Python10行代码实现模拟百度搜索的示例
目录
- 1. 获取百度搜索接口
- 2. 指定搜索内容
- 3. UA伪装
- 4. 将响应内容写入文件
- 5. 使用浏览器打开页面
1000块钱做个百度?能提出这种要求的客户实乃乙方克星、民族之光、科创永动机、西虹市一大杰出青年,诺奖永远得不到的人才。
但作为一个硬核的程序员,没有什么功能是我们实现不了的,如果有,那就是钱没到位。因此,我们要用魔法打败魔法,10行代码给他写一个百度搜索。
1. 获取百度搜索接口
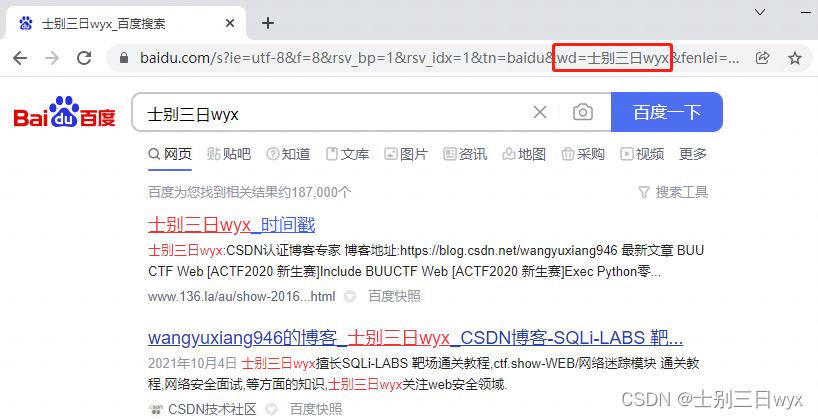
地址栏中有很多参数,但实际有用的参数只有 wd ,只需要保留这一个参数即可,其余删掉。
url = 'https://www.baidu.com/s?wd=士别三日wyx'
2. 指定搜索内容
搜索内容肯定不能写死,需要由用户「输入」
kw = input('百度一下:')
url = 'https://www.baidu.com/s?wd=' + kw
3. UA伪装
利用百度的接口发送「请求」,获取响应内容。
大部分网站都会对用户的请求进行「过滤」,以防止恶意攻击行为,比如查看是否是浏览器发出的请求
「UA伪装」是指在HTTP请求头中添加 User-agent ,伪装成浏览器的请求,网站检查请求头时,发现有UA请求头,就会认为是浏览器的请求,从而放行。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0',}
response = requests.get(url=url, headers=headers)
4. 将响应内容写入文件
响应的内容实际上就是构成页面的 HTML 代码,将响应内容写入HTML文件,就获得了百度搜索的响应页面
fileName = 'a.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(response.text)
5. 使用浏览器打开页面
页面生成以后肯定不能再手动打开,那也太low了,使用默认「浏览器」自动打开生成的页面
webbrowser.open(fileName)
源码如下
import webbrowser
import requests
kw = input('百度一下:')
url = 'https://www.baidu.com/s?wd=' + kw
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0',}
response = requests.get(url=url, headers=headers)
fileName = 'a.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(response.text)
webbrowser.open(fileName)
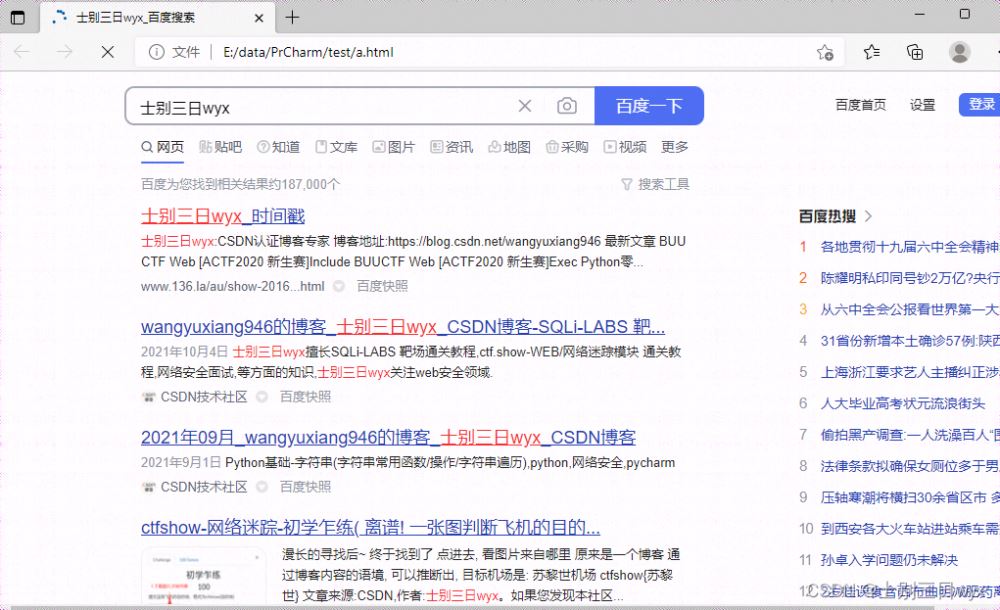
输入想要百度的内容,按下回车

即可自动使用默认浏览器打开搜索结果的页面
到此这篇关于Python10行代码实现模拟百度搜索的示例的文章就介绍到这了,更多相关Python 模拟百度搜索内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现提取百度搜索结果的方法
本文实例讲述了python实现提取百度搜索结果的方法.分享给大家供大家参考.具体实现方法如下: # coding=utf8 import urllib2 import string import urllib import re import random #设置多个user_agents,防止百度限制IP user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20130406 Firefox/23.0', \ 'M
-
Python通过tkinter实现百度搜索的示例代码
本文主要介绍了Python通过tkinter实现百度搜索的示例代码,分享给大家,具体如下: """ 百度搜索可视化 """ import tkinter import win32api from selenium.webdriver import Chrome entry = None def callback(): global entry keywords = entry.get() if not keywords: win32api.Mes
-

Python实现抓取百度搜索结果页的网站标题信息
比如,你想采集标题中包含"58同城"的SERP结果,并过滤包含有"北京"或"厦门"等结果数据. 该Python脚本主要是实现以上功能. 其中,使用BeautifulSoup来解析HTML,可以参考我的另外一篇文章:Windows8下安装BeautifulSoup 代码如下: 复制代码 代码如下: __author__ = '曾是土木人' # -*- coding: utf-8 -*- #采集SERP搜索结果标题 import urllib2 fr
-
Python爬虫爬取百度搜索内容代码实例
这篇文章主要介绍了Python爬虫爬取百度搜索内容代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 搜索引擎用的很频繁,现在利用Python爬虫提取百度搜索内容,同时再进一步提取内容分析就可以简便搜索过程.详细案例如下: 代码如下 # coding=utf8 import urllib2 import string import urllib import re import random #设置多个user_agents,防止百度限制I
-
python采集百度搜索结果带有特定URL的链接代码实例
这篇文章主要介绍了python采集百度搜索结果带有特定URL的链接代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #coding utf-8 import requests from bs4 import BeautifulSoup as bs import re from Queue import Queue import threading from argparse import ArgumentParser arg = Argu
-
python+selenium实现自动化百度搜索关键词
通过python配合爬虫接口利用selenium实现自动化打开chrome浏览器,进行百度关键词搜索. 1.安装python3,访问官网选择对应的版本安装即可,最新版为3.7. 2.安装selenium库. 使用 pip install selenium 安装即可. 同时需要安装chromedriver,并放在python安装文件夹下,如下图所示. 3.获取爬虫接口链接. 注册账号,点击爬虫代理,领取每日试用. from selenium import webdriver import requ
-
python实现百万答题自动百度搜索答案
用python搭建百万答题.自动百度搜索答案. 使用平台 windows7 python3.6 MIX2手机 代码原理 手机屏幕内容同步到pc端 对问题截图 对截图文字分析 用浏览器自动搜索文本 使用教程 1.使用Airdroid 将手机屏幕显示在电脑屏幕上.也可使用360手机助手实现.不涉及任何代码.实现效果如图: 2.在提问出现时,运行python程序,将问题部分截图. 这里要用到两个函数: get_point() #采集要截图的坐标,以及图片的高度宽度 window_capture()
-
Python使用Selenium自动进行百度搜索的实现
目录 安装 Selenium 写代码 点位网页元素 我们今天介绍一个非常适合新手的python自动化小项目,项目虽小,但是五脏俱全.它是一个自动化操作网页浏览器的小应用:打开浏览器,进入百度网页,搜索关键词,最后把搜索结果保存到一个文件里.这个例子非常适合新手学习Python网络自动化,不仅能够了解如何使用Selenium,而且还能知道一些超级好用的小工具. 当然有人把操作网页,然后把网页的关键内容保存下来的应用一律称作网络爬虫,好吧,如果你想这么爬取内容,随你.但是,我更愿意称它为网络机器人.
-
Python10行代码实现模拟百度搜索的示例
目录 1. 获取百度搜索接口 2. 指定搜索内容 3. UA伪装 4. 将响应内容写入文件 5. 使用浏览器打开页面 1000块钱做个百度?能提出这种要求的客户实乃乙方克星.民族之光.科创永动机.西虹市一大杰出青年,诺奖永远得不到的人才. 但作为一个硬核的程序员,没有什么功能是我们实现不了的,如果有,那就是钱没到位.因此,我们要用魔法打败魔法,10行代码给他写一个百度搜索. 1. 获取百度搜索接口 地址栏中有很多参数,但实际有用的参数只有 wd ,只需要保留这一个参数即可,其余删掉. url =
-
JS实现模拟百度搜索“2012世界末日”网页地震撕裂效果代码
本文实例讲述了JS实现模拟百度搜索"2012世界末日"网页地震撕裂效果代码.分享给大家供大家参考,具体如下: 这是一款JS模拟百度搜索"2012世界末日"网页地震撕裂效果,本效果是模仿用户在百度输入"2012世界末日"后点击搜索后出来的网页效果,网页在震动,像是地震了,而后开始撕裂,然后显示出相关的文字说明,很酷的效果,希望大家可以学习借鉴. 运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/js-
-
JSONP跨域模拟百度搜索
目录 一.什么是JSONP 二.JSONP跨域请求 三.模拟百度搜索 四.JSONP缺点 一.什么是JSONP JSONP是JSON with padding(填充式JSON或参数式JSON)的简写,是应用JSON的一种新方法,在后来的Web服务中非常流行,JSONP看起来与JSON差不多,只不过是被包含在函数中调用的JSON,就像下面这样: callback({"name": "王欢"}); SONP由两部分组成:回调函数和数据.回调函数是当响应到来时应该在页面
-
JS模拟百度搜索框和选项卡的实现
目录 练习1 练习2,选项卡,详细代码如下: 练习1 实现搜索框内,输入相关数字,在下方显示相关内容,模拟百度搜索,详细代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> &l
-
jQuery使用jsonp实现百度搜索的示例代码
项目实现:还原百度搜索功能: 项目原理:利用json回调页面传参; 什么是jsonp:就是利用<script>标签的src地址,让目标页面回调本地页面,并且带入参数,也解决了跨域问题: 代码如下: html(css代码不提供) <div class="box"> <input type="text" /> <div class="ssk"></div> <button>×&l
-
100 行代码实现Flutter自定义TabBar的示例代码
Flutter 的确很强大,但美中不足的是生态还有待完善,没有出现像前端的 Antd 或 Element 那样全能的基础 UI 库. 由此带来的直接影响是开发效率提不上去,需要耗费大量的时间精力在基础组件的封装上. 官方的 TabBar 不满足需求,又没有合适的轮子,只好自己造轮子啦.接下来带你一步步实现自定义 TabBar-- 一.目标和效果 需求目标是: 这个页面不要 material 左侧统一的返回键和 Title 在右侧有取消按钮,点取消即返回 点击 Tab 可以实现 content 切
-
Python通过90行代码搭建一个音乐搜索工具
下面小编把具体实现代码给大家分享如下: 之前一段时间读到了这篇博客,其中描述了作者如何用java实现国外著名音乐搜索工具shazam的基本功能.其中所提到的文章又将我引向了关于shazam的一篇论文及另外一篇博客.读完之后发现其中的原理并不十分复杂,但是方法对噪音的健壮性却非常好,出于好奇决定自己用python自己实现了一个简单的音乐搜索工具-- Song Finder, 它的核心功能被封装在SFEngine 中,第三方依赖方面只使用到了 scipy. 工具demo 这个demo在ipython
-
Android几行代码实现监听微信聊天示例
现在适配微信版本更加容易了,只需要替换一个Recourse-ID即可 可以知道对方发的是小视频还是语音,并获取秒数. 可以区分聊天信息中的图片或者表情 实现效果: 实时监听当前聊天页面的最新一条消息,效果如图: 实现原理: 同样是利用AccessibilityService辅助服务,关于这个服务类还不了解的同学可以先看下我上一篇关于抢红包的博客,原理都一样:http://www.jb51.net/article/104507.htm 1.首先我们先来看一下微信聊天界面的布局,查看方法: Andr
-
DWR实现模拟Google搜索效果实现原理及代码
复制代码 代码如下: <!-- 模拟google搜索 --> <script type="text/javascript"> /********************************可配置选项********************************/ // 被选中的相似关键字背景颜色 var selectedBgColor = "#CCCCCC"; // 未被选中的相似关键字背景颜色 var unselectedBgColo