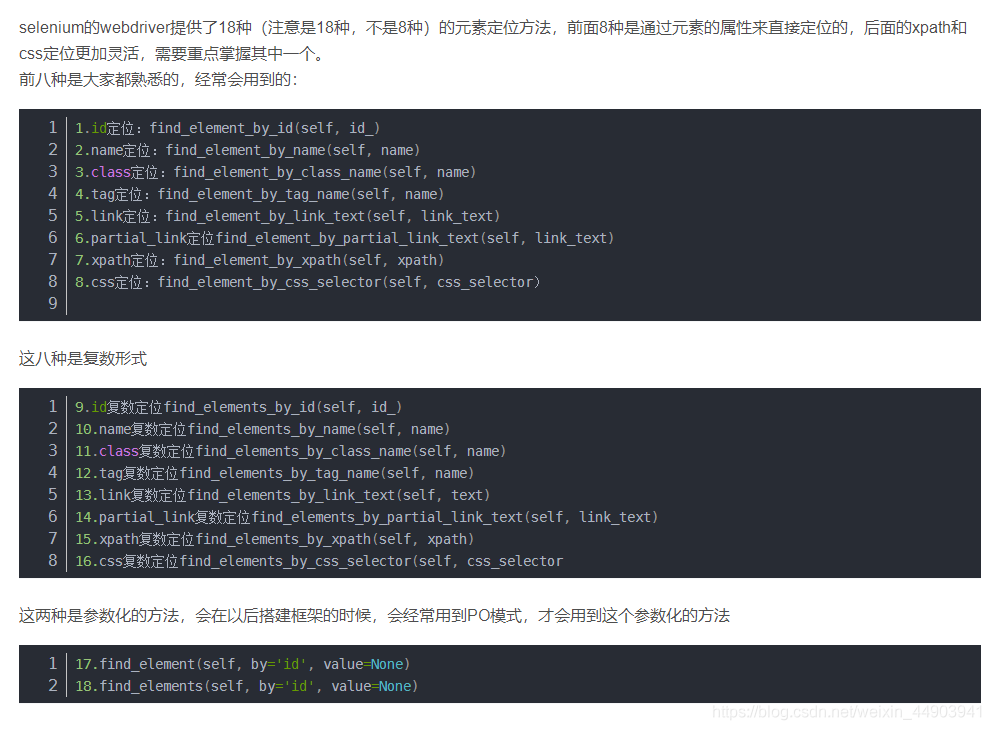
详解Python自动化中这八大元素定位
一、find_element_by_id()
find_element_by_id()
1.从上面定位到的元素属性中,可以看到有个id属性:id=“kw”,这里可以通过它的id属性定位到这个元素。
2.定位到搜索框后,用send_keys()方法,就可以输入文本。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 通过id定位百度输入框,并输入'python'
ss = driver.find_element_by_id('kw')
ss.send_keys('python')
二、find_element_by_name()
find_element_by_name()
1.从上面定位到的元素属性中,可以看到有个name属性:name=“wd”,这里可以通过它的name属性单位到这个元素。
说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 通过name定位百度输入框,并输入'python'
ss = driver.find_element_by_name('wd')
ss.send_keys('python')
三、find_element_by_class_name()
find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class=“s_ipt”,这里可以通过它的class属性定位到这个元素。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#通过class定位百度输入框,并输入'python'
driver.find_element_by_class_name('s_ipt').send_keys('python')
四、find_element_by_tag_name()
find_element_by_tag_name()
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input。
2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#通过tag(标签)定位百度输入框,并输入'python'
ss = driver.find_element_by_tag_name('input')
ss.send_keys('python')
五、find_element_by_link_text()
1.定位百度页面上"hao123"这个按钮
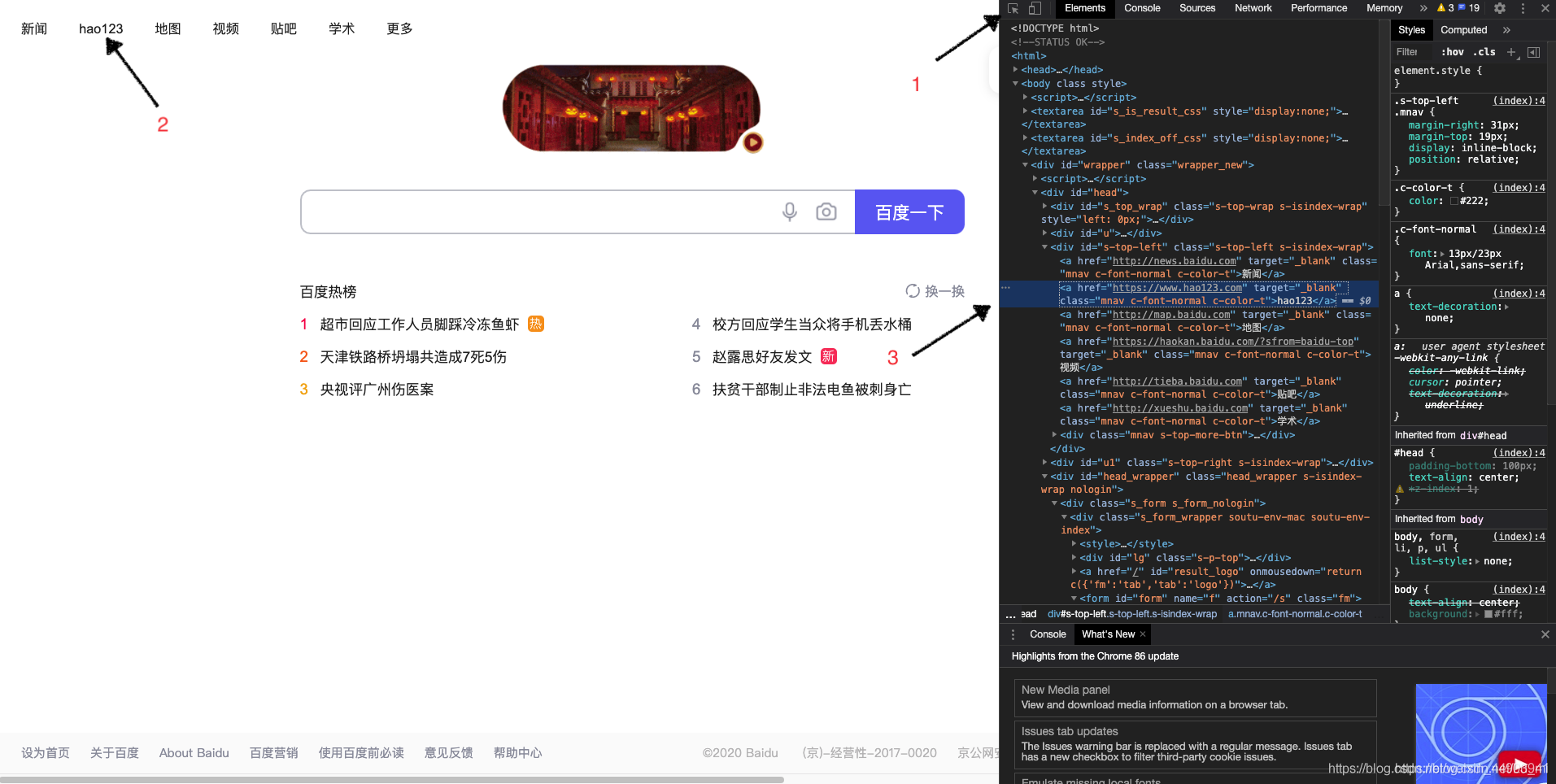
查看页面元素:
<a class="mnav" target="_blank" href="http://www.hao123.com" rel="external nofollow" >hao123</a>
2.从元素属性可以分析出,有个href = "http://www.hao123.com
说明它是个超链接,对于这种元素,可以用以下方法:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过tlink(超链接)定位百度输入框,并点击
driver.find_element_by_link_name('hao123').click()
六、find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
2.如“hao123”,只需输入“ao123”也可以定位到
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过partial_link定位百度输入框,并点击(partial_link是一种模糊匹配的方式)
driver.find_element_by_partial_link_name('hao123').click()
七、find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决。
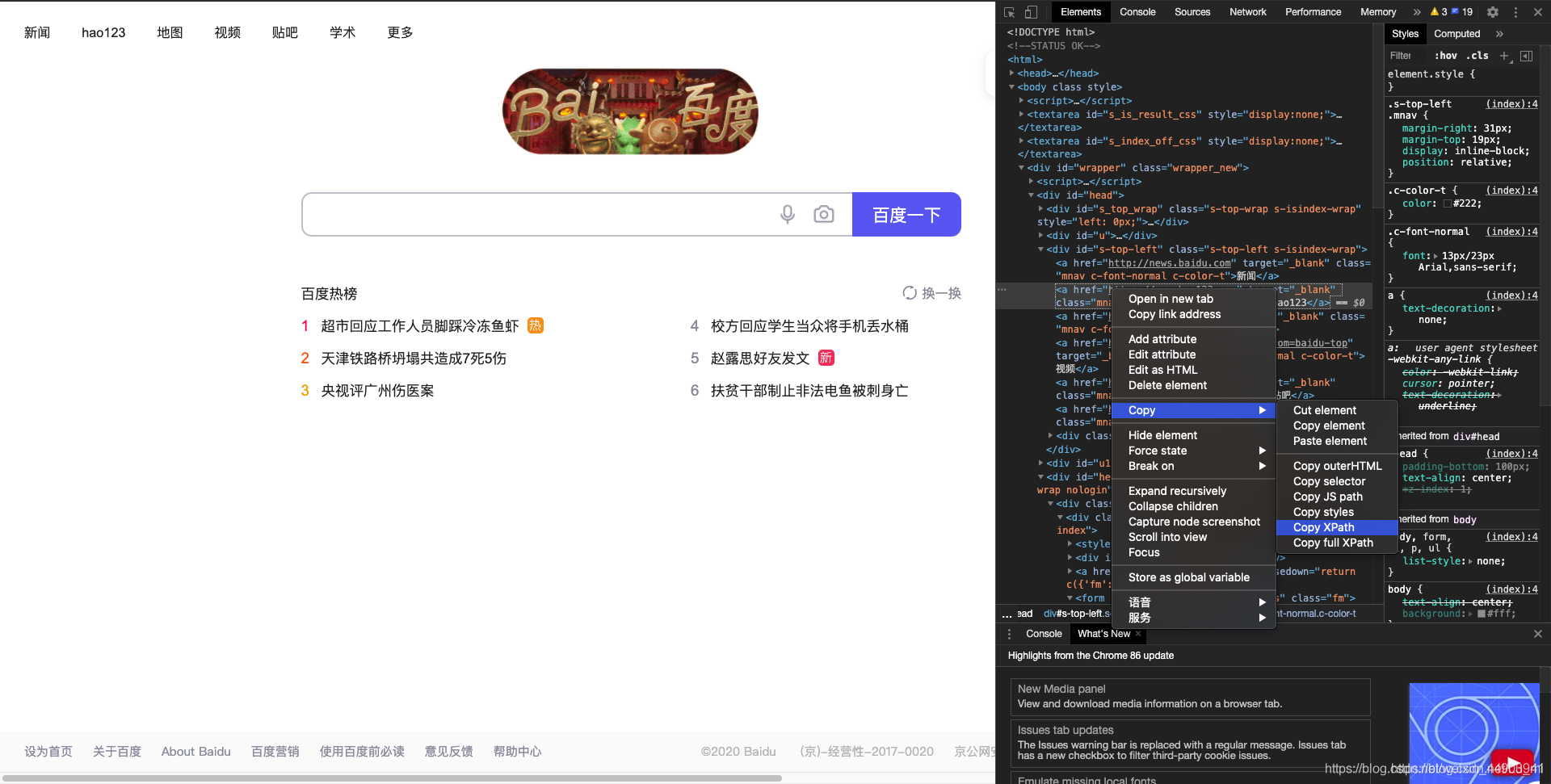
2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会查看一个元素的xpath。
- 对于谷歌浏览器来说,有自己 的xpath解析工具:鼠标移到需要查看的html源码上,右击
- 选择copy
- copy xpath,就是源码的xpath路径
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过xpath地址定位百度输入框,并点击(xpath地址即为赋值过来的地址)
driver.find_element_by_xpath('//*[@id="s-top-left"]/a[2]').click()
八、find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解
- 对于谷歌浏览器来说,同样有自己 的css解析工具:鼠标移到需要查看的html源码上,右击
- 选择copy
- copy selector,就是源码的css路径

from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过css地址定位百度输入框,并点击
driver.find_element_by_xpath('#s-top-left > a:nth-child(2)').click()
总结:
到此这篇关于详解Python自动化中这八大元素定位的文章就介绍到这了,更多相关Python元素定位内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
selenium+python自动化测试之页面元素定位
上一篇博客selenium+python自动化测试(二)–使用webdriver操作浏览器讲解了使用webdriver操作浏览器的各种方法,可以实现对浏览器进行操作了,接下来就是对浏览器页面中的元素进行操作,操作页面元素,首先要找到操作的元素,对元素进行定位 查看页面源码 要定位页面元素,需要找到页面的源码,IE浏览器中,打开页面后,在页面上点击鼠标右键,会有"查看源代码"的选项,点击后就会进入页面源码页面,在这里就可以找到页面的所有元素 使用Chrome浏览器打开页面后,在浏览器的地
-
基于python全局设置id 自动化测试元素定位过程解析
背景: 在自动化化测试过程中,不方便准确获取页面的元素,或者在重构过程中方法修改造成元素层级改变,因此通过设置id准备定位. 一.python准备工作: 功能:用自动化的方式进行批量处理. 比如,你想要在大量的文本文件中执行查找/替换,或者以复杂的方式对大量的图片进行重命名和整理. 语法用例: #!/usr/bin/python //脚本语言的第一行,只对 Linux/Unix 用户适用,用来指定本脚本用什么解释器来执行,即:调用 /usr/bin 下的 python 解释器,推荐使用#!/us
-

详解Python自动化中这八大元素定位
一.find_element_by_id() find_element_by_id() 1.从上面定位到的元素属性中,可以看到有个id属性:id="kw",这里可以通过它的id属性定位到这个元素. 2.定位到搜索框后,用send_keys()方法,就可以输入文本. from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 通过id定
-
详解Python自动化之文件自动化处理
一.生成随机的测验试卷文件 假如你是一位地理老师, 班上有 35 名学生, 你希望进行美国各州首府的一个小测验.不妙的是,班里有几个坏蛋, 你无法确信学生不会作弊.你希望随机调整问题的次序, 这样每份试卷都是独一无二的, 这让任何人都不能从其他人那里抄袭答案.当然,手工完成这件事又费时又无聊. 下面是程序所做的事: • 创建 35 份不同的测验试卷. • 为每份试卷创建 50 个多重选择题,次序随机. • 为每个问题提供一个正确答案和 3 个随机的错误答案,次序随机. • 将测验试卷写到 35
-
详解Python遍历列表时删除元素的正确做法
一.问题描述 这是在工作中遇到的一段代码,原理大概和下面类似(判断某一个元素是否符合要求,不符合删除该元素,最后得到符合要求的列表): a = [1,2,3,4,5,6,7,8] for i in a: if i>5: pass else: a.remove(i) print(a) 运行结果: 二.问题分析 因为删除元素后,整个列表的元素会往前移动,而i却是在最初就已经确定了,是不断增大的,所以并不能得到想要的结果. 三.解决方法 1.遍历在新的列表操作,删除是在原来的列表操作 a = [1,2
-
详解Python NumPy中矩阵和通用函数的使用
目录 一.创建矩阵 二.从已有矩阵创建新矩阵 三.通用函数 四.算术运算 在NumPy中,矩阵是 ndarray 的子类,与数学概念中的矩阵一样,NumPy中的矩阵也是二维的,可以使用 mat . matrix 以及 bmat 函数来创建矩阵. 一.创建矩阵 mat 函数创建矩阵时,若输入已为 matrix 或 ndarray 对象,则不会为它们创建副本. 因此,调用 mat() 函数和调用 matrix(data, copy=False) 等价. 1) 在创建矩阵的专用字符串中,矩阵的行与行之
-
详解python程序中的多任务
现实生活中,有很多场景中的事情是同时进行的,比如开车的时候,手和脚共同来驾驶汽车,再比如唱歌跳舞也是同时进行的. 以上这些可以理解为多任务.那在程序中怎么能做到多任务,它有什么好处? 接下来我们来看看没有多任务的程序是什么效果. import time def sing(): for i in range(5): print("正在唱...") time.sleep(1) def dance(): for i in range(5): print("正在跳...")
-
详解python数组中的符号...与:符号的不同之处
不知道大家有没有见过在python数组中使用...符号,因为前段时间读别人代码的时候遇到了这个符号立刻就云里雾里,于是这里特此记录一下.先来看一段代码: import numpy as np x = np.array([[1, 3], [5, 6], [8, 10]]) print("使用'...'符号的结果为:") print(x[..., 0]) print("使用':'符号的结果为:") print(x[:, 0]) """ 使用
-
详解python requests中的post请求的参数问题
问题:最新在爬取某站点的时候,发现在post请求当中,参数构造正确却获取不到数据,索性将post的参数urlencode之后放到post请求的url后面变成get请求,结果成功获取到数据,对此展开疑问. 1.http请求中Form Data和Request Playload的区别: Ajax post请求中常用的两种参数形式:form data 和 request payload get请求的时候,我们的参数直接反映在url里面,为key1=value1&key2=value2形式,如果是pos
-
详解Python异常处理中的Finally else的功能
Python使用Try Exception来处理异常机制 若Exception中有Try对应的异常处理,则Try - exception之后的代码将被执行,但若Try - exception中没有对应的代码,则程序抛出Traceback停止运行 那么else finally就是针对这两种情况带来的后果分别相应的关键字 else 如果一个Try - exception中,没有发生异常,即exception没有执行,那么将会执行else语句的内容 反之,如果触发了Try - exception(异常
-
详解Python odoo中嵌入html简单的分页功能
在odoo中,通过iframe嵌入 html,页面数据则通过controllers获取,使用jinja2模板传值渲染 html页面分页内容,这里写了判断逻辑 <!-- 分页 --> <ul id="ty_paging"> <li class="home" id="home"><a href="/car/budget/report/1" rel="external nofoll
-
详解Vue项目中实现锚点定位
背景 今天在开发限时练-提分加项目的时候,有一个需要锚点定位的需求,而在Vue项目中,使用传统的在a标签的href属性中写id的方法无效,会导致浏览器的地址改变从而跳转到其他页面. 解决 最终参考vue2.0中怎么做锚点定位改问题下的回答实现了效果. <template> <div class="score-preview-container"> <div class="content-box"> <div class=&q