R语言使用cgdsr包获取TCGA数据示例详解
目录
- TCGA数据源
- TCGA数据库探索工具
- 查看任意数据集的样本列表方式
- 选定数据形式及样本列表后获取感兴趣基因的信息,下载mRNA数据
- 选定样本列表获取临床信息
- 综合性获取
- 下载mRNA数据
- 获取病例列表的临床数据
- 从cBioPortal下载点突变信息
- 从cBioPortal下载拷贝数变异数据
- 把拷贝数及点突变信息结合画热图
TCGA数据源
众所周知,TCGA数据库是目前最综合全面的癌症病人相关组学数据库,包括的测序数据有:
DNA Sequencing
miRNA Sequencing
Protein Expression
mRNA Sequencing
Total RNA Sequencing
Array-based Expression
DNA Methylation
Copy Number
TCGA数据库探索工具
知名的肿瘤研究机构都有着自己的TCGA数据库探索工具,比如:
Broad Institute FireBrowse portal, The Broad Institute
cBioPortal for Cancer Genomics, Memorial Sloan-Kettering Cancer Center
TCGA Batch Effects, MD Anderson Cancer Center
Regulome Explorer, Institute for Systems Biology
Next-Generation Clustered Heat Maps, MD Anderson Cancer Center
其中cBioPortal更是被包装到R包里面
这里介绍如何使用R语言的cgdsr包来获取任意TCGA数据。
cgdsr包:R语言工具包,可以下载TCGA数据。
DT包:data.table包,简称DT包,是R语言中的数据可视化工具包。DT包可以将Javascript中的方法运用到R中,也能将矩阵或者数据表在网页中可视化为表格,以及其它的一些功能。
> setwd("C:/Users/YLAB/Documents/R/win-library/4.1/")
> install.packages("R.methodsS3_1.8.1.zip",repos=NULL)#安装
> install.packages("R.oo_1.24.0.zip",repos=NULL)#安装
> install.packages("data.table")
> BiocManager::install("cgdsr", force = TRUE)#安装
> library(cgdsr)
> library(DT)
#创建一个cgdsr对象
> mycgds <- CGDS("http://www.cbioportal.org/")
#检查下载是否成功,如果是FAILED就是没成功。
> test(mycgds)
getCancerStudies... OK
getCaseLists (1/2) ... OK
getCaseLists (2/2) ... OK
getGeneticProfiles (1/2) ... OK
getGeneticProfiles (2/2) ... OK
getClinicalData (1/1) ... OK
getProfileData (1/6) ... OK
getProfileData (2/6) ... OK
getProfileData (3/6) ... OK
getProfileData (4/6) ... OK
getProfileData (5/6) ... OK
getProfileData (6/6) ... OK
all_TCGA_studies <- getCancerStudies(mycgds)
> DT::datatable(all_TCGA_studies)
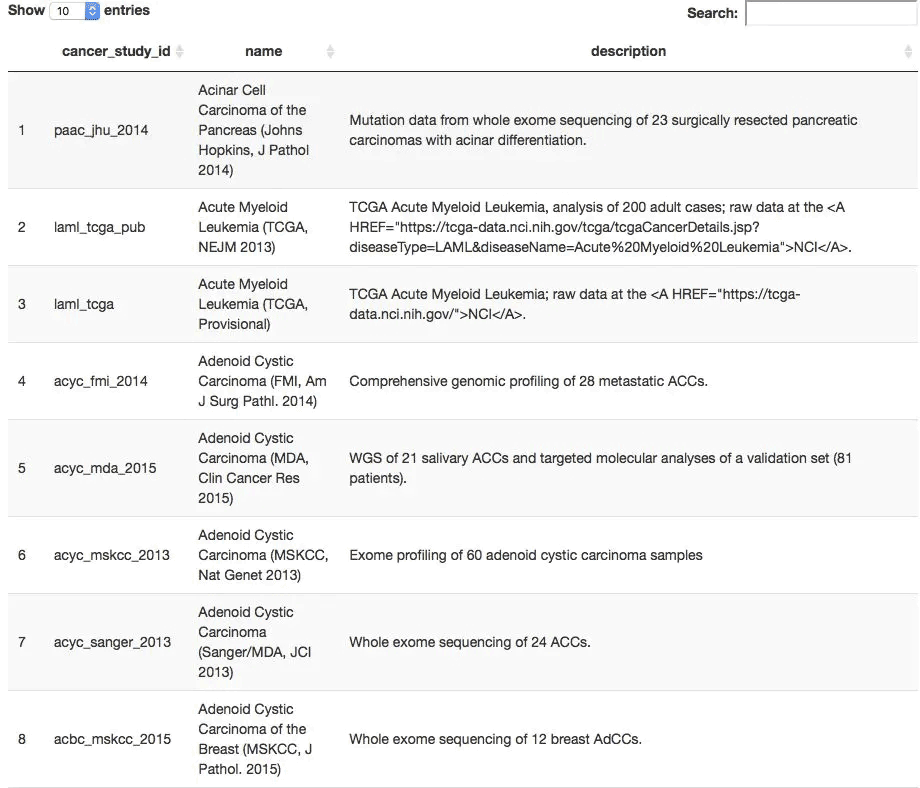
查看任意数据集的样本列表方式
上表的cancer_study_id其实就是数据集的名字,我们任意选择一个数据集,比如stad_tcga_pub ,可以查看它里面有多少种样本列表方式。
stad2014 <- "stad_tcga_pub" ## 获取在stad2014数据集中有哪些表格(每个表格都是一个样本列表) all_tables <- getCaseLists(mycgds, stad2014) dim(all_tables) ## 共6种样本列表方式 [1] 6 5 DT::datatable(all_tables[,1:3])
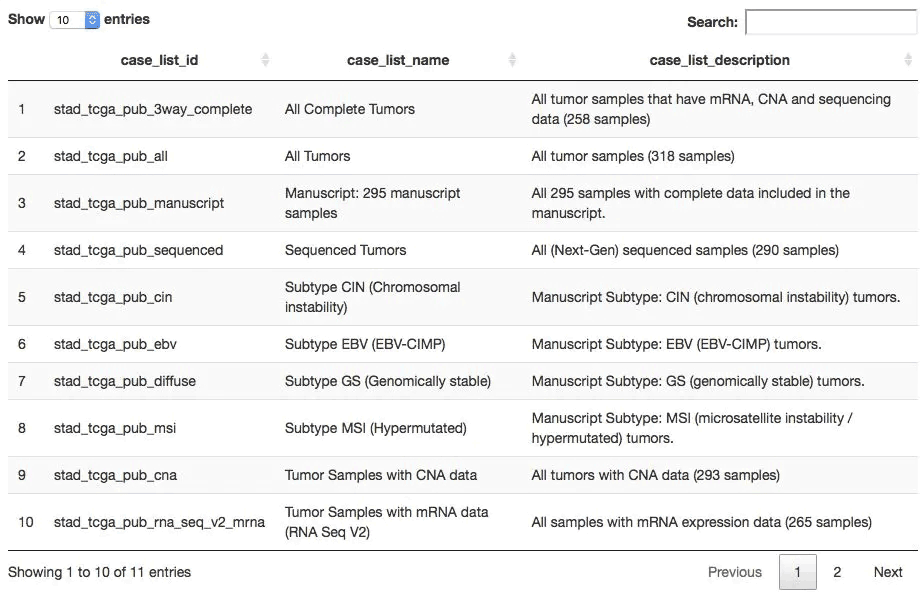
查看任意数据集的数据形式
## 而后获取可以下载哪几种数据,一般是mutation,CNV和表达量数据
all_dataset <- getGeneticProfiles(mycgds, stad2014)
DT::datatable(all_dataset,
extensions = 'FixedColumns',
options = list( #dom = 't',
scrollX = TRUE,
fixedColumns = TRUE
))
一般来说,TCGA的一个项目数据就几种,如下:
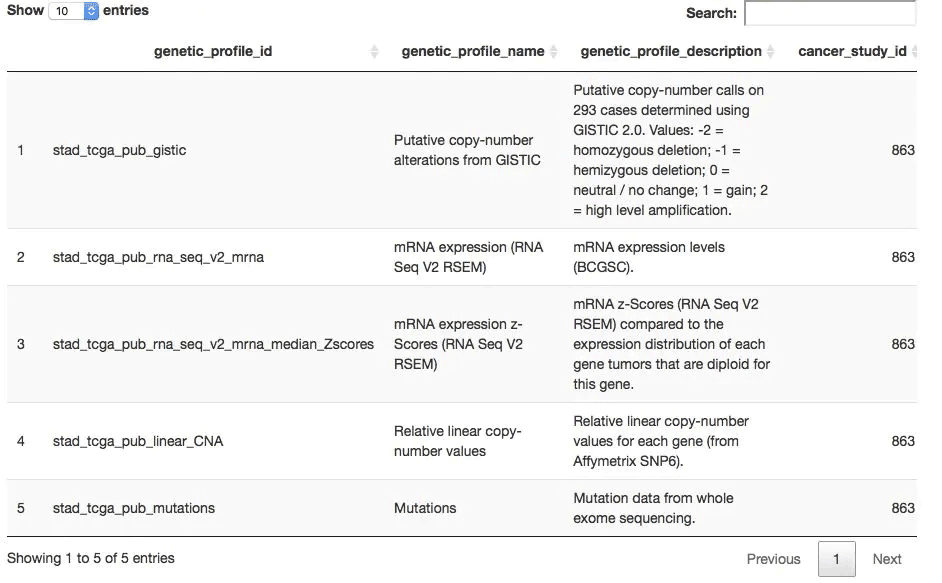
选定数据形式及样本列表后获取感兴趣基因的信息,下载mRNA数据
my_dataset <- 'stad_tcga_pub_rna_seq_v2_mrna' my_table <- "stad_tcga_pub_rna_seq_v2_mrna" BRCA1 <- getProfileData(mycgds, "BRCA1", my_dataset, my_table) dim(BRCA1) [1] 265 1
样本个数差异很大,不同癌症热度不一样。
选定样本列表获取临床信息
## 如果我们需要绘制survival curve,那么需要获取clinical数据
clinicaldata <- getClinicalData(mycgds, my_table)
DT::datatable(clinicaldata,
extensions = 'FixedColumns',
options = list( #dom = 't',
scrollX = TRUE,
fixedColumns = TRUE
))
综合性获取
只需要根据癌症列表选择自己感兴趣的研究数据集即可,然后选择好感兴趣的数据形式及对应的样本量。就可以获取对应的信息:
library(cgdsr)
library(DT)
mycgds <- CGDS("http://www.cbioportal.org")
##mycancerstudy = getCancerStudies(mycgds)[25,1]
mycancerstudy = 'brca_tcga' getCaseLists(mycgds,mycancerstudy)[,1]
## [1] "brca_tcga_3way_complete" "brca_tcga_all"
## [3] "brca_tcga_protein_quantification" "brca_tcga_sequenced"
## [5] "brca_tcga_cna" "brca_tcga_methylation_hm27"
## [7] "brca_tcga_methylation_hm450" "brca_tcga_mrna"
## [9] "brca_tcga_rna_seq_v2_mrna" "brca_tcga_rppa"
## [11] "brca_tcga_cnaseq"
getGeneticProfiles(mycgds,mycancerstudy)[,1] ## [1] "brca_tcga_rppa" ## [2] "brca_tcga_rppa_Zscores" ## [3] "brca_tcga_protein_quantification" ## [4] "brca_tcga_protein_quantification_zscores" ## [5] "brca_tcga_gistic" ## [6] "brca_tcga_mrna" ## [7] "brca_tcga_mrna_median_Zscores" ## [8] "brca_tcga_rna_seq_v2_mrna" ## [9] "brca_tcga_rna_seq_v2_mrna_median_Zscores" ## [10] "brca_tcga_linear_CNA" ## [11] "brca_tcga_methylation_hm450" ## [12] "brca_tcga_mutations"
下载mRNA数据
mycaselist ='brca_tcga_rna_seq_v2_mrna'
mygeneticprofile = 'brca_tcga_rna_seq_v2_mrna'
# Get data slices for a specified list of genes, genetic profile and case list
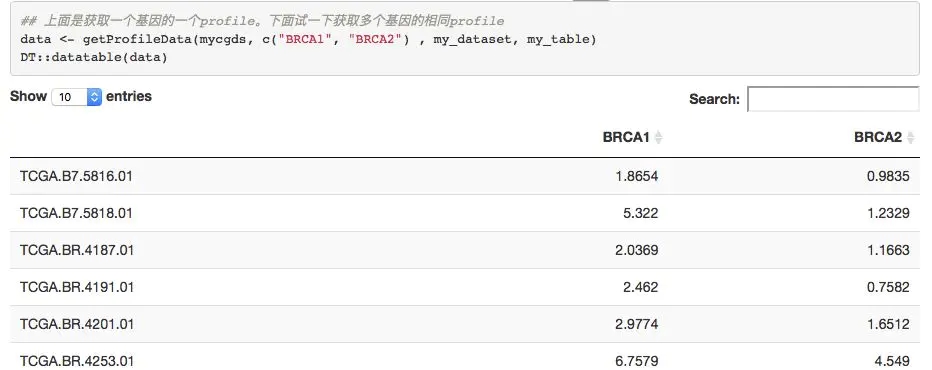
expr=getProfileData(mycgds,c('BRCA1','BRCA2'),mygeneticprofile,mycaselist)
DT::datatable(expr)
很简单就得到了指定基因在指定癌症的表达量
获取病例列表的临床数据
myclinicaldata = getClinicalData(mycgds,mycaselist)
DT::datatable(myclinicaldata,
extensions = 'FixedColumns',
options = list( #dom = 't',
scrollX = TRUE,
fixedColumns = TRUE
))
## Warning in instance$preRenderHook(instance): It seems your data is too
## big for client-side DataTables. You may consider server-side processing:
## http://rstudio.github.io/DT/server.html
从cBioPortal下载点突变信息
#突变基因名称集合
mutGene=c("EGFR", "PTEN", "TP53", "ATRX")
#检索基因和遗传图谱的基因组图谱数据
mut_df <- getProfileData(mycgds,
caseList ="gbm_tcga_sequenced",
geneticProfile = "gbm_tcga_mutations",
genes = mutGene
)
mut_df <- apply(mut_df,2,as.factor)
mut_df[mut_df == "NaN"] = ""
mut_df[is.na(mut_df)] = ""
mut_df[mut_df != ''] = "MUT"
DT::datatable(mut_df)

从cBioPortal下载拷贝数变异数据
mutGene=c("TP53","UGT2B7","CYP3A4")
cna<-getProfileData(mycgds,mutGene,"gbm_tcga_gistic","gbm_tcga_sequenced")
cna<-apply(cna,2,function(x) as.character(factor(x,levels = c(-2:2),labels = c("HOMDEL","HETLOSS","DIPLOID","GAIN","AMP"))))
cna[is.na(cna)]=""
cna[cna=="DIPLOID"]=""
DT::datatable(cna)
把拷贝数及点突变信息结合画热图
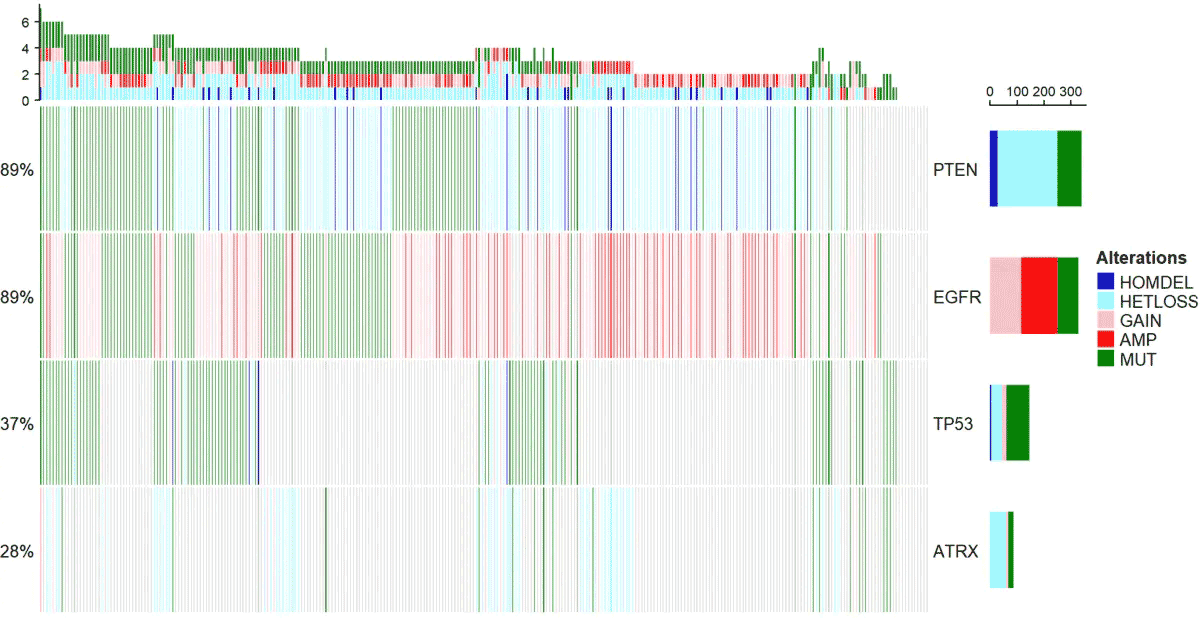
下面的函数,主要是配色比较复杂,其实原理很简单,就是一个热图。
library(ComplexHeatmap)
library(grid)
conb <- data.frame(matrix(paste(as.matrix(cna),as.matrix(mut_df),sep = ";"), nrow=nrow(cna),ncol=ncol(cna), dimnames=list(row.names(mut_df),colnames(cna))))
mat <- as.matrix(t(conb))
DT::datatable((mat))
alt <- apply(mat,1,function(x)strsplit(x,";"))
alt <- unique(unlist(alt))
alt <- alt[which(alt !="")]
alt <-c("background",alt)
alter_fun = list( background = function(x,y,w,h){ grid.rect(x,y,w-unit(0.5,"mm"),h-unit(0.5,"mm"), gp=gpar(fill="#CCCCCC",col=NA)) }, HOMDEL = function(x,y,w,h){ grid.rect(x,y,w-unit(0.5,"mm"),h-unit(0.5,"mm"), gp=gpar(fill="blue3",col=NA)) }, HETLOSS = function(x,y,w,h){ grid.rect(x,y,w-unit(0.5,"mm"),h-unit(0.5,"mm"), gp=gpar(fill="cadetblue1",col=NA)) }, GAIN = function(x,y,w,h){ grid.rect(x,y,w-unit(0.5,"mm"),h-unit(0.5,"mm"), gp=gpar(fill="pink",col=NA)) }, AMP = function(x,y,w,h){ grid.rect(x,y,w-unit(0.5,"mm"),h-unit(0.5,"mm"), gp=gpar(fill="red",col=NA)) }, MUT = function(x,y,w,h){ grid.rect(x,y,w-unit(0.5,"mm"),h-unit(0.5,"mm"), gp=gpar(fill="#008000",col=NA)) })
col <- c("MUT"="#008000","AMP"="red","HOMDEL"="blue3", "HETLOSS"="cadetblue1","GAIN"="pink")
alt = intersect(names(alter_fun),alt)
alt_fun_list <- alter_fun[alt]
col <- col[alt]
oncoPrint(mat=mat,alter_fun = alt_fun_list, get_type = function(x) strsplit(x,";")[[1]], col = col)
以上就是R语言使用cgdsr包获取TCGA数据示例详解的详细内容,更多关于R语言cgdsr获取TCGA数据的资料请关注我们其它相关文章!
相关推荐
-

R语言向量下标和子集的使用
目录 1.正整数下标 2.负整数下标 3.空下标与零下标 4.下标超界 5.逻辑下标 6. which().which.min().which.max()函数 7. 元素名 8.用R向量下标作映射 9.集合运算 练习 1.正整数下标 首先定义一个x,然后对向量 x, 在后面加方括号和下标可以访问向量的元素和子集,如: 定义一个x: x <- c(1, 4, 6.25) x 返回: 我们取出第二个元素: x[2] 返回: 我们再修改第二个元素为 99 : x[2] <- 99; x 返回: 我
-
R语言批量读取某路径下文件内容的方法
R刚入门的时候,能够正确读取单个文件就觉得小有成就,随着时间的积累,单一文件地读取已经不能满足需求了,此时,批量地做就是解放双手地过程. 使用for循环把下载地TCGA数据读入R语言并转换成数据框 使用三个for循环来完成,这是第一个for循环. 1. 把所有数据读入在一个文件夹中 dir.create("data_in_one") #创建目标文件夹,也可右键创建 dir("rawdata/") #查看原路径的内容 for (dirname in dir("
-
R语言因子类型的实现
目录 1.因子 2.table()函数 3.tapply()函数 4.forcats包的因子函数 1.因子 R 中用因子代表数据中分类变量 , 如性别.省份.职业.有序因子代表有序量度,如打分结果,疾病严重程度等. 用 factor() 函数把字符型向量转换成因子,如 x <- c(" 男", " 女", " 男", " 男", " 女") sex <- factor(x) sex 返回: at
-
基于R语言 数据检验详解
目录 1.W检验(Shapiro–Wilk(夏皮罗–威克尔)W统计量检验) 2.K检验(经验分布的Kolmogorov-Smirnov检验) 3.相关性检验: 4.T检验 5.正态总体方差检验 6.二项分布总体假设检验 7.Pearson拟合优度χ2检验 8.Fisher精确的独立检验: 9.McNemar检验: 10.秩相关检验 11.Wilcoxon秩检验 1. W检验(Shapiro–Wilk (夏皮罗–威克尔 ) W统计量检验) 目标:检验数据是否符合某正态分布,如:标准正态分布N(0,
-
R语言使用cgdsr包获取TCGA数据示例详解
目录 TCGA数据源 TCGA数据库探索工具 查看任意数据集的样本列表方式 选定数据形式及样本列表后获取感兴趣基因的信息,下载mRNA数据 选定样本列表获取临床信息 综合性获取 下载mRNA数据 获取病例列表的临床数据 从cBioPortal下载点突变信息 从cBioPortal下载拷贝数变异数据 把拷贝数及点突变信息结合画热图 TCGA数据源 众所周知,TCGA数据库是目前最综合全面的癌症病人相关组学数据库,包括的测序数据有: DNA Sequencing miRNA Sequencing P
-
R语言UpSet包实现集合可视化示例详解
目录 前言 一.R包及数据 二.upset()函数 1)基本参数 2)queries参数 3)attribute.plots参数 3.1 添加柱形图和散点图 3.2 添加箱线图 3.3 添加密度曲线图 前言 介绍一个R包UpSetR,专门用来集合可视化,当多集合的韦恩图不容易看的时候,就是它大展身手的时候了. 一.R包及数据 #安装及加载R包 #install.packages("UpSetR") library(UpSetR) #载入数据集 data <- read.csv(&
-
R语言学习VennDiagram包绘制韦恩图示例
目录 引言 一 需要安装和导入的包 二 使用函数及参数 三 知道各个数据集的个数以及重叠(交叉)的个数 2.1 两个已知数据集的韦恩图 2.2 三个已知数据集的韦恩图 四 根据数据集合绘制韦恩图 4.1 四个数据集合 4.2 五个数据集合 引言 本版块会持续分享一些常用的结果展示的图形. 在得到数据之后,我们经常会用到维恩图来展示各个数据集之间的重叠关系.本文简单的介绍R语言中的VennDiagram包绘制数据集的维恩图. 一 需要安装和导入的包 install.packages("VennDi
-
R语言常用两种并行方法之parallel详解
目录 并行计算 在模拟时什么地方可以用到并行? 怎么在R中看我们可以使用并行? parallel(简单) 由于最近在进行一些论文的模拟,所以尝试了两种并行的方法:parallel与snowfall,这两种方法各有优缺,但还是推荐snowfall,整体较为稳定,不容易因为内存不足或者并行线程过多等原因而报错. 并行计算 并行计算: 简单来讲,就是同时使用多个计算资源来解决一个计算问题,是提高计算机系统计算速度和处理能力的一种有效手段.(参考:并行计算简介) 一个问题被分解成为一系列可以并发执行的离
-
R语言常用两种并行方法之snowfall详解
上一篇博客(R中两种常用并行方法之parallel)中已经介绍了R中常见的一种并行包:parallel,其有着简单便捷等优势,其实缺点也是非常明显,就是很不稳定.很多时候我们将大量的计算任务挂到服务器上进行运行时,更看重的是其稳定性. 这时就要介绍R中的另一个并行利器--snowfall,这也是在平时做模拟时用的最多的一种方法. 针对上篇中的简单例子 首先是一个最简单的并行的例子,这个例子不需要载入任何依赖库.函数.对象等.相对也比较简单: library(snowfall) # 载入snowf
-
R语言行筛选的方法之filter函数详解
目录 1. 数据 2. 生成ID列和类型 3. 提取effect大于0.1的行 4. 提取加性效应,且effect小于0的行 5. 根据部分行名删选 6. 固定字符特征进行行筛选 总结 下面介绍一下R语言中行筛选的方法,主要介绍filter函数 1. 数据 这里,使用asreml分析中的BLUP值为例,相关的模型为: m1 = asreml(Phen ~ G , random = ~ vm(Progeny,ainv) + vm(Dam,ainv) + vm(Progeny,dinv), work
-
Go语言学习教程之结构体的示例详解
目录 前言 可导出的标识符 嵌入字段 提升 标签 结构体与JSON相互转换 结构体转JSON JSON转结构体 练习代码步骤 前言 结构体是一个序列,包含一些被命名的元素,这些被命名的元素称为字段(field),每个字段有一个名字和一个类型. 结构体用得比较多的地方是声明与数据库交互时需要用到的Model类型,以及与JSON数据进行相互转换.(当然,项目中任何需要多种数据结构组合在一起使用的地方,都可以选择用结构体) 代码段1:声明一个待办事项的Model类型: type Todo struct
-
go语言reflect.Type 和 reflect.Value 应用示例详解
目录 一.使用 reflect.Type 创建实例 二.使用 reflect.Value 调用函数 一.使用 reflect.Type 创建实例 在通过 reflect.TypeOf 函数获取到变量的反射类型对象之后,可以通过反射类型对象 reflect.Type 的 New 函数来创建一个新的实例,注意这个实例的类型是 reflect.Type 类型的. package main import ( "fmt" "reflect" ) func main() { v
-
语言编程花絮内建构建顺序示例详解
目录 1 构建 顺序 1.1 交叉编译 1.2 设置 2 构建测试支持 1 构建 顺序 依据词法名顺序 当导入一个包,且这个包 定义了 init(), 那么导入时init()将被执行. 具体执行顺序: 全局变量定义时的函数 import 执行导入 -> cont 执行常量 --> var 执行变量 --> 执行初始化 init() --> 执行 main() ----> main import pk1 ---> pk1 const ... import pk2 ---&
-
Go语言基础go build命令用法及示例详解
目录 go build 一个Go项目在GOPATH下,会有如下三个目录 使用: 注意: go build 1. 用于测试编译多个包或一个main包 2. build命令编译包丢弃非main包编译结果,只是检查是否能够被编译 3. 保留main包编译结果 一个Go项目在GOPATH下,会有如下三个目录 bin存放编译后的可执行文件 pkg存放编译后的包文件 src存放项目源文件 一般,bin和pkg目录可以不创建,go命令会自动创建(如 go install),只需要创建src目录即可. 使用: