PHP实现爬虫爬取图片代码实例
文字信息
我们尝试获取表的信息,这里,我们就用某校的课表来代替:

接下来我们就上代码:
a.php
<?php
header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init();
$url ="表的链接";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content=curl_exec($ch);
preg_match_all("/<td rowspan=\"\d\">(.*?)<\/td>\n<td rowspan=\"\d\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td>(.*?)<\/td>\n<td>(.*?)<\/td><td>(.*?)<\/td>/",$content,$matchs,PREG_SET_ORDER);
//匹配该表所用的正则
var_dump($matchs);
然后咱们就运行一下:

成功获取到课表;
图片获取
绝对链接
我们以百度图库的首页为例

b.php
<?php
header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init();
$url="http://image.baidu.com/";
curl_setopt ($ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content=curl_exec($ch);
$string=file_get_contents($url);
preg_match_all("/<img([^>]*)\s*src=('|\")([^'\"]+)('|\")/", $string,$matches);
$new_arr=array_unique($matches[3]);
foreach($new_arr as $key) {
echo "<img src=$key>";
}
然后,我们就获得了下面的页面:

相对链接
百度图库的图片的链接大部分是绝对链接,那么当我们遇到网页图片为相对链接的时候,我们该怎么处理呢?其实很简单,我们只需要将循环那部分改为
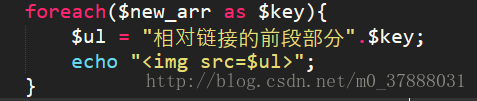
那么我们就可以同样在浏览器中输出图片了;
到此这篇关于PHP实现爬虫爬取图片代码实例的文章就介绍到这了,更多相关PHP实现爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
php远程请求CURL实例教程(爬虫、保存登录状态)
cURL cURL可以使用URL的语法模拟浏览器来传输数据,因为它是模拟浏览器,因此它同样支持多种协议,FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE 以及 LDAP等协议都可以很好的支持,包括一些:HTTPS认证,HTTP POST方法,HTTP PUT方法,FTP上传,keyberos认证,HTTP上传,代理服务器,cookies,用户名/密码认证,下载文件断点续传,上传文件断点续传,http代理服务器管道,甚至它还支持IPv6,scok
-
php与python实现的线程池多线程爬虫功能示例
本文实例讲述了php与python实现的线程池多线程爬虫功能.分享给大家供大家参考,具体如下: 多线程爬虫可以用于抓取内容了这个可以提升性能了,这里我们来看php与python 线程池多线程爬虫的例子,代码如下: php例子 <?php class Connect extends Worker //worker模式 { public function __construct() { } public function getConnection() { if (!self::$ch) { sel
-
PHPCrawl爬虫库实现抓取酷狗歌单的方法示例
本文实例讲述了PHPCrawl爬虫库实现抓取酷狗歌单的方法.分享给大家供大家参考,具体如下: 本人看了网络爬虫相关的视频后,手痒痒,想爬点什么.最近Facebook上表情包大战很激烈,就想着把所有表情包都爬下来,却一时没有找到合适的VPN,因此把酷狗最近一月精选歌曲和简单介绍抓取到本地.代码写得有点乱,自己不是很满意,并不想放上来丢人现眼.不过转念一想,这好歹是自己第一次爬虫,于是...就有了如下不堪入目的代码~~~(由于抓取的数据量较小,所以没有考虑多进程什么的,不过我看了一下PHPCrawl
-
利用php抓取蜘蛛爬虫痕迹的示例代码
前言 相信许多的站长.博主可能最关心的无非就是自己网站的收录情况,一般情况下我们可以通过查看空间服务器的日志文件来查看搜索引擎到底爬取了我们哪些个页面,不过,如果用php代码分析web日志中蜘蛛爬虫痕迹,是比较好又比较直观方便操作的!下面是示例代码,有需要的朋友们下面来一起看看吧. 示例代码 <?php //获取蜘蛛爬虫名或防采集 function isSpider(){ $bots = array( 'Google' => 'googlebot', 'Baidu' => 'baidus
-
PHP一个简单的无需刷新爬虫
由于只是一个小示例,所以过程化简单写了,小菜随便参考,大神大可点解 <?php //设置最大执行时间 set_time_limit(0); function getHtml($url){ // 1. 初始化 $ch = curl_init(); // 2. 设置选项,包括URL curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_setopt($ch,CURLOPT_HEADER,0
-

PHP实现爬虫爬取图片代码实例
文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php <?php header( "Content-type:text/html;Charset=utf-8" ); $ch = curl_init(); $url ="表的链接"; curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) A
-
python3 爬取图片的实例代码
具体代码如下所示: #coding=utf8 from urllib import request import re import urllib,os url='http://tieba.baidu.com/p/3840085725' def get_image(url): #获取页面源码 page = urllib.request.urlopen(url) html = page.read() #解码,否则报错 html = html.decode('utf8') #正则匹配获取()的内容
-
python爬虫爬取图片的简单代码
Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现.只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求. 1.spider原理 spider就是定义爬取的动作及分析网站的地方. 以初始的URL**初始化Request**,并设置回调函数. 当该request**下载完毕并返回时,将生成**response ,并作为参数传给该回调函数. 2.实现python爬虫爬取图片 第一步
-
10个python爬虫入门基础代码实例 + 1个简单的python爬虫完整实例
本文主要涉及python爬虫知识点: web是如何交互的 requests库的get.post函数的应用 response对象的相关函数,属性 python文件的打开,保存 代码中给出了注释,并且可以直接运行哦 如何安装requests库(安装好python的朋友可以直接参考,没有的,建议先装一哈python环境) windows用户,Linux用户几乎一样: 打开cmd输入以下命令即可,如果python的环境在C盘的目录,会提示权限不够,只需以管理员方式运行cmd窗口 pip install
-
Python网络爬虫信息提取mooc代码实例
实例一--爬取页面 import requests url="https//itemjd.com/2646846.html" try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[:1000]) except: print("爬取失败") 正常页面爬取 实例二--爬取页面 import requests url="https://w
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
java实现爬虫爬网站图片的实例代码
第一步,实现 LinkQueue,对url进行过滤和存储的操作 import java.util.ArrayList; import java.util.Collections; import java.util.HashSet; import java.util.List; import java.util.Set; public class LinkQueue { // 已访问的 url 集合 private static Set<String> visitedUrl = Collecti
-
python面向对象多线程爬虫爬取搜狐页面的实例代码
首先我们需要几个包:requests, lxml, bs4, pymongo, redis 1. 创建爬虫对象,具有的几个行为:抓取页面,解析页面,抽取页面,储存页面 class Spider(object): def __init__(self): # 状态(是否工作) self.status = SpiderStatus.IDLE # 抓取页面 def fetch(self, current_url): pass # 解析页面 def parse(self, html_page): pass
-
Python爬虫爬取煎蛋网图片代码实例
这篇文章主要介绍了Python爬虫爬取煎蛋网图片代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天,试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代码: import urllib.request import os def url_open(url): req = urllib.reques