用Python爬取各大高校并可视化帮弟弟选大学,弟弟直呼牛X
一、获取url
打开中国教育在线网,按 F12,顶部选择NetWork,选择XHR
刷新页面,观察url,通过对Reponse的分析找到真正的url为:https://api.eol.cn/gkcx/api/
数据存储在Json中。

再点击Headers,查看请求参数

请求方式为POST
二、发送请求
拿到url,我们就可以利用requests模拟浏览器发送请求,拿到返回的Json数据。代码如下:
# 导入包
import numpy as np
import pandas as pd
import requests
import json
from fake_useragent import UserAgent
import time
# 获取一页
def get_one_page(page_num):
# 获取URL
url = 'https://api.eol.cn/gkcx/api/'
# 构造headers
headers = {
'User-Agent': UserAgent().random,
'Origin': 'https://gkcx.eol.cn',
'Referer': 'https://gkcx.eol.cn/school/search?province=&schoolflag=&recomschprop=',
}
# 构造data
data = {
'access_token': "",
'admissions': "",
'central': "",
'department': "",
'dual_class': "",
'f211': "",
'f985': "",
'is_dual_class': "",
'keyword': "",
'page': page_num,
'province_id': "",
'request_type': 1,
'school_type': "",
'size': 20,
'sort': "view_total",
'type': "",
'uri': "apigkcx/api/school/hotlists",
}
# 发起请求
try:
response = requests.post(url=url, data=data, headers=headers)
except Exception as e:
print(e)
time.sleep(3)
response = requests.post(url=url, data=data, headers=headers)
三、解析json数据
根据Response返回的Json格式,解析出我们想要的内容,代码如下:
# 解析获取数据
school_data = json.loads(response.text)['data']['item']
# 学校名
school_name = [i.get('name') for i in school_data]
# 隶属部门
belong = [i.get('belong') for i in school_data]
# 高校层次
dual_class_name = [i.get('dual_class_name') for i in school_data]
# 是否985
f985 = [i.get('f985') for i in school_data]
# 是否211
f211 = [i.get('f211') for i in school_data]
# 办学类型
level_name = [i.get('level_name') for i in school_data]
# 院校类型
type_name = [i.get('type_name') for i in school_data]
# 是否公办
nature_name = [i.get('nature_name') for i in school_data]
# 人气值
view_total = [i.get('view_total') for i in school_data]
# 省份
province_name = [i.get('province_name') for i in school_data]
# 城市
city_name = [i.get('city_name') for i in school_data]
# 区域
county_name = [i.get('county_name') for i in school_data]
# 保存数据
df_one = pd.DataFrame({
'school_name': school_name,
'belong': belong,
'dual_class_name': dual_class_name,
'f985': f985,
'f211': f211,
'level_name': level_name,
'type_name': type_name,
'nature_name': nature_name,
'view_total': view_total,
'province_name': province_name,
'city_name': city_name,
'county_name': county_name,
})
return df_one
四、存入Excel
先将数据存入Pandas,用于做数据分析,再写入Excel存储。
# 获取多页
def get_all_page(all_page_num):
# 存储表
df_all = pd.DataFrame()
# 循环页数
for i in range(all_page_num):
# 打印进度
print(f'正在获取第{i + 1}页的高校信息')
# 调用函数
df_one = get_one_page(page_num=i+1)
# 追加
df_all = df_all.append(df_one, ignore_index=True)
# 休眠
time.sleep(np.random.uniform(2))
return df_all
# 运行函数
df_school = get_all_page(all_page_num=143)
# 读出数据
df_school.to_excel('./data/全国高校数据.xlsx', index=False)
五、运行代码
六、数据展示

七、数据可视化
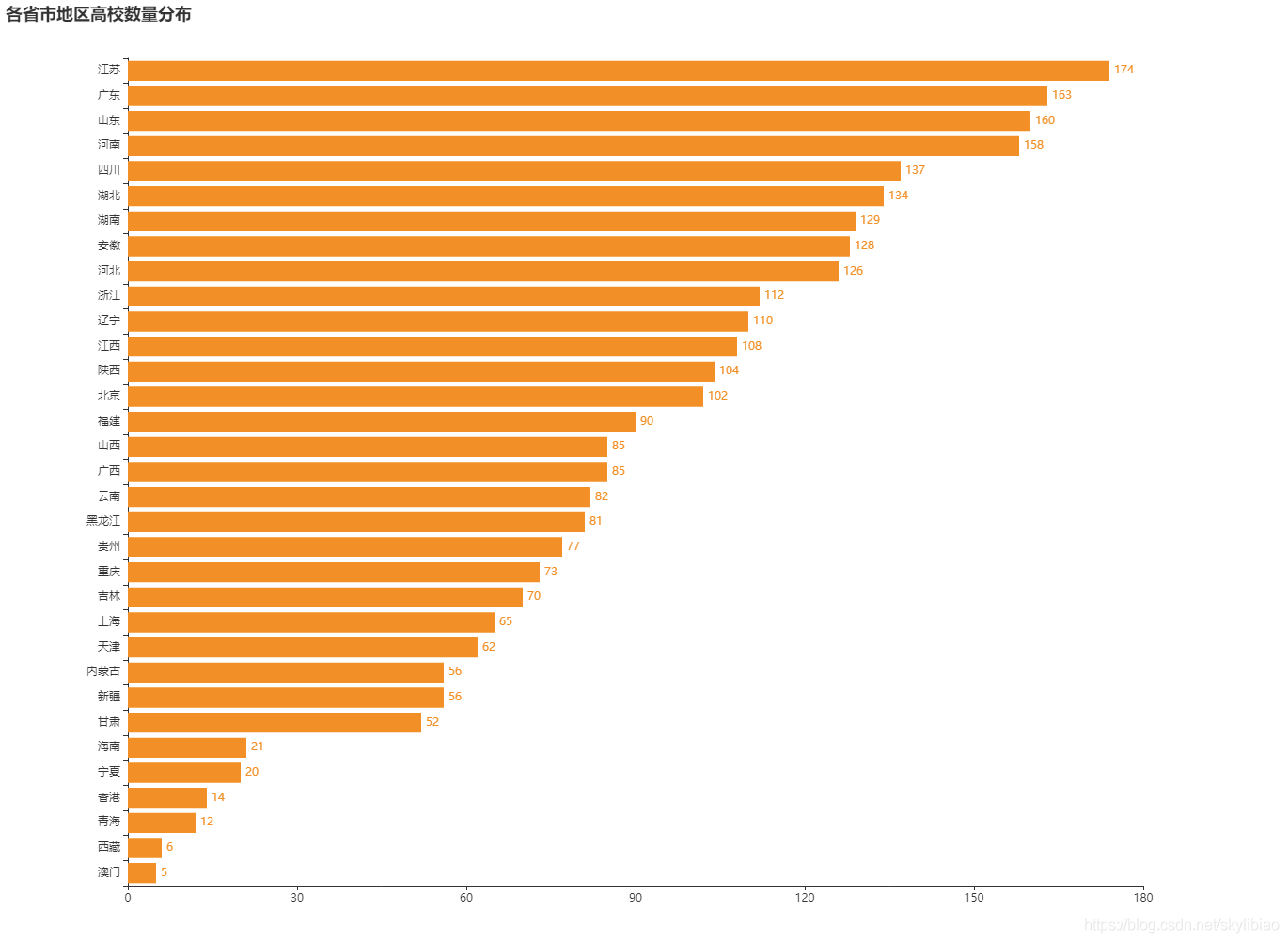
1.各省市地区高校数量分布 柱形图:
地图

各个省的高校层次分布

全国高校类型分布

有了上面的数据,是不是对全国的高校有一定了解了
到此这篇关于用Python爬取各大高校并可视化帮弟弟选大学,弟弟直呼牛X的文章就介绍到这了,更多相关Python爬取数据并可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬取数据并实现可视化代码解析
这次主要是爬了京东上一双鞋的相关评论:将数据保存到excel中并可视化展示相应的信息 主要的python代码如下: 文件1 #将excel中的数据进行读取分析 import openpyxl import matplotlib.pyplot as pit #数据统计用的 wk=openpyxl.load_workbook('销售数据.xlsx') sheet=wk.active #获取活动表 #获取最大行数和最大列数 rows=sheet.max_row cols=sheet.max_colum
-

python如何爬取网站数据并进行数据可视化
前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做进一步的分析,其余分析和展示读者可自行发挥和扩展包括各种分析和不同的存储方式等..... 一.爬取和分析相关依赖包 Python版本: Python3.6 requests: 下载网页 math: 向上取整 time: 暂停进程 pandas:数据分析并保存为csv文件 matplotlib:
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
用Python爬取各大高校并可视化帮弟弟选大学,弟弟直呼牛X
一.获取url 打开中国教育在线网,按 F12,顶部选择NetWork,选择XHR 刷新页面,观察url,通过对Reponse的分析找到真正的url为:https://api.eol.cn/gkcx/api/ 数据存储在Json中. 再点击Headers,查看请求参数 请求方式为POST 二.发送请求 拿到url,我们就可以利用requests模拟浏览器发送请求,拿到返回的Json数据.代码如下: # 导入包 import numpy as np import pandas as pd impo
-
Python爬取股票交易数据并可视化展示
目录 开发环境 第三方模块 爬虫案例的步骤 爬虫程序全部代码 分析网页 导入模块 请求数据 解析数据 翻页 保存数据 实现效果 数据可视化全部代码 导入数据 读取数据 可视化图表 效果展示 开发环境 解释器版本: python 3.8 代码编辑器: pycharm 2021.2 第三方模块 requests: pip install requests csv 爬虫案例的步骤 1.确定url地址(链接地址) 2.发送网络请求 3.数据解析(筛选数据) 4.数据的保存(数据库(mysql\mong
-
利用Python网络爬虫爬取各大音乐评论的代码
python爬虫--爬取网易云音乐评论 方1:使用selenium模块,简单粗暴.但是虽然方便但是缺点也是很明显,运行慢等等等. 方2:常规思路:直接去请求服务器 1.简易看出评论是动态加载的,一定是ajax方式. 2.通过网络抓包,可以找出评论请求的的URL 得到请求的URL 3.去查看post请求所上传的数据 显然是经过加密的,现在就需要按着网易的思路去解读加密过程,然后进行模拟加密. 4.首先去查看请求是经过那些js到达服务器的 5.设置断点:依次对所发送的内容进行观察,找到评论对应的UR
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
浅谈Python爬取网页的编码处理
背景 中秋的时候,一个朋友给我发了一封邮件,说他在爬链家的时候,发现网页返回的代码都是乱码,让我帮他参谋参谋(中秋加班,真是敬业= =!),其实这个问题我很早就遇到过,之前在爬小说的时候稍微看了一下,不过没当回事,其实这个问题就是对编码的理解不到位导致的. 问题 很普通的一个爬虫代码,代码是这样的: # ecoding=utf-8 import re import requests import sys reload(sys) sys.setdefaultencoding('utf8') url
-
python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成的效果 爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中.最后中的效果示意图如下: 控制台输入 数据库显示 准备工作 首先需要安装python,这个网上已经有很多的
-
详解python 爬取12306验证码
一个简单的验证码爬取程序 本文介绍了在Python2.7环境下爬取网站验证码: 思路就是获取验证码对应的url,然后发起requst请求,读取该URL对应的内容,然后写入到一个本地文件,实现一个验证码的保存.大量下载可以把以上程序写入一个死循环 代码实现部分: import ssl import urllib2 i=1 import time while(1): #不加的话,无法访问12306 ssl._create_default_https_context = ssl._create_unv
-
Python 爬取携程所有机票的实例代码
打开携程网,查询机票,如广州到成都. 这时网址为:http://flights.ctrip.com/booking/CAN-CTU-day-1.html?DDate1=2018-06-15 其中,CAN 表示广州,CTU 表示成都,日期 "2018-06-15"就比较明显了.一般的爬虫,只有替换这几个值,就可以遍历了.但观察发现,有个链接可以看到当前网页的所有json格式的数据.如下 http://flights.ctrip.com/domesticsearch/search/Sear
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收