IDEA 中使用 Big Data Tools 连接大数据组件
目录
- 简介
- 安装 Big Data Tools 插件
- Flink 配置(不推荐)
- Kafka 配置(推荐)
- HDFS 配置(推荐)
- 总结
简介
Big Data Tools 插件可用于 Intellij Idea 2019.2 及以后的版本。它提供了使用 Zeppelin,AWS S3,Spark,Google Cloud Storage,Minio,Linode,数字开放空间,Microsoft Azure 和 Hadoop 分布式文件系统(HDFS)来监视和处理数据的特定功能。
下面来看一下 Big Data Tools 的安装和使用,主要会配置 Flink,Kafka 和 HDFS。
安装 Big Data Tools 插件

点击安装完成之后,需要重启一下 IDEA,插件才能生效,上面我已经安装过了。
Flink 配置(不推荐)
flink 需要下载即将发布的 IDEA 2022.2-EAP 版本才有,因为之前是不支持 flink 的。

先点击 IDEA 右侧的 Big Data Tools,然后点击加号就可以添加 Flink 组件了。

输入 Flink WEB UI 地址,点击 OK 就可以了。

这样就可以直接在 IDEA 里面查看 Flink Dashboard,跟在 Web UI 上的功能完全一样,点击箭头所指的地方可以直接跳转到 Flink UI,虽然可以直接在 IDEA 里面查看 Dashboard,但是个人感觉还是在 Flink Web UI 上查看更加方便,可能是看习惯了。不是太推荐这个功能。
Kafka 配置(推荐)
然后来看一下 kafka 的配置。

同样的,点击加号选择 Kafka 然后设置一下 Kafka 集群的 broker list ,点击 OK 就行了。
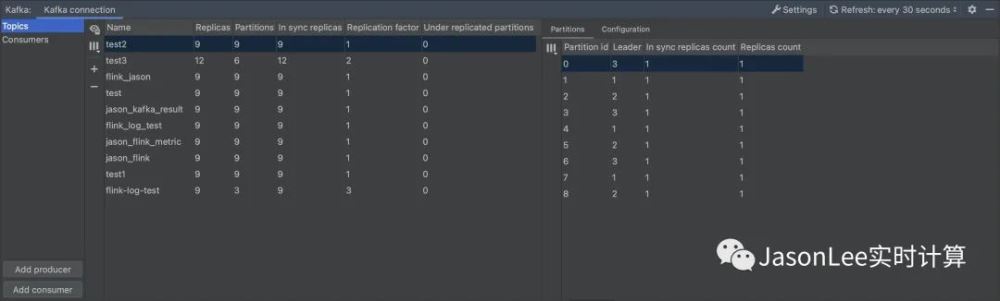
可以看到所有 topic 的详细信息,包括 partition,replicas 等,还可以查看 Consumers 的情况,这个功能还是不错的,虽然现在也有很多开源的 kafka 监控工具,但是配置起来还是有一点门槛,这个插件的配置几乎是零门槛,对于简单的查看 kafka 的信息还是非常不错的。
HDFS 配置(推荐)
最后再来配置一个 HDFS。

Authentication type 选择 Explicit uri 然后设置一下 HDFS 服务地址就可以了。

直接就可以查看 HDFS 上的目录及文件,这个功能还是非常方便的,就不用在登录 HDFS-Web 去查看文件了。
总结
从 Big Data Tools 插件的安装配置到使用,主要介绍了 Flink,Kafka,HDFS,这三个组件的配置使用,整个配置过程是非常简单的,当然这个插件支持的组件远不止这些,包括像 spark,hive,zeppelin 等都是支持的,感兴趣的同学可以自己在 IDEA 里面体验一下,整体上来说,这个插件还是非常有用的。
到此这篇关于IDEA 中使用 Big Data Tools 连接大数据组件的文章就介绍到这了,更多相关IDEA Big Data Tools 连接大数据 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
IDEA配置连接MYSQL数据库遇到Failed这个问题解决
本文主要介绍了IDEA配置连接MYSQL数据库遇到Failed这个问题解决,分享给大家,具体如下: 错误位置如下 我们改过来 发现就能正常连接 到此这篇关于IDEA配置连接MYSQL数据库遇到Failed这个问题解决的文章就介绍到这了,更多相关IDEA配置连接MYSQL内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
IDEA无法连接mysql数据库的6种解决方法大全
本文主要介绍了IDEA无法连接mysql数据库的6种解决方法大全,分享给大家,具体如下: 1.本地的mysql没有创建该数据库(笔者就是这个原因!) 查看数据库发现没有,重建就可以了 测试成功! 网上说法: 2.IP地址不对 https://www.jb51.net/article/200432.htm 3.mysql版本过高 https://bbs.csdn.net/topics/392368070?page=1 4.创建的Java项目的路径里包含中文字符 https://www.jb51.n
-
Idea连接MySQL数据库出现中文乱码的问题
问题:当使用JDBC连接MySQL数据库时,插入中文显示乱码 解决方法:在连接代码中插入以下代码 String url = "jdbc:mysql://localhost:3306/你的数据库名?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC&useSSL=false"; 代码解读 useUnicode=true&characterEncoding=utf8 以上代码有两个作用: 1.存
-
IDEA使用properties配置文件进行mysql数据库连接的教程图解
Properties类 简要概括: Properties类是 键和值均为字符串的可以永久存储到文件中的key-value集合 java.util.Properties类表示一组持久的属性,是Hashtable的子类. Properties可以保存到流中或从流中加载,可以保存到后缀名为properties的文件中. 属性列表中的每个键及其对应的值都是一个字符串. 即键和值都是String类型. 因为Properties从继承Hashtable时, put种putAll方法可应用于Propertie
-

Intellij IDEA连接Navicat数据库的方法
(一)配置环境变量 ①我的电脑右键选择属性→高级系统设置→环境变量→新建→输入变量名MYSQL_HOME和变量值→确定 ②选择Path→新建→把 %MYSQL_HOME%\bin 加上→确定 (二)导入数据库驱动的jar包 ①在官网下载驱动包 在浏览器搜maven repository,进入官网搜MySQL Connector/J 选择需要的版本下载 ②在项目的web目录下的WEB-INF下创建lib文件夹,把数据库驱动的包复制进来 (三)测试 创建一个类测试是否连接成功 import java
-
使用IDEA配置Tomcat和连接MySQL数据库(JDBC)详细步骤
IDEA配置Tomcat 1,点击Run-EDit Configurations- 2.点击左侧"+"号,找到Tomcat Server-Local(若是没有找到Tomcat Server 可以点击最后一行 34 items more) 3.在Tomcat Server -> local-> Server -> Application server项目下,点击 Configuration ,找到本地 Tomcat 服务器,再点击 OK按钮. 至此,IntelliJ I
-
idea配置连接数据库的超详细步骤
学习时,使用IDEA的时候,需要连接Database,连接时遇到了一些小问题,下面记录一下操作流程以及遇到的问题的解决方法. 一. 连接操作 简介:介绍如何创建连接,具体连接某个数据库的操作流程. 1.1 创建连接 打开idea,点击右侧的 Database 或者 选择 View --> Tool Windows --> Database 点击 + 号 ,选择 Data Source ,选择 数据库 (下面以MySQL为例) 选择 mysql 后弹出以下界面 填上信息后,点击 Test Con
-
IDEA使用JDBC安装配置jar包连接MySQL数据库
一 .MySQL版本查询 1)登录mysql 首先Window+R 然后在命令行里输入 mysql -u此处填你的mysql账号(注意要加-u) -p(此处是填写密码) 以我的为例 mysql -uroot -prota 显示这样之后登录成功 2)查询版本号 select version(); mysql> select version();+-----------+| version() |+-----------+| 5.5.56 |+-----------+1 row in se
-
IntelliJ IDEA连接MySQL数据库详细图解
在网上down了个web项目,在 IntelliJ IDEA 这个编辑器里面跑起来,但是发现domain文件夹下的xml文件都报如下的红色提示错误: Cannot resolve table 'jrun_access' less... (Ctrl+F1) This inspection lets you spot the following problems that might occur in XML descriptors that define Hibernate mappings: R
-
IDEA 中使用 Big Data Tools 连接大数据组件
目录 简介 安装 Big Data Tools 插件 Flink 配置(不推荐) Kafka 配置(推荐) HDFS 配置(推荐) 总结 简介 Big Data Tools 插件可用于 Intellij Idea 2019.2 及以后的版本.它提供了使用 Zeppelin,AWS S3,Spark,Google Cloud Storage,Minio,Linode,数字开放空间,Microsoft Azure 和 Hadoop 分布式文件系统(HDFS)来监视和处理数据的特定功能. 下面来看一下
-
MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程
大数据量备份与还原,始终是个难点.当MYSQL超10G,用mysqldump来导出就比较慢了.在这里推荐xtrabackup,这个工具比mysqldump要快很多. 一.Xtrabackup介绍 1.Xtrabackup是什么 Xtrabackup是一个对InnoDB做数据备份的工具,支持在线热备份(备份时不影响数据读写),是商业备份工具InnoDB Hotbackup的一个很好的替代品. Xtrabackup有两个主要的工具:xtrabackup.innobackupex 1.xtraback
-
vue组件中props与data的结合使用方式
目录 组件中props与data的结合使用 子组件中data从props中动态更新数据 组件中props与data的结合使用 如前所述(vue组件属性(props)及私有数据data),vue组件中,props是组件公有属性,对外:data是组件的私有数据,对内.正因为props对外,由外部赋值,因此在组件内部,是只读的,即组件内部不适宜去改变这些元素的值.当然,改也可以改,但运行时刻会有告警. 正如我们写一个函数,对于传入的参数,我们一般是只读对待的,极少会去修改它的值一样.当然,这只是一种编
-
Java中使用WebUploader插件上传大文件单文件和多文件的方法小结
一.使用webuploader插件的原因说明 被现在做的项目坑了. 先说一下我的项目架构spring+struts2+mybatis+MySQL 然后呢.之前说好的按照2G上传就可以了,于是乎,用了ajaxFileUpload插件,因为之前用图片上传也是用这个,所以上传附件的时候就直接拿来用了 各种码代码,测试也测过了,2G文件上传没问题,坑来了,项目上线后,客户又要求上传4G文件,甚至还有20G以上的..纳尼,你不早说哦... 在IE11下用ajaxFileUpload.js插件上传超过4G的
-
在ASP.NET 2.0中操作数据之二十五:大数据量时提高分页的效率
导言 如我们在之前的教程里讨论的那样,分页可以通过两种方法来实现: 1.默认分页– 你仅仅只用选中data Web control的 智能标签的Enable Paging ; 然而,当你浏览页面的时候,虽然你看到的只是一小部分数据,ObjectDataSource 还是会每次都读取所有数据 2.自定义分页– 通过只从数据库读取用户需要浏览的那部分数据,提高了性能. 显然这种方法需要你做更多的工作. 默认的分页功能非常吸引人,因为你只需要选中一个checkbox就可以完成了.但是它每次都读取所有的
-
Innodb中mysql快速删除2T的大表方法示例
前言 本文主要给大家介绍了关于Innodb中mysql快速删除2T的大表的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 来,先来看小漫画陶冶一下情操 OK,这里就说了.假设,你有一个表erp,如果你直接进行下面的命令 drop table erp 这个时候所有的mysql的相关进程都会停止,直到drop结束,mysql才会恢复执行.出现这个情况的原因就是因为,在drop table的时候,innodb维护了一个全局锁,drop完毕锁就释放了. 这意味着,如果在白天,访
-
Python连接Hadoop数据中遇到的各种坑(汇总)
最近准备使用Python+Hadoop+Pandas进行一些深度的分析与机器学习相关工作.(当然随着学习过程的进展,现在准备使用Python+Spark+Hadoop这样一套体系来搭建后续的工作环境),当然这是后话. 但是这项工作首要条件就是将Python与Hadoop进行打通,本来认为很容易的一项工作,没有想到竟然遇到各种坑,花费了整整半天时间.后来也在网上看到大家在咨询相同的问题,但是真正解决这个问题的帖子又几乎没有,所以现在将Python连接Hadoop数据库过程中遇到的各种坑进行一个汇总
-
linux中的软连接和硬连接详解
目录 1.文件和目录的基本存储 2.In命令介绍 (1)我们来看看ln命令的基本信息命令名称: (2)ln命令的基本格式 3.创建硬链接 (1)如何创建硬链接 (2)硬链接特征 (3)硬连接原理 4.创建软链接 (1)如何创建软链接 (2)软链接特征 (3)软连接原理 (4)说明 提示:先来说明一下在Linux系统中文件和目录的基本存储,这样更方便我们理解和学习Linux系统中的硬链接和软链接. 1.文件和目录的基本存储 之前说过分区,每个分区都可以理解为分成两部分,一小部分里边是存放文件的i节
-
PyTorch中torch.utils.data.Dataset的介绍与实战
目录 一.前言 二.torch.utils.data.Dataset 是什么 1. 干什么用的? 2. 长什么样子? 三.通过继承 torch.utils.data.Dataset 定义自己的数据集类 四.为什么要定义自己的数据集类? 五.实战:torch.utils.data.Dataset + Dataloader 实现数据集读取和迭代 实例 1 实例 2:进阶 参考链接 总结 一.前言 训练模型一般都是先处理 数据的输入问题 和 预处理问题 .Pytorch提供了几个有用的工具:torch
-
大数据开发phoenix连接hbase流程详解
目录 一.安装phoennix添加配置 二.启动phoenix服务 三.phoenix常用语法 四.java代码集成phoenix 一.安装phoennix添加配置 1.将phoenix-server-hbase-2.4-5.1.2.jar拷贝至hbase的的lib下 cp phoenix-server-hbase-2.4-5.1.2.jar ../hbase/lib/ 2.配置phoenix可以访问hbase的系统表 (1)将以下配置添加至hbase-site.xml中 <property>