一小时学会TensorFlow2之Fashion Mnist
目录
- 描述
- Tensorboard
- 创建 summary
- 存入数据
- metrics
- metrics.Mean()
- metrics.Accuracy()
- 变量更新 &重置
- 案例
- pre_process 函数
- get_data 函数
- train 函数
- test 函数
- main 函数
- 完整代码
- 可视化
描述
Fashion Mnist 是一个类似于 Mnist 的图像数据集. 涵盖 10 种类别的 7 万 (6 万训练集 + 1 万测试集) 个不同商品的图片.

Tensorboard
Tensorboard 是 tensorflow 的一个可视化工具.

创建 summary
我们可以通过tf.summary.create_file_writer(file_path)来创建一个新的 summary 实例.
例子:
# 将当前时间作为子文件名
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
# 监听的文件的路径
log_dir = 'logs/' + current_time
# 创建writer
summary_writer = tf.summary.create_file_writer(log_dir)
存入数据
通过tf.summary.scalar我们可以向 summary 对象存入数据.
格式:
tf.summary.scalar(
name, data, step=None, description=None
)
例子:
with summary_writer.as_default():
tf.summary.scalar("train-loss", float(Cross_Entropy), step=step)
metrics

metrics.Mean()
metrics.Mean()可以帮助我们计算平均数.
格式:
tf.keras.metrics.Mean(
name='mean', dtype=None
)
例子:
# 准确率表 loss_meter = tf.keras.metrics.Mean()
metrics.Accuracy()
格式:
tf.keras.metrics.Accuracy(
name='accuracy', dtype=None
)
例子:
# 损失表 acc_meter = tf.keras.metrics.Accuracy()
变量更新 &重置
我们可以通过update_state来实现变量更新, 通过rest_state来实现变量重置.
例如:
# 跟新损失 loss_meter.update_state(Cross_Entropy) # 重置 loss_meter.reset_state()
案例
pre_process 函数
def pre_process(x, y):
"""
数据预处理
:param x: 特征值
:param y: 目标值
:return: 返回处理好的x, y
"""
# 转换x
x = tf.cast(x, tf.float32) / 255
x = tf.reshape(x, [-1, 784])
# 转换y
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
get_data 函数
def get_data():
"""
获取数据
:return: 返回分批完的训练集和测试集
"""
# 获取数据
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# 分割训练集
train_db = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(60000, seed=0)
train_db = train_db.batch(batch_size).map(pre_process)
# 分割测试集
test_db = tf.data.Dataset.from_tensor_slices((X_test, y_test)).shuffle(10000, seed=0)
test_db = test_db.batch(batch_size).map(pre_process)
# 返回
return train_db, test_db
train 函数
def train(epoch, train_db):
"""
训练数据
:param train_db: 分批的数据集
:return: 无返回值
"""
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# 获取模型输出结果
logits = model(x)
# 计算交叉熵
Cross_Entropy = tf.losses.categorical_crossentropy(y, logits, from_logits=True)
Cross_Entropy = tf.reduce_sum(Cross_Entropy)
# 跟新损失
loss_meter.update_state(Cross_Entropy)
# 计算梯度
grads = tape.gradient(Cross_Entropy, model.trainable_variables)
# 跟新参数
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 每100批调试输出一下误差
if step % 100 == 0:
print("step:", step, "Cross_Entropy:", loss_meter.result().numpy())
# 重置
loss_meter.reset_state()
# 可视化
with summary_writer.as_default():
tf.summary.scalar("train-loss", float(Cross_Entropy), step= epoch * 235 + step)
test 函数
def test(epoch, test_db):
"""
测试模型
:param epoch: 轮数
:param test_db: 分批的测试集
:return: 无返回值
"""
# 重置
acc_meter.reset_state()
for x, y in test_db:
# 获取模型输出结果
logits = model(x)
# 预测结果
pred = tf.argmax(logits, axis=1)
# 从one_hot编码变回来
y = tf.argmax(y, axis=1)
# 计算准确率
acc_meter.update_state(y, pred)
# 调试输出
print("epoch:", epoch + 1, "Accuracy:", acc_meter.result().numpy() * 100, "%", )
# 可视化
with summary_writer.as_default():
tf.summary.scalar("val-acc", acc_meter.result().numpy(), step=epoch * 235)
main 函数
def main():
"""
主函数
:return: 无返回值
"""
# 获取数据
train_db, test_db = get_data()
# 轮期
for epoch in range(iteration_num):
train(epoch, train_db)
test(epoch, test_db)
完整代码
import datetime
import tensorflow as tf
# 定义超参数
batch_size = 256 # 一次训练的样本数目
learning_rate = 0.001 # 学习率
iteration_num = 20 # 迭代次数
# 优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
# 准确率表
loss_meter = tf.keras.metrics.Mean()
# 损失表
acc_meter = tf.keras.metrics.Accuracy()
# 可视化
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
log_dir = 'logs/' + current_time
summary_writer = tf.summary.create_file_writer(log_dir) # 创建writer
# 模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(32, activation=tf.nn.relu),
tf.keras.layers.Dense(10)
])
# 调试输出summary
model.build(input_shape=[None, 28 * 28])
print(model.summary())
def pre_process(x, y):
"""
数据预处理
:param x: 特征值
:param y: 目标值
:return: 返回处理好的x, y
"""
# 转换x
x = tf.cast(x, tf.float32) / 255
x = tf.reshape(x, [-1, 784])
# 转换y
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
def get_data():
"""
获取数据
:return: 返回分批完的训练集和测试集
"""
# 获取数据
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# 分割训练集
train_db = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(60000, seed=0)
train_db = train_db.batch(batch_size).map(pre_process)
# 分割测试集
test_db = tf.data.Dataset.from_tensor_slices((X_test, y_test)).shuffle(10000, seed=0)
test_db = test_db.batch(batch_size).map(pre_process)
# 返回
return train_db, test_db
def train(epoch, train_db):
"""
训练数据
:param train_db: 分批的数据集
:return: 无返回值
"""
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# 获取模型输出结果
logits = model(x)
# 计算交叉熵
Cross_Entropy = tf.losses.categorical_crossentropy(y, logits, from_logits=True)
Cross_Entropy = tf.reduce_sum(Cross_Entropy)
# 跟新损失
loss_meter.update_state(Cross_Entropy)
# 计算梯度
grads = tape.gradient(Cross_Entropy, model.trainable_variables)
# 跟新参数
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 每100批调试输出一下误差
if step % 100 == 0:
print("step:", step, "Cross_Entropy:", loss_meter.result().numpy())
# 重置
loss_meter.reset_state()
# 可视化
with summary_writer.as_default():
tf.summary.scalar("train-loss", float(Cross_Entropy), step=epoch * 235 + step)
def test(epoch, test_db):
"""
测试模型
:param epoch: 轮数
:param test_db: 分批的测试集
:return: 无返回值
"""
# 重置
acc_meter.reset_state()
for x, y in test_db:
# 获取模型输出结果
logits = model(x)
# 预测结果
pred = tf.argmax(logits, axis=1)
# 从one_hot编码变回来
y = tf.argmax(y, axis=1)
# 计算准确率
acc_meter.update_state(y, pred)
# 调试输出
print("epoch:", epoch + 1, "Accuracy:", acc_meter.result().numpy() * 100, "%", )
# 可视化
with summary_writer.as_default():
tf.summary.scalar("val-acc", acc_meter.result().numpy(), step=epoch * 235)
def main():
"""
主函数
:return: 无返回值
"""
# 获取数据
train_db, test_db = get_data()
# 轮期
for epoch in range(iteration_num):
train(epoch, train_db)
test(epoch, test_db)
if __name__ == "__main__":
main()
输出结果:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 256) 200960
_________________________________________________________________
dense_1 (Dense) (None, 128) 32896
_________________________________________________________________
dense_2 (Dense) (None, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 32) 2080
_________________________________________________________________
dense_4 (Dense) (None, 10) 330
=================================================================
Total params: 244,522
Trainable params: 244,522
Non-trainable params: 0
_________________________________________________________________
None
2021-06-14 18:01:27.399812: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:176] None of the MLIR Optimization Passes are enabled (registered 2)
step: 0 Cross_Entropy: 591.5974
step: 100 Cross_Entropy: 196.49309
step: 200 Cross_Entropy: 125.2562
epoch: 1 Accuracy: 84.72999930381775 %
step: 0 Cross_Entropy: 107.64579
step: 100 Cross_Entropy: 105.854385
step: 200 Cross_Entropy: 99.545975
epoch: 2 Accuracy: 85.83999872207642 %
step: 0 Cross_Entropy: 95.42945
step: 100 Cross_Entropy: 91.366234
step: 200 Cross_Entropy: 90.84072
epoch: 3 Accuracy: 86.69999837875366 %
step: 0 Cross_Entropy: 82.03317
step: 100 Cross_Entropy: 83.20552
step: 200 Cross_Entropy: 81.57012
epoch: 4 Accuracy: 86.11000180244446 %
step: 0 Cross_Entropy: 82.94046
step: 100 Cross_Entropy: 77.56677
step: 200 Cross_Entropy: 76.996346
epoch: 5 Accuracy: 87.27999925613403 %
step: 0 Cross_Entropy: 75.59219
step: 100 Cross_Entropy: 71.70899
step: 200 Cross_Entropy: 74.15144
epoch: 6 Accuracy: 87.29000091552734 %
step: 0 Cross_Entropy: 76.65844
step: 100 Cross_Entropy: 70.09151
step: 200 Cross_Entropy: 70.84446
epoch: 7 Accuracy: 88.27999830245972 %
step: 0 Cross_Entropy: 67.50707
step: 100 Cross_Entropy: 64.85907
step: 200 Cross_Entropy: 68.63099
epoch: 8 Accuracy: 88.41999769210815 %
step: 0 Cross_Entropy: 65.50318
step: 100 Cross_Entropy: 62.2706
step: 200 Cross_Entropy: 63.80803
epoch: 9 Accuracy: 86.21000051498413 %
step: 0 Cross_Entropy: 66.95486
step: 100 Cross_Entropy: 61.84385
step: 200 Cross_Entropy: 62.18851
epoch: 10 Accuracy: 88.45999836921692 %
step: 0 Cross_Entropy: 59.779297
step: 100 Cross_Entropy: 58.602314
step: 200 Cross_Entropy: 59.837025
epoch: 11 Accuracy: 88.66000175476074 %
step: 0 Cross_Entropy: 58.10068
step: 100 Cross_Entropy: 55.097878
step: 200 Cross_Entropy: 59.906315
epoch: 12 Accuracy: 88.70999813079834 %
step: 0 Cross_Entropy: 57.584858
step: 100 Cross_Entropy: 54.95376
step: 200 Cross_Entropy: 55.797752
epoch: 13 Accuracy: 88.44000101089478 %
step: 0 Cross_Entropy: 53.54782
step: 100 Cross_Entropy: 53.62939
step: 200 Cross_Entropy: 54.632828
epoch: 14 Accuracy: 87.02999949455261 %
step: 0 Cross_Entropy: 54.387398
step: 100 Cross_Entropy: 52.323734
step: 200 Cross_Entropy: 53.968185
epoch: 15 Accuracy: 88.98000121116638 %
step: 0 Cross_Entropy: 50.468914
step: 100 Cross_Entropy: 50.79311
step: 200 Cross_Entropy: 51.296227
epoch: 16 Accuracy: 88.67999911308289 %
step: 0 Cross_Entropy: 48.753258
step: 100 Cross_Entropy: 46.809692
step: 200 Cross_Entropy: 48.08208
epoch: 17 Accuracy: 89.10999894142151 %
step: 0 Cross_Entropy: 46.830627
step: 100 Cross_Entropy: 47.208813
step: 200 Cross_Entropy: 48.671318
epoch: 18 Accuracy: 88.77999782562256 %
step: 0 Cross_Entropy: 46.15514
step: 100 Cross_Entropy: 45.026627
step: 200 Cross_Entropy: 45.371685
epoch: 19 Accuracy: 88.7399971485138 %
step: 0 Cross_Entropy: 47.696465
step: 100 Cross_Entropy: 41.52749
step: 200 Cross_Entropy: 46.71362
epoch: 20 Accuracy: 89.56000208854675 %
可视化

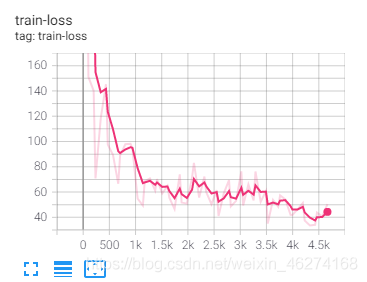
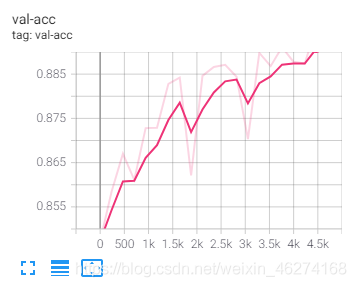
到此这篇关于一小时学会TensorFlow2之Fashion Mnist的文章就介绍到这了,更多相关TensorFlow2 Fashion Mnist内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

深度学习tensorflow基础mnist
软件架构 mnist数据集的识别使用了两个非常小的网络来实现,第一个是最简单的全连接网络,第二个是卷积网络,mnist数据集是入门数据集,所以不需要进行图像增强,或者用生成器读入内存,直接使用简单的fit()命令就可以一次性训练 安装教程 使用到的主要第三方库有tensorflow1.x,基于TensorFlow的Keras,基础的库包括numpy,matplotlib 安装方式也很简答,例如:pip install numpy -i https://pypi.tuna.tsinghua.edu
-
由浅入深学习TensorFlow MNIST 数据集
目录 MNIST 数据集介绍 LeNet 模型介绍 卷积 池化 (下采样) 激活函数 (ReLU) LeNet 逐层分析 1. 第一个卷积层 2. 第一个池化层 3. 第二个卷积层 4. 第二个池化层 5. 全连接卷积层 6. 全连接层 7. 全连接层 (输出层) 代码实现 导包 读取 & 查看数据 数据预处理 模型建立 训练模型 保存模型 流程总结 完整代码 MNIST 数据集介绍 MNIST 包含 0~9 的手写数字, 共有 60000 个训练集和 10000 个测试集. 数据的格式为单通道
-
一小时学会TensorFlow2之Fashion Mnist
目录 描述 Tensorboard 创建 summary 存入数据 metrics metrics.Mean() metrics.Accuracy() 变量更新 &重置 案例 pre_process 函数 get_data 函数 train 函数 test 函数 main 函数 完整代码 可视化 描述 Fashion Mnist 是一个类似于 Mnist 的图像数据集. 涵盖 10 种类别的 7 万 (6 万训练集 + 1 万测试集) 个不同商品的图片. Tensorboard Tensorbo
-
一小时学会TensorFlow2之基本操作1实例代码
目录 概述 创建数据 创建常量 创建数据序列 创建图变量 tf.zeros tf.ones tf.zeros_like tf.ones_like tf.fill tf.gather tf.random 正态分布 均匀分布 打乱顺序 获取数据信息 获取数据维度 数据是否为张量 数据转换 转换成张量 转换数据类型 转换成 numpy 概述 TensorFlow2 的基本操作和 Numpy 的操作很像. 今天带大家来看一看 TensorFlow 的基本数据操作. 创建数据 详细讲解一下 TensorF
-
一小时学会TensorFlow2之基本操作2实例代码
目录 索引操作 简单索引 Numpy 式索引 使用 : 进行索引 tf.gather tf.gather_nd tf.boolean_mask 切片操作 简单切片 step 切片 维度变换 tf.reshape tf.transpose tf.expand_dims tf.squeeze Boardcasting tf.boardcast_to tf.tile 数学运算 加减乘除 log & exp pow & sqrt 矩阵相乘 @ 索引操作 简单索引 索引 (index) 可以帮助我们
-
一小时学会TensorFlow2之全连接层
目录 概述 keras.layers.Dense keras.Squential 概述 全链接层 (Fully Connected Layer) 会把一个特质空间线性变换到另一个特质空间, 在整个网络中起到分类器的作用. keras.layers.Dense keras.layers.Dense可以帮助我们实现全连接. 格式: tf.keras.layers.Dense( units, activation=None, use_bias=True, kernel_initializer='glo
-
一小时学会TensorFlow2之大幅提高模型准确率
目录 过拟合 Regulation 公式 例子 动量 公式 例子 学习率递减 过程 例子 Early Stopping Dropout 过拟合 当训练集的的准确率很高, 但是测试集的准确率很差的时候就, 我们就遇到了过拟合 (Overfitting) 的问题. 如图: 过拟合产生的一大原因是因为模型过于复杂. 下面我们将通过讲述 5 种不同的方法来解决过拟合的问题, 从而提高模型准确度. Regulation Regulation 可以帮助我们通过约束要优化的参数来防止过拟合. 公式 未加入 r
-
一小时学会TensorFlow2之自定义层
目录 概述 Sequential Model & Layer 案例 数据集介绍 完整代码 概述 通过自定义网络, 我们可以自己创建网络并和现有的网络串联起来, 从而实现各种各样的网络结构. Sequential Sequential 是 Keras 的一个网络容器. 可以帮助我们将多层网络封装在一起. 通过 Sequential 我们可以把现有的层已经我们自己的层实现结合, 一次前向传播就可以实现数据从第一层到最后一层的计算. 格式: tf.keras.Sequential( layers=No
-
Python入门教程 超详细1小时学会Python
为什么使用Python 假设我们有这么一项任务:简单测试局域网中的电脑是否连通.这些电脑的ip范围从192.168.0.101到192.168.0.200. 思路:用shell编程.(Linux通常是bash而Windows是批处理脚本).例如,在Windows上用ping ip 的命令依次测试各个机器并得到控制台输出.由于ping通的时候控制台文本通常是"Reply from ... " 而不通的时候文本是"time out ... " ,所以,在结果中进行
-
mysql入门之1小时学会MySQL基础
MySQL入门 mySQL (关系型数据库管理系统) MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件. MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高
-
一个小时学会MySQL数据库(张果)
随着移动互联网的结束与人工智能的到来大数据变成越来越重要,下一个成功者应该是拥有海量数据的,数据与数据库你应该知道. 一.数据库概要 数据库(Database)是存储与管理数据的软件系统,就像一个存入数据的物流仓库. 在商业领域,信息就意味着商机,取得信息的一个非常重要的途径就是对数据进行分析处理,这就催生了各种专业的数据管理软件,数据库就是其中的一种.当然,数据库管理系统也不是一下子就建立起来,它也是经过了不断的丰富和发展,才有了今天的模样. 1.1.发展历史 1.1.1.人工处理阶段 在20
-
Java实现贪吃蛇游戏(1小时学会)
今天就来拿贪吃蛇小游戏来练练手吧! 贪吃蛇游戏规则: 1.按下空格键(游戏未结束)则游戏暂停或开始: 2.按下空格键(游戏结束后)则游戏重新开始: 3.当贪吃蛇的头部撞到身体时则贪吃蛇死亡(游戏结束): 4.当贪吃蛇的头部撞到墙时贪吃蛇死亡(游戏结束): 游戏界面效果: 我们可以看到自己的贪吃蛇吃了多少食物,以及游戏得分.下面是游戏效果图: 源码(注释超详细,注意ImageDate类中的material是一个包名,里面存放的是游戏素材图片): package program_code; impo