实值,如果是6,则表示为:[0 0 0 0 0 1 0 0 0]
再下面两行代码是损失函数(交叉熵)和梯度下降算法,通过不断的调整权重和偏置量的值,来逐步减小根据计算的预测结果和提供的真实结果之间的差异,以达到训练模型的目的。
算法确定以后便可以开始训练模型了,如下:
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
mnist.train.next_batch(100)是从训练集里一次提取100张图片数据来训练,然后循环1000次,以达到训练的目的。
之后的两行代码都有注释,不再累述。我们看最后一行代码:
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
mnist.test.images和mnist.test.labels是测试集,用来测试。accuracy是预测准确率。
当代码运行起来以后,我们发现,准确率大概在92%左右浮动。这个时候我们可能想看看到底是什么样的图片让预测不准。则添加如下代码:
for i in range(0, len(mnist.test.images)):
result = sess.run(correct_prediction, feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])})
if not result:
print('预测的值是:',sess.run(y, feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])}))
print('实际的值是:',sess.run(y_,feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])}))
one_pic_arr = np.reshape(mnist.test.images[i], (28, 28))
pic_matrix = np.matrix(one_pic_arr, dtype="float")
plt.imshow(pic_matrix)
pylab.show()
break
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
for循环内指明一旦result为false,就表示出现了预测值和实际值不符合的图片,然后我们把值和图片分别打印出来看看:
预测的值是: [[ 1.82234347 -4.87242508 2.63052988 -6.56350136 2.73666072 2.30682945 8.59051228 -7.20512581 1.45552373 -0.90134078]]
对应的是数字6。
实际的值是: [[ 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]]
对应的是数字5。
我们再来看看图片是什么样子的:

的确像5又像6。
总体来说,只有92%的准确率,还是比较低的,后续会解析一下比较适合识别图片的卷积神经网络,准确率可以达到99%以上。
一些体会与感想
我本人是一名iOS开发,也是迎着人工智能的浪潮开始一路学习,我觉得人工智能终将改变我们的生活,也会成为未来的一个热门学科。这一个多月的自学下来,我觉得最为困难的是克服自己的畏难情绪,因为我完全没有AI方面的任何经验,而且工作年限太久,线性代数,概率论等知识早已还给老师,所以在开始的时候,总是反反复复不停犹豫,纠结到底要不要把时间花费在研究深度学习上面。但是后来一想,假如我不学AI的东西,若干年后,AI发展越发成熟,到时候想学也会难以跟上步伐,而且,让电脑学会思考这本身就是一件很让人兴奋的事情,既然想学,有什么理由不去学呢?与大家共勉。
参考文章:
https://zhuanlan.zhihu.com/p/25482889
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap1/c1s0.html
到此这篇关于解析Tensorflow之MNIST的使用的文章就介绍到这了,更多相关Tensorflow MNIST内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
基于TensorFlow的CNN实现Mnist手写数字识别
本文实例为大家分享了基于TensorFlow的CNN实现Mnist手写数字识别的具体代码,供大家参考,具体内容如下 一.CNN模型结构 输入层:Mnist数据集(28*28) 第一层卷积:感受视野5*5,步长为1,卷积核:32个 第一层池化:池化视野2*2,步长为2 第二层卷积:感受视野5*5,步长为1,卷积核:64个 第二层池化:池化视野2*2,步长为2 全连接层:设置1024个神经元 输出层:0~9十个数字类别 二.代码实现 import tensorflow as tf #Tensorfl
-
Tensorflow训练MNIST手写数字识别模型
本文实例为大家分享了Tensorflow训练MNIST手写数字识别模型的具体代码,供大家参考,具体内容如下 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_NODE = 784 # 输入层节点=图片像素=28x28=784 OUTPUT_NODE = 10 # 输出层节点数=图片类别数目 LAYER1_NODE = 500 # 隐藏层节点数,只有一个隐藏层 BATCH
-
tensorflow实现KNN识别MNIST
KNN算法算是最简单的机器学习算法之一了,这个算法最大的特点是没有训练过程,是一种懒惰学习,这种结构也可以在tensorflow实现. KNN的最核心就是距离度量方式,官方例程给出的是L1范数的例子,我这里改成了L2范数,也就是我们常说的欧几里得距离度量,另外,虽然是叫KNN,意思是选取k个最接近的元素来投票产生分类,但是这里只是用了最近的那个数据的标签作为预测值了. __author__ = 'freedom' import tensorflow as tf import numpy as n
-
使用tensorflow实现VGG网络,训练mnist数据集方式
VGG作为流行的几个模型之一,训练图形数据效果不错,在mnist数据集是常用的入门集数据,VGG层数非常多,如果严格按照规范来实现,并用来训练mnist数据集,会出现各种问题,如,经过16层卷积后,28*28*1的图片几乎无法进行. 先介绍下VGG ILSVRC 2014的第二名是Karen Simonyan和 Andrew Zisserman实现的卷积神经网络,现在称其为VGGNet.它主要的贡献是展示出网络的深度是算法优良性能的关键部分. 他们最好的网络包含了16个卷积/全连接层.网络的结构
-
tensorflow mnist 数据加载实现并画图效果
关于 TensorFlow TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor).它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等.TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度
-
基于Tensorflow的MNIST手写数字识别分类
本文实例为大家分享了基于Tensorflow的MNIST手写数字识别分类的具体实现代码,供大家参考,具体内容如下 代码如下: import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data from tensorflow.contrib.tensorboard.plugins import projector import time IMAGE_PIXELS
-
tensorflow使用神经网络实现mnist分类
本文实例为大家分享了tensorflow神经网络实现mnist分类的具体代码,供大家参考,具体内容如下 只有两层的神经网络,直接上代码 #引入包 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #引入input_data文件 from tensorflow.examples.tutorials.mnist import input_data #读取文件 mnist = input_data.re
-
tensorflow学习笔记之mnist的卷积神经网络实例
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的.但是CNN层数要多一些,网络模型需要自己来构建. 程序比较复杂,我就分成几个部分来叙述. 首先,下载并加载数据: import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=Tru
-
tensorflow实现softma识别MNIST
识别MNIST已经成了深度学习的hello world,所以每次例程基本都会用到这个数据集,这个数据集在tensorflow内部用着很好的封装,因此可以方便地使用. 这次我们用tensorflow搭建一个softmax多分类器,和之前搭建线性回归差不多,第一步是通过确定变量建立图模型,然后确定误差函数,最后调用优化器优化. 误差函数与线性回归不同,这里因为是多分类问题,所以使用了交叉熵. 另外,有一点值得注意的是,这里构建模型时我试图想拆分多个函数,但是后来发现这样做难度很大,因为图是在规定变量
-

tensorflow实现加载mnist数据集
mnist作为最基础的图片数据集,在以后的cnn,rnn任务中都会用到 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.examples.tutorials.mnist import input_data #数据集存放地址,采用0-1编码 mnist = input_data.read_data_sets('F:/mnist/data/',one_hot = Tr
-
使用TensorFlow直接获取处理MNIST数据方式
MNIST是一个非常有名的手写体数字识别数据集,TensorFlow对MNIST数据集做了封装,可以直接调用.MNIST数据集包含了60000张图片作为训练数据,10000张图片作为测试数据,每一张图片都代表了0-9中的一个数字,图片大小都是28*28.虽然这个数据集只提供了训练和测试数据,但是为了验证训练网络的效果,一般从训练数据中划分出一部分数据作为验证数据,测试神经网络模型在不同参数下的效果.TensorFlow提供了一个类来处理MNIST数据. 代码如下: from tensorflow
-
TensorFlow MNIST手写数据集的实现方法
MNIST数据集介绍 MNIST数据集中包含了各种各样的手写数字图片,数据集的官网是:http://yann.lecun.com/exdb/mnist/index.html,我们可以从这里下载数据集.使用如下的代码对数据集进行加载: from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) 运行上述代码会自动下载数