TensorFlow人工智能学习Keras高层接口应用示例
目录
- 1.metrics
- ①创建Meter
- ②更新数据
- ③获取数据
- ④重置状态
- 2.快捷训练
- ①compile
- ②fit
- ③evaluate
- ④predict
1.metrics
keras.metrics可以用来对数据进行记录跟踪,当我们的数据量太大,又想在中间就看看训练的情况的时候,可以使用此接口。步骤如下:
①创建Meter
通过metrics中带有的借口,创建一个meter。

②更新数据
当我们在某一行代码得到了需要的数据的时候,就可以调用update_state方法,将数据进行更新。注意,不同的方法需要传入的参数是不一样的。

③获取数据
我们可以设置在某个节点或状态的时候,获取当前的meter所存储的数据。

④重置状态
当一个阶段数据记录查看结束后,使用reset_states重置meter,记录下一阶段。

2.快捷训练
生成了一个模型之后,有compile, fit, evalute, predict等接口可以调用,这可以使得我们的训练很容易实现。
①compile
这个方法中可以指定:优化器+lr,损失,准确率等。

②fit
完成compile之后,直接调用fit,给出训练数据,指定epoch就可以了。

以上两行,就可以直接完成训练,训练过程中会返回一些基本信息,训练周期,数据量,使用的时间,每一步使用的时间,每一个周期后的损失值等。
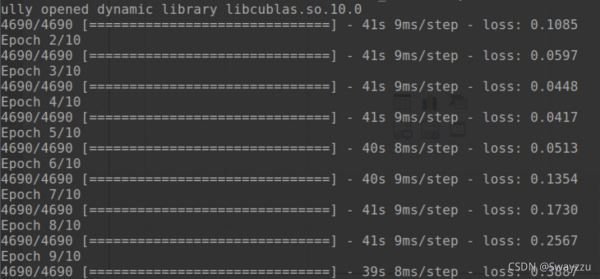
fit中还可以给出validation_data = test_data, validation_freq=2,也就是循环2次训练,就进行一次测试,会打印出测试分数。可见下面情况已经过拟合了。

③evaluate
调用这个方式之后,会在训练完成后,进行测试,并打印出测试结果。

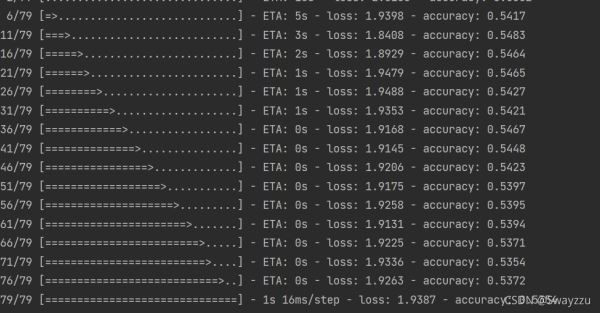
④predict
这个其实和network(x)是一样的,就是完成前向传播。

以上就是TensorFlow人工智能Keras高层接口应用示例的详细内容,更多关于TensorFlow人工智能Keras高层接口的资料请关注我们其它相关文章!
相关推荐
-
Tensorflow与Keras自适应使用显存方式
Tensorflow支持基于cuda内核与cudnn的GPU加速,Keras出现较晚,为Tensorflow的高层框架,由于Keras使用的方便性与很好的延展性,之后更是作为Tensorflow的官方指定第三方支持开源框架. 但两者在使用GPU时都有一个特点,就是默认为全占满模式.在训练的情况下,特别是分步训练时会导致显存溢出,导致程序崩溃. 可以使用自适应配置来调整显存的使用情况. 一.Tensorflow 1.指定显卡 代码中加入 import os os.environ["CUDA_VIS
-
tensorflow2.0教程之Keras快速入门
Keras 是一个用于构建和训练深度学习模型的高阶 API.它可用于快速设计原型.高级研究和生产. keras的3个优点: 方便用户使用.模块化和可组合.易于扩展 1.导入tf.keras tensorflow2推荐使用keras构建网络,常见的神经网络都包含在keras.layer中(最新的tf.keras的版本可能和keras不同) import tensorflow as tf from tensorflow.keras import layers print(tf.__version__
-
keras 获取某层的输入/输出 tensor 尺寸操作
获取单输入尺寸,该层只被使用了一次. import keras from keras.layers import Input, LSTM, Dense, Conv2D from keras.models import Model a = Input(shape=(32, 32, 3)) b = Input(shape=(64, 64, 3)) conv = Conv2D(16, (3, 3), padding='same') conved_a = conv(a) # 到目前为止只有一个输入,以下
-
解决tensorflow 与keras 混用之坑
在使用tensorflow与keras混用是model.save 是正常的但是在load_model的时候报错了在这里mark 一下 其中错误为:TypeError: tuple indices must be integers, not list 再一一番百度后无结果,上谷歌后找到了类似的问题.但是是一对鸟文不知道什么东西(翻译后发现是俄文).后来谷歌翻译了一下找到了解决方法.故将原始问题文章贴上来警示一下 原训练代码 from tensorflow.python.keras.preproce
-
解决TensorFlow调用Keras库函数存在的问题
tensorflow在1.4版本引入了keras,封装成库.现想将keras版本的GRU代码移植到TensorFlow中,看到TensorFlow中有Keras库,大喜,故将神经网络定义部分使用Keras的Function API方式进行定义,训练部分则使用TensorFlow来进行编写.一顿操作之后,运行,没有报错,不由得一喜.但是输出结果,发现,和预期的不一样.难道是欠拟合?故采用正弦波预测余弦来验证算法模型. 部分调用keras库代码如上图所示,用正弦波预测余弦波,出现如下现象: def
-

TensorFlow人工智能学习Keras高层接口应用示例
目录 1.metrics ①创建Meter ②更新数据 ③获取数据 ④重置状态 2.快捷训练 ①compile ②fit ③evaluate ④predict 1.metrics keras.metrics可以用来对数据进行记录跟踪,当我们的数据量太大,又想在中间就看看训练的情况的时候,可以使用此接口.步骤如下: ①创建Meter 通过metrics中带有的借口,创建一个meter. ②更新数据 当我们在某一行代码得到了需要的数据的时候,就可以调用update_state方法,将数据进行更新.注
-
TensorFlow人工智能学习数据填充复制实现示例
目录 1.tf.pad() 2.tf.tile() 1.tf.pad() 该方法能够给数据周围填0,填的参数是:需要填充的数据+填0的位置 填0的位置是一个数组形式,对应如下:[[上行,下行],[左列,右列]],具体例子如下: 较为常用的是上下左右各一行. 给图片进行padding的时候,通常数据的维度是[b,h,w,c],那么增加两行,两列的话,是在中间的h和w增加: 2.tf.tile() 该方法可以复制数据,需要填的参数:数据,维度+对应的复制次数. broadcast_to = expa
-
TensorFlow人工智能学习数据合并分割统计示例详解
目录 一.数据合并与分割 1.tf.concat() 2.tf.split() 3.tf.stack() 二.数据统计 1.tf.norm() 2.reduce_min/max/mean() 3.tf.argmax/argmin() 4.tf.equal() 5.tf.unique() 一.数据合并与分割 1.tf.concat() 填入两个tensor, 指定某维度,在指定的维度合并.除了合并的维度之外,其他的维度必须相等. 2.tf.split() 填入tensor,指定维度,指定分割的数量
-
TensorFlow人工智能学习创建数据实现示例详解
目录 一.数据创建 1.tf.constant() 2.tf.convert_to_tensor() 3.tf.zeros() 4.tf.fill() 二.数据随机初始化 ①tf.random.normal() ②tf.random.truncated_normal() ③tf.random.uniform() ④tf.random.shuffle() 一.数据创建 1.tf.constant() 创建自定义类型,自定义形状的数据,但不能创建类似于下面In [59]这样的,无法解释的数据. 2.
-
TensorFlow人工智能学习张量及高阶操作示例详解
目录 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 2.tf.clip_by_norm() 二.张量排序 1.tf.sort/argsort() 2.tf.math.topk() 三.TensorFlow高阶操作 1.tf.where() 2.tf.scatter_nd() 3.tf.meshgrid() 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 该方法按数值裁剪,传入tensor和阈值,maximum是把数
-
TensorFlow人工智能学习数据类型信息及转换
目录 一.数据类型 二.数据类型信息 ①.device ②.numpy() ③.shape / .ndim 三.数据类型转换 ①tf.convert_to_tensor ②tf.cast() 一.数据类型 在tf中,数据类型有整型(默认是int32),浮点型(默认是float32),以及布尔型,字符串. 二.数据类型信息 ①.device 查看tensor在哪(CPU上面或者GPU上面),可以通过.cpu(),.gpu()进行转换,如果数据所在的处理器位置不一样,则不能进行计算. ②.numpy
-
TensorFlow人工智能学习按索引取数据及维度变换详解
目录 一.按索引取数据 ①tf.gather() ②tf.gather_nd ③tf.boolean_mask 二.维度变换 ①tf.reshape() ②tf.transpose() ③tf.expand_dims() ④tf.squeeze() 一.按索引取数据 ①tf.gather() 输入参数:数据.维度.索引 例:设数据是[4,35,8],4个班级,每个班级35个学生,每个学生8门课成绩. 则下面In [49]的意思是,全部四个班级,每个班级取编号为2,3,7,9,16的学生,每个学生
-
人工智能学习Pytorch教程Tensor基本操作示例详解
目录 一.tensor的创建 1.使用tensor 2.使用Tensor 3.随机初始化 4.其他数据生成 ①torch.full ②torch.arange ③linspace和logspace ④ones, zeros, eye ⑤torch.randperm 二.tensor的索引与切片 1.索引与切片使用方法 ①index_select ②... ③mask 三.tensor维度的变换 1.维度变换 ①torch.view ②squeeze/unsqueeze ③expand,repea
-
人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式
-
Python人工智能学习PyTorch实现WGAN示例详解
目录 1.GAN简述 2.生成器模块 3.判别器模块 4.数据生成模块 5.判别器训练 6.生成器训练 7.结果可视化 1.GAN简述 在GAN中,有两个模型,一个是生成模型,用于生成样本,一个是判别模型,用于判断样本是真还是假.但由于在GAN中,使用的JS散度去计算损失值,很容易导致梯度弥散的情况,从而无法进行梯度下降更新参数,于是在WGAN中,引入了Wasserstein Distance,使得训练变得稳定.本文中我们以服从高斯分布的数据作为样本. 2.生成器模块 这里从2维数据,最终生成2