使用python批量修改XML文件中图像的depth值
最近刚刚接触深度学习,并尝试学习制作数据集,制作过程中发现了一个问题,现在跟大家分享一下。问题是这样的,在制作voc数据集时,我采集的是灰度图像,并已经用labelimg生成了每张图像对应的XML文件。训练时发现好多目标检测模型使用的训练集是彩色图像,因此特征提取网络的输入是m×m×3的维度的图像。所以我就想着把我采集的灰度图像的深度也改成3吧。批量修改了图像的深度后,发现XML中的depth也要由1改成3才行。如果重新对图像标注一遍生成XML文件的话太麻烦,所以就想用python批量处理一下。果然在网上找到了类似的代码,简单修改一下就可以实现我们想要的功能了。
全部代码如下
#coding:utf-8
import os
import os.path
import xml.dom.minidom
path='E:/data/ann/'#这里修改为自己存放XML文件的路径
files=os.listdir(path) #获取路径下的所有文件的名称
s=[]
for xmlFile in files:
if not os.path.isdir(xmlFile): #判断是否是文件夹,不是文件夹才打开
print(xmlFile)
#将获取到的xml文件名送入到dom解析
dom=xml.dom.minidom.parse(os.path.join(path,xmlFile))
root=dom.documentElement
###获取标签对depth之间的值
depth=root.getElementsByTagName('depth')
#修改相应标签的值
for i in range(len(depth)):
print(depth[i].firstChild.data)
a = depth[i].firstChild.data
print(type(a))
depth[i].firstChild.data=3
print(depth[i].firstChild.data)
#保存修改到xml文件中
with open(os.path.join(path,xmlFile),'w') as fh:
dom.writexml(fh)
print('修改depth成功!')
上面的代码的思路是,读取XML文件,并修改depth节点的内容修改为3,通过循环读取XML文件,实现批量化修改XML文件中depth的值。
修改前后的结果
XML修改前depth的值:
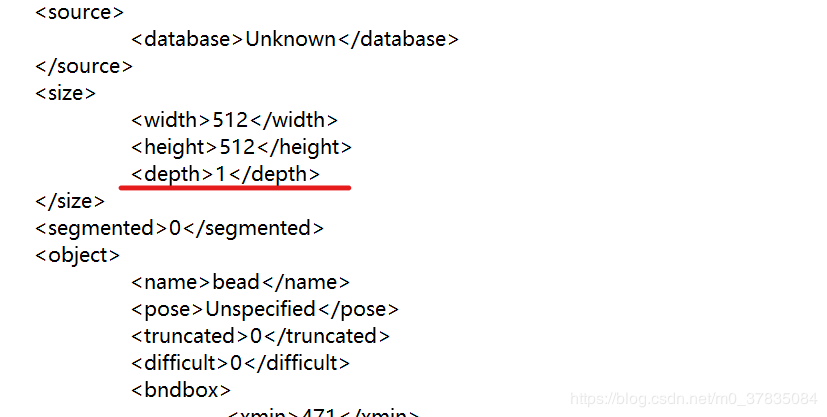
XML修改后depth的值:
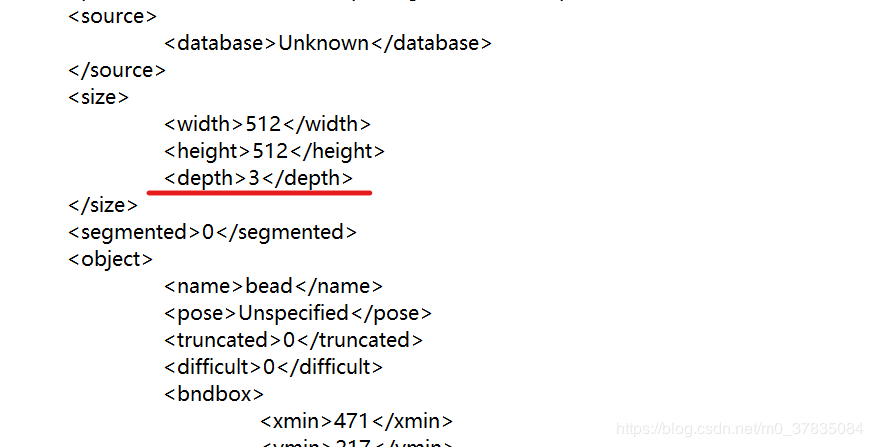
这样,就可以使用自己制作的voc数据集进行训练了。我选的这个方法可能比较傻
到此这篇关于使用python批量修改XML文件中图像的depth值的文章就介绍到这了,更多相关python批量修改XML内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 批量修改 labelImg 生成的xml文件的方法
概述 自己在用labelImg打好标签后,想只用其中几类训练,不想训练全部类别,又不想重新打标生成.xml文件,因此想到这个办法:直接在.xml文件中删除原有的不需要的标签类及其属性. 打标时标签名出现了大小写(工程量大时可能会手滑),程序中有改写标签值为小写的过程,因为我做py-faster-rcnn 训练时,标签必须全部为小写. 以如下的.xml文件为例,我故意把标签增加了大写 <annotation verified="yes"> <filename>te
-
python批量修改xml属性的实现方式
今天来说说xml那些事儿.如何批量修改指定文件夹下的xml文件的指定属性.分三步走,首先,我们先看看如何读写单个 的xml文件;第二步,来看看如何遍历指定文件夹下的所有文件,获取到所有文件的文件名;第三步,我们来看看一二之间 该如何衔接.好,lets do it step1:对单个xml文件进行读写 给定一个xml文件: <?xml version="1.0" encoding="utf-8"?> <catalog> <maxid>
-
使用python批量修改XML文件中图像的depth值
最近刚刚接触深度学习,并尝试学习制作数据集,制作过程中发现了一个问题,现在跟大家分享一下.问题是这样的,在制作voc数据集时,我采集的是灰度图像,并已经用labelimg生成了每张图像对应的XML文件.训练时发现好多目标检测模型使用的训练集是彩色图像,因此特征提取网络的输入是m×m×3的维度的图像.所以我就想着把我采集的灰度图像的深度也改成3吧.批量修改了图像的深度后,发现XML中的depth也要由1改成3才行.如果重新对图像标注一遍生成XML文件的话太麻烦,所以就想用python批量处理一下.
-
python批量修改xml文件中的信息
目录 项目场景: 问题描述: 分析: 解决方案: 总结 项目场景: 在做目标检测时,重新进行标注会耗费大量的时间,如果能够批量对xml中的信息进行修改,那么将会节省大量的时间,接下来将详细介绍如何修改标注文件xml中的相关信息. 问题描述: 例如:当我有一批标注好的xml文件,文件格式如下图所示 : <?xml version='1.0' encoding='us-ascii'?> <annotation> <folder>VOC2012</folder>
-

Python实现批量修改xml文件的脚本
今天分享一个我自己写的实用脚本,主要是将.xml文件进行批量的修改 首先,声明我并不是很了解.xml的相关知识,所以今天主要是以我遇到的问题来做个记录. 想要更多的了解xml,请看最后的资料分享. 效果展示: 因为这些是属于我们项目小组的,我也不清楚是不是有什么不能公开的,我就截取了一小部分,原本是用lambelme来修改的,但由于xml文件似乎读不进去,所以只有手动修改,将water改为blue(重要的是一个一个用记事本打开,手动修改),这时候我的第一生产力产生了,because I am l
-
Python批量修改xml的坐标值全部转为整数的实例代码
发现一个有意思的现象,labelimg打开图片和xml标签时候,看不到标注好的框框,仔细查看了xml文件,没发现什么异常,后面试一下,才发现是不能识别xml里的坐标值有小数点的情况.只能四舍五入都转成整数. 如: <bndbox> <xmin>1404.35</xmin> <ymin>0</ymin> <xmax>1458.56</xmax> <ymax>111.96</ymax> </bnd
-
python实现修改xml文件内容
XML 被设计用来传输和存储数据. HTML 被设计用来显示数据. XML 指可扩展标记语言(eXtensible Markup Language). 可扩展标记语言(英语:Extensible Markup Language,简称:XML)是一种标记语言,是从标准通用标记语言(SGML)中简化修改出来的.它主要用到的有可扩展标记语言.可扩展样式语言(XSL).XBRL和XPath等. 直接上代码,拿来就可用. 首先需要准备一个测试xml文件,我这个文件名字为text.xml:
-
Python批量提取PDF文件中文本的脚本
本文实例为大家分享了Python批量提取PDF文件中文本的具体代码,供大家参考,具体内容如下 首先需要执行命令pip install pdfminer3k来安装处理PDF文件的扩展库. import os import sys import time pdfs = (pdfs for pdfs in os.listdir('.') if pdfs.endswith('.pdf')) for pdf1 in pdfs: pdf = pdf1.replace(' ', '_').replace('-
-
4种方法python批量修改替换列表中元素
在日常开发中,我们可能会遇到批量修改列表元素的需求.可以使用列表推导式来快速的实现,在这里做了一些技术总结可供参考. 一,修改单个词语(不建议): aaa=['黑色','红色','白色','黑色'] aaa=str(aaa) bbb=aaa.replace("黑色","黄色") bbb 结果: "['黄色', '红色', '白色', '黄色']" 二,修改单个词语 lists = ['神奇', '建投', '证券', '有限公司', '今天',
-
python:批量统计xml中各类目标的数量案例
之前写了一个matlab的,越用越觉得麻烦,如果不同数据集要改类别数目,而且运行速度慢.所以重新写了一个Python的,直接读取xml文件夹路径就可以,不用预先知道类别,直接能够检测出所有类别的目标名称及其对应的数量. 分享出来给大家. 代码如下: # -*- coding:utf-8 -*- import os import xml.etree.ElementTree as ET import numpy as np np.set_printoptions(suppress=True, thr