基于Python快速处理PDF表格数据
我们有下面一张PDF格式存储的表格,现在需要使用Python将它提取出来。
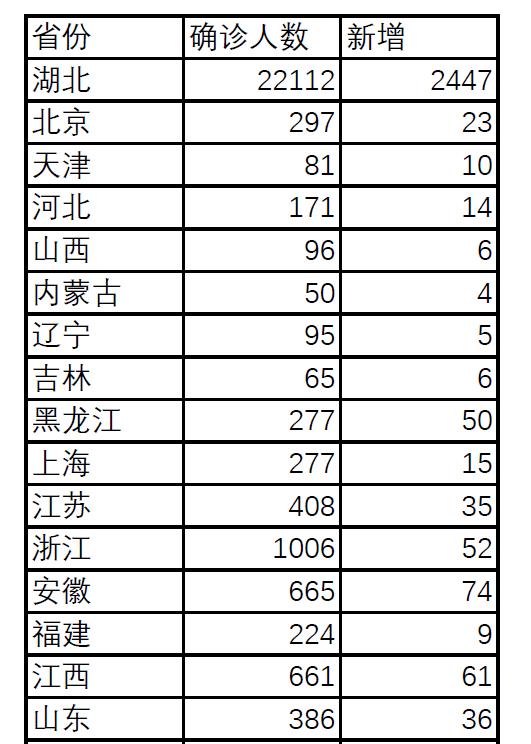
使用Python提取表格数据需要使用pdfplumber模块,打开CMD,安装代码如下:
pip install pdfplumber
安装完之后,将需要使用的模块导入
import pdfplumberimport pandas as pd
然后打开PDF文件
# 使用with语句打开pdf文件
with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf:
# pages[0]表示取第1页
page = pdf.pages[0]
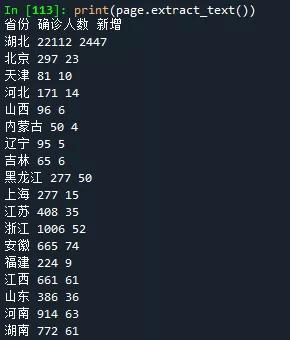
我们来打印输出下获取到的文本,这句语句只是帮我们验证下是否成功获取到PDF里的内容
print(page.extract_text())
执行的结果如下,看来是成功了
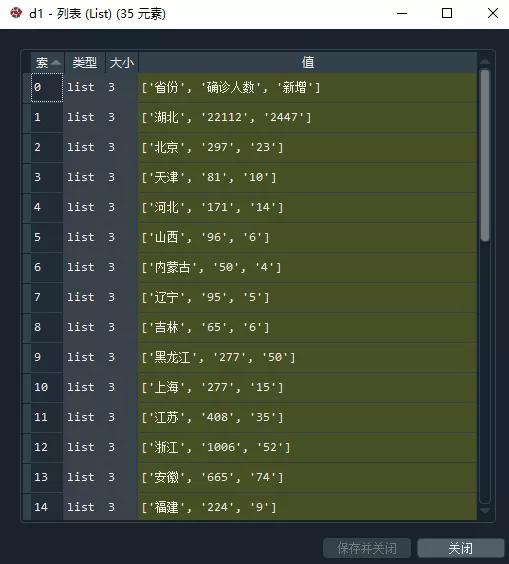
然后可以使用extract_table()函数获取表格,如果有多个表格,可以使用extract_tables()函数,就是多了个s
d1=page.extract_table()
执行代码后,将得到一个列表,还不是数据框
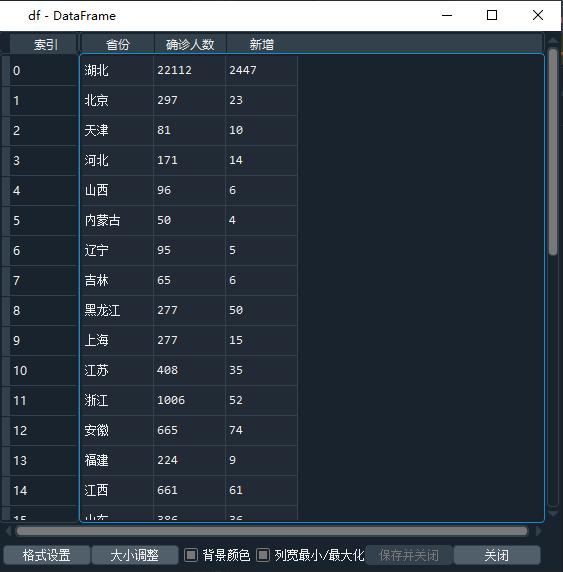
所以最后一步就是将列表转为数据框就可以了,代码如下:
df = pd.DataFrame(d1[1:], columns=d1[0])
执行代码后,将得到了df数据框
有几个注意事项要提醒下:
1.pdf表格中的数据,对于同一个数据或内容,不要有换行,如果换行,可能被识别为2个数据;
2.pdf中的表格一定要有边框,没有边框的话,否则使用extract_table()函数就无法获取表格数据,extract_text()还是可以获取文本信息的,不要问我是怎么知道的,说多了都是泪。
我们现在有一份PDF数据,里面有三页,每页都有一样数据结构但数据不同的数据表,现在需要使用Python将它批量提取出来。
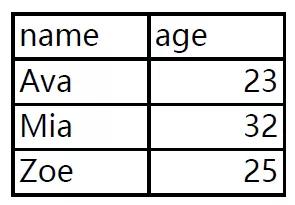
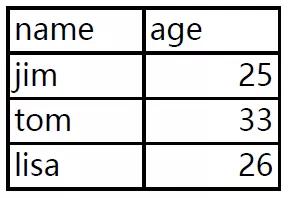
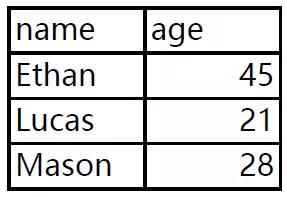
有了上回经验,我们就直接上代码:
import pdfplumber
import pandas as pd
# 创建一个空数据框
df = pd.DataFrame()
# 使用with语句打开pdf文件
with pdfplumber.open("D:\\python\\cai\\5.pdf") as pdf:
# 使用for循环遍历每个pages
for page in pdf.pages:
# 取出当前页表格,结果为列表
d=page.extract_table()
# 将列表转为数据框
df1 = pd.DataFrame(d[1:], columns=d[0])
#添加至df数据框中
df = df.append(df1)
执行代码后,将得到了df数据框
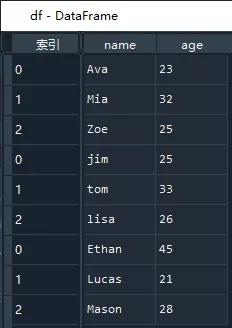
是不是so easy 呢?
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python如何把多个PDF文件合并代码实例
这篇文章主要介绍了Python如何把多个PDF文件合并,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 from PyPDF2 import PdfFileMerger import os files = os.listdir()#列出目录中的所有文件 merger = PdfFileMerger() for file in files: #从所有文件中选出pdf文件合并 if file[-4:] == ".pdf": mer
-
Python利用PyPDF2库获取PDF文件总页码实例
Python中可以利用PyPDF2库来获取该pdf文件的总页码,可以根据下面的方法一步步进行下去: 1.首先,要安装PyPDF2库,利用以下命令即可: pip install PyPDF2 2.接着,就是直接编写代码了,其中我新建了一个py文件,名为file_utils.py,代码如下: from PyPDF2 import PdfFileReader def get_num_pages(file_path): """ 获取文件总页码 :param file_path: 文件
-

Python 用三行代码提取PDF表格数据
从 PDF 表格中获取数据是一项痛苦的工作.不久前,一位开发者提供了一个名为 Camelot 的工具,使用三行代码就能从 PDF 文件中提取表格数据. PDF 文件是一种非常常用的文件格式,通常用于正式的电子版文件.它能够很好的将不同的排版格式固定下来,形成版面清晰且美观的展示效果.然而,对于想要从 PDF 中提取信息的人们来说,PDF 是个噩梦,尤其是表格. 大量的学术报告.论文.分析文章都使用 PDF 展示其中的表格数据,但是对于如果想要直接从表格中复制数据则会非常麻烦.不久前,有一位开发者
-
Python PyPDF2模块安装使用解析
这篇文章主要介绍了Python PyPDF2模块安装使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 PyPDF2模块主要的功能是分割或合并PDF文件,裁剪或转换PDF文件中的页面. 0.安装PyPDF2的模块 pip install PyPDF2 1.常用的函数 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/1/15 13:38 # @Author : suk
-
python如何提取英语pdf内容并翻译
本文实例为大家分享了python提取英语pdf内容并翻译的具体代码,供大家参考,具体内容如下 前期准备工作: 翻译接口: 调用的是百度翻译的api(注册后,每个月有2百万的免费翻译字符数.) pdfminer3k: pdfminer3k是pdfminer的Python 3端口. PDFMiner是一种从PDF文档中提取信息的工具. 与其他PDF相关工具不同,它完全专注于获取和分析文本数据. PDFMiner允许获取页面中文本的确切位置,以及字体或线条等其他信息. 它包括一个PDF转换器,可以将P
-
Python 实现加密过的PDF文件转WORD格式
实现方法简介 许多文件都支持转换为PDF格式,诸如Word,Excel,PowerPoint,Cad以及图片格式.所以pdf从学校到职场,都可以看到pdf文件的身影. 为了保证了文件的安全性,正常情况下无法对pdf的内容进行编辑.但是相应的我们就无法修改pdf的内容,也不便于pdf资料的使用.虽然现在市面上有很多 pdf 转 word 软件,比如 wps,但大多数的软件是要收费的,并且价格不菲.前些天就有人叫我帮她把 pdf 文档转成 word 的文档.因为写尽调报告需要去查看各种信评资料,往往
-
python连接打印机实现打印文档、图片、pdf文件等功能
引言 python连接打印机进行打印,可能根据需求的不同,使用不同的函数模块. 如果你只是简单的想打印文档,比如office文档,你可以使用ShellExecute方法,对于微软office的文档.pdf.txt等有用,你可以尝试下: 如果你输入某些数据,文字信息,就想直接把它发送给打印机打印,那么可以尝试使用win32print: 如果你有一张图片,那么你可以结合python的Python Imaging Library(PIL)和win32ui模块进行打印: 普通打印 ShellExecut
-
Python实现PyPDF2处理PDF文件的方法示例
实际应用中,可能会涉及处理 pdf 文件,PyPDF2 就是这样一个库,使用它可以轻松的处理 pdf 文件,它提供了读,割,合并,文件转换等多种操作. 文档地址:http://pythonhosted.org/PyPDF2/ PyPDF2 安装 PyCharm 安装:File -> Default Settings -> Project Interpreter PdfFileReader 构造方法: PyPDF2.PdfFileReader(stream,strict = True,warnd
-
基于Python快速处理PDF表格数据
我们有下面一张PDF格式存储的表格,现在需要使用Python将它提取出来. 使用Python提取表格数据需要使用pdfplumber模块,打开CMD,安装代码如下: pip install pdfplumber 安装完之后,将需要使用的模块导入 import pdfplumberimport pandas as pd 然后打开PDF文件 # 使用with语句打开pdf文件 with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf: #
-
python pdfplumber库批量提取pdf表格数据转换为excel
目录 需求 一.实现效果图 二.pdfplumber 库 三.代码实现 1.导入相关包 2.读取 pdf , 并获取 pdf 的页数 3.提取单个 pdf 文件,保存成 excel 4.提取文件夹下多个 pdf 文件,保存成 excel 小结 需求 想要提取 pdf 的数据,保存到 excel 中.虽然是可以直接利用 WPS 将 pdf 文件输出成 excel,但这个功能是收费的,而且如果将大量pdf转excel的时候,手动去输出是非常耗时的.我们可以利用 python 的三方工具库 pdfpl
-
python用pdfplumber提取pdf表格数据并保存到excel文件中
目录 pdfplumber操作pdf文件 一.pdfplumber安装及导入 二.pdfplumber基础使用 1.基础知识 2.获取pdf基础信息 3.pdfplumber提取表格数据 三.提取pdf表格数据并保存到excel中 总结 pdfplumber操作pdf文件 python开源库pdfplumber,可以较为方便地获取pdf的各种信息,包含pdf的基本信息(作者.创建时间.修改时间…)及表格.文本.图片等信息,基本可以满足较为简单的格式转换功能. 一.pdfplumber安装及导入
-
基于Python实现一个简易的数据管理系统
目录 创建mysql数据表 增删改查 启动应用 为了方便的实现记录数据.修改数据没有精力去做一个完整的系统去管理数据.因此,在python的控制台直接实现一个简易的数据管理系统,包括数据的增删改查等等.只需要在控制台层面调用相应的功能调用查询.修改等功能,这里记录一下实现过程. 创建mysql数据表 使用比较熟悉的数据库客户端来进行操作,这里使用的是navicate客户端来创建好相应的数据表. 创建数据库并指定编码字符集. CREATE DATABASE `data_boc` CHARACTE
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
Python使用pandas将表格数据进行处理
目录 前言 一.构建es库中的数据 1.1 创建索引 1.2 插入数据 1.3 查询数据 二.对excel表格中的数据处理操作 2.1 导出es查询的数据 前言 任务描述: 当前有一份excel表格数据,里面存在缺失值,需要对缺失的数据到es数据库中进行查找并对其进行把缺失的数据进行补全. excel表格数据如下所示: 一.构建es库中的数据 1.1 创建索引 # 创建physical_examination索引 PUT /physical_examination { "settings&quo
-
Python基于pandas爬取网页表格数据
以网页表格为例:https://www.kuaidaili.com/free/ 该网站数据存在table标签,直接用requests,需要结合bs4解析正则/xpath/lxml等,没有几行代码是搞不定的. 今天介绍的黑科技是pandas自带爬虫功能,pd.read_html(),只需传人url,一行代码搞定. 原网页结构如下: python代码如下: import pandas as pd url='http://www.kuaidaili.com/free/' df=pd.read_html
-
基于Python实现对PDF文件的OCR识别
最近在做一个项目的时候,需要将PDF文件作为输入,从中输出文本,然后将文本存入数据库中.为此,我找寻了很久的解决方案,最终才确定使用tesseract.所以不要浪费时间了,我们开始吧. 1.安装tesseract 在不同的系统中安装tesseract非常容易.为了简便,我们以Ubuntu为例. 在Ubuntu中你仅仅需要运行以下命令: 这将会安装支持3种不同语言的tesseract. 2.安装PyOCR 现在我们还需要安装tesseract的Python接口.幸运的是,有许多出色的Python接
-
基于python实现计算两组数据P值
我们在做A/B试验评估的时候需要借助p_value,这篇文章记录如何利用python计算两组数据的显著性. 一.代码 # TTest.py # -*- coding: utf-8 -*- ''' # Created on 2020-05-20 20:36 # TTest.py # @author: huiwenhua ''' ## Import the packages import numpy as np from scipy import stats def get_p_value(arrA