基于python + django + whoosh + jieba 分词器实现站内检索功能
基于 python django
前期准备
安装库:
pip install django-haystack pip install whoosh pip install jieba
如果pip 安装超时,可配置pip国内源下载,如下:
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com <安装的库>
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com django
如果安装 django-haystack 失败,先安装 setuptools_scm .在安装 django-haystack.
pip install setuptools_scm
项目
创建项目demo:
# django-admin startproject <项目名> django-admin startproject find
切入demo 终端操作,创建app:
# python manage.py startapp <APP名> python manage.py startapp searchshop
在 settings.py 文件 中的 INSTALLED_APPS 配置 注入 刚才创建APP( 路径: find/find/settings.py):
INSTALLED_APPS = [ ... 'searchshop', ... ]
在创建的APP中添加模型
models.py 文件添加如下(路径: find/searchshop/models.py):
class Shopp(models.Model):
shop_name = models.TextField(max_length=200)
shop_price = models.IntegerField(default=0)
shop_dsc = models.CharField(max_length=200)
在app 中admin.py文件注册模型:
admin.py 文件添加如下(路径: find/searchshop/admin.py):
from .models import Shopp admin.site.register(Shopp)
执行命令,让模型生效(修改模型时,都要执行一次,这样模型才同步!!!):
python manage.py makemigrations python manage.py migrate
创建后台管理帐号
访问后台可操作模型数据:
python manage.py createsuperuser
运行:
python manage.py runserver
访问: http:127.0.0.1:8080/admin 登录刚才设置帐号,密码即可进入:
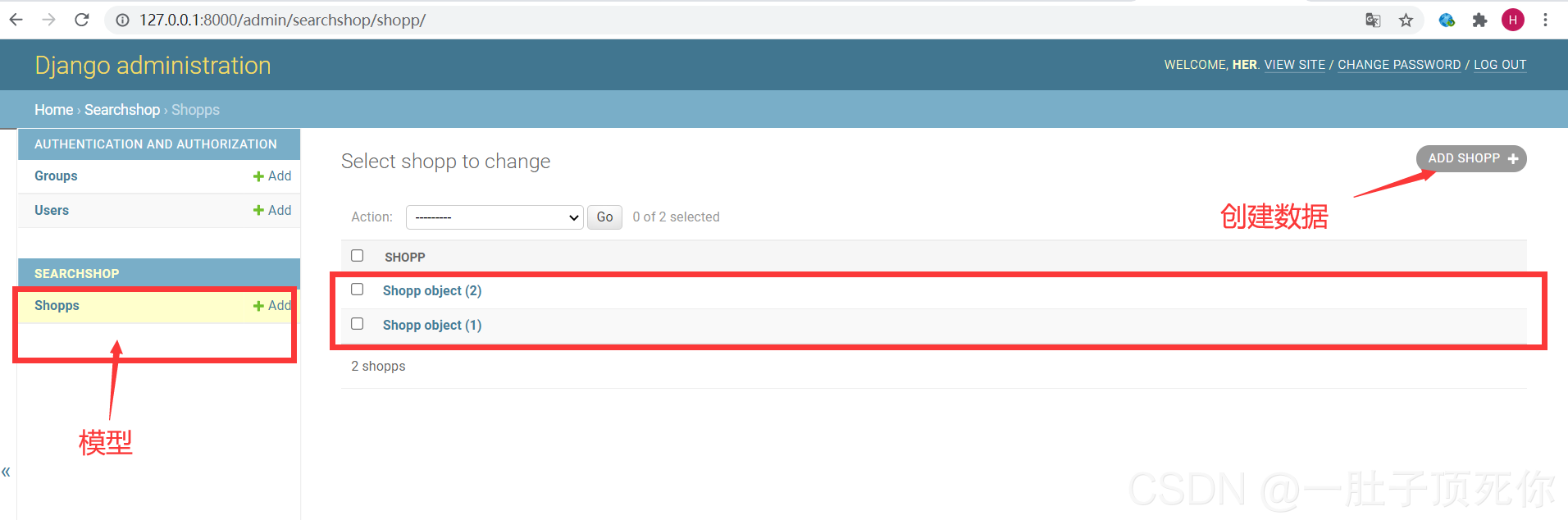
搭建站内搜索
配置 haystack
在 settings.py 文件 中的 INSTALLED_APPS 配置最底部 注入 haystack( 路径: find/find/settings.py):
INSTALLED_APPS = [ ... 'haystack' ]
在app内,添加 search_indexes.py (目录:find/searchshop/search_indexes.py):
from haystack import indexes
from .models import Shopp # 之前创建的模型
# 修改此处,类名为模型类的名称+Index,比如模型类为GoodsInfo,则这里类名为GoodsInfoIndex(其实可以随便写)
class ArticlePostIndex(indexes.SearchIndex, indexes.Indexable):
# text为索引字段
# document = True,这代表haystack和搜索引擎将使用此字段的内容作为索引进行检索
# use_template=True 指定根据表中的那些字段建立索引文件的说明放在一个文件中
text = indexes.CharField(document=True, use_template=True)
# 对那张表进行查询
def get_model(self): # 重载get_model方法,必须要有!
# 返回这个model
return Shopp
# 建立索引的数据
def index_queryset(self, using=None):
# 这个方法返回什么内容,最终就会对那些方法建立索引,这里是对所有字段建立索引
return self.get_model().objects.all()
生成检索索引
python manage.py rebuild_index
项目目录多出whoosh_index文件夹.
修改分词器
从 pyrhon 安装路径 ( \Lib\site-packages\haystack\backends\whoosh_backend.py) 复制一份到app中改名为 whoosh_cn_backend (find/searchshop/whoosh_cn_backend.py)
在顶部引用:
from jieba.analyse import ChineseAnalyzer
找到 (查找 StemmingAnalyzer ) 位置:
schema_fields[field_class.index_fieldname] = TEXT(
stored=True,
analyzer=StemmingAnalyzer(),
field_boost=field_class.boost,
sortable=True,
)
替换:
schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=ChineseAnalyzer(),
field_boost=field_class.boost)
在 INSTALLED_APPS(路径: find/find/settings.py) 配置后面 后面添加:
HAYSTACK_CONNECTIONS = {
'default': {
# 指定whoosh引擎 (之前创建的whoosh_cn_backend)
'ENGINE': 'searchshop.whoosh_cn_backend.WhooshEngine',
# 'ENGINE': 'jsapp.whoosh_cn_backend.WhooshEngine', # whoosh_cn_backend是haystack的whoosh_backend.py改名的文件为了使用jieba分词
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 添加此项,当数据库改变时,会自动更新索引,非常方便
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
添加 templates
在APP中创建 templates文件夹.
添加内容检索内容
在templates文件夹下创建文件夹 search -> indexes -> searchshop( search + APP名);
路径( 目录: find/searchshop\templates\search\indexes\searchshop) 添加Shopp_text.txt(APP名_text.txt): (需要检索的字段名)
{{object.shop_name}}
{{object.shop_dsc}}
{{object.shop_price}}
添加页面模板
在templates文件夹下创建文件夹(searchshop) 下创建index.html:
{% load highlight %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>商品列表</title>
<style>
span.highlighted {
color: red;
}
</style>
</head>
<body>
<div class="search">
<form method="get" action="{% url 'shop:search' %}">
<input type="text" name="q" placeholder="a搜索商品">
<input type="submit" value="搜索">
</form>
</div>
{% if shop_list and query %}
<ul>
{% for question in shop_list %}
<li>
{% highlight question.object.shop_name with query %}
价格: {% highlight question.object.shop_price with query %}
<span class="post-author"> <a> {% highlight question.object.shop_dsc with query %} </a></span>
</li>
{% endfor %}
</ul>
{% else %}
<p>No polls are available.</p>
{% endif %}
</body>
</html>
load highlight : 加载高亮.
query : 检索词
shop_list : 检索结果
视图层
目录: find/searchshop/views.py
from django.shortcuts import render
from django.http import HttpResponse
#Create your views here.
from .models import Shopp
from haystack.forms import ModelSearchForm
from haystack.query import EmptySearchQuerySet
def index(request):
shop_list = Shopp.objects.all()
context = {
'query': '',
'shop_list': shop_list
}
return render(request, 'searchshop/index.html', context)
def search(request, load_all=True, form_class=ModelSearchForm, searchqueryset=None):
if request.GET.get('q'):
form = form_class(request.GET, searchqueryset=searchqueryset, load_all=load_all)
if form.is_valid():
query = form.cleaned_data['q']
results = form.search()
context = {
'query': query,
'shop_list': results
}
return render(request, 'searchshop/index.html', context)
# results = form.search()
return HttpResponse(request.GET.get('q'))
return HttpResponse('查询')
配置路由
在 find/searchshop 创建 urls.py
from . import views
app_name = 'shop' # 重点是这一行
urlpatterns = [
path('', views.index, name='index'),
path('search', views.search, name='search'),
# path(r'search/$', views.search, name='search')
]
修改 urls.py(目录: find/find/urls.py)
from django.urls import path, include
urlpatterns = [
path('shop', include('searchshop.urls')),
path('admin/', admin.site.urls),
]
运行:
python manage.py runserver
测试
http://127.0.0.1:8000/shop


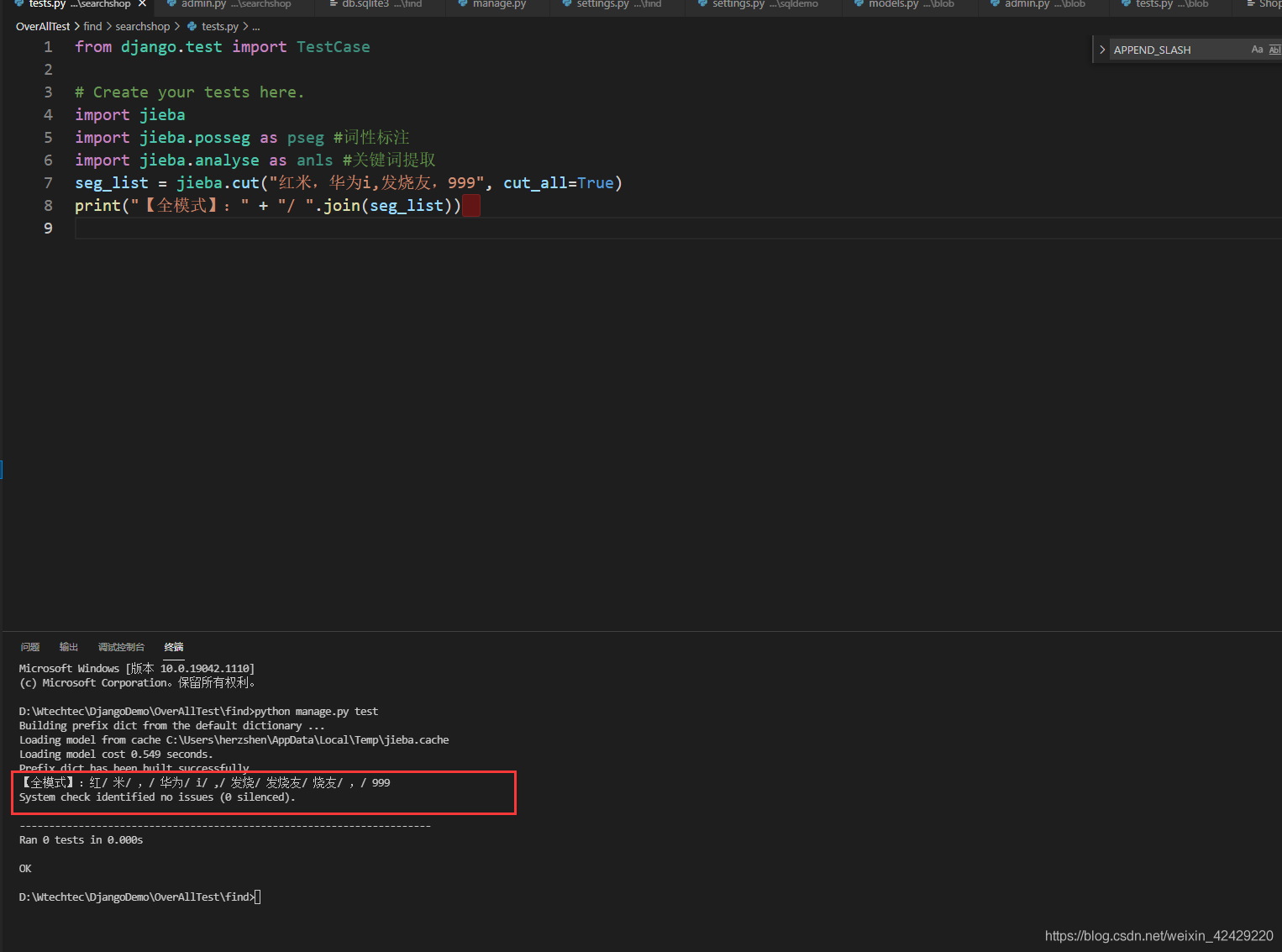
分词器
所以'红米'查询不到…
到此这篇关于基于python + django + whoosh + jieba 分词器实现站内检索的文章就介绍到这了,更多相关python django 分词器实现站内检索内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python检索特定内容的文本文件实例
windows环境下python2.7 脚本指定一个参数作为要检索的字符串 例如: >find.py ./ hello # coding=utf-8 import os import sys # 找到当前目录下的所有文本文件 def findFile(path): f = [] d = [] l = os.listdir(path) for x in l: if os.path.isfile(os.path.join(os.getcwd() + "\\", x)): f.appe
-
Python中使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索需要进行中文分词,使用jieba. 直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立.搜索解析等细节问题. haystack支持多种搜索引擎,不仅仅是whoosh,使用solr.elas
-
Python基于正则表达式实现检查文件内容的方法【文件检索】
本文实例讲述了Python基于正则表达式实现检查文件内容的方法分享给大家供大家参考,具体如下: 这个是之前就在学python,欣赏python的小巧但是功能强大,是连电池都自带的语言.平时工作中用Java ,觉得python在日常生活中比java用处要大,首先语法没那么复杂,特别是io的操作,java里要写一大坨没关的代码.还有就是不用编译,而且linux系统默认都会自带. 这次遇到的问题是工作当中想要迁移一个系统中的一个模块,这个时候需要评估模块里的代码有没有对其他代码强依赖,就是有没有imp
-

python django使用haystack:全文检索的框架(实例讲解)
haystack:全文检索的框架 whoosh:纯Python编写的全文搜索引擎 jieba:一款免费的中文分词包 首先安装这三个包 pip install django-haystack pip install whoosh pip install jieba 1.修改settings.py文件,安装应用haystack, 2.在settings.py文件中配置搜索引擎 HAYSTACK_CONNECTIONS = { 'default': { # 使用whoosh引擎 'ENGINE': '
-
python实现图像检索的三种(直方图/OpenCV/哈希法)
简介: 本文介绍了图像检索的三种实现方式,均用python完成,其中前两种基于直方图比较,哈希法基于像素分布. 检索方式是:提前导入图片库作为检索范围,给出待检索的图片,将其与图片库中的图片进行比较,得出所有相似度后进行排序,从而检索结果为相似度由高到低的图片.由于工程中还包含Qt界面类.触发函数等其他部分,在该文档中只给出关键函数的代码. 开发系统:MacOS 实现方式:Qt + Python 方法一:自定义的直方图比较算法 a) 基本思路 遍历图片像素点,提取R\G\B值并进行对应的计数,得
-
基于python + django + whoosh + jieba 分词器实现站内检索功能
基于 python django 源码 前期准备 安装库: pip install django-haystack pip install whoosh pip install jieba 如果pip 安装超时,可配置pip国内源下载,如下: pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com <安装的库> pip install -i http://mirrors.al
-
基于Python制作一个相册播放器
大家好,我是小F. 对于相册播放器,大家应该都不陌生(用于浏览多张图片的一个应用). 当然还有视频.音乐播放器,同样是用来播放多个视频.音乐文件的. 在Win10系统下,用[照片]这个应用打开一张图片,就可以浏览该图片所在文件夹中其它图片了. 从上面的图中发现,还有不少其它方面的功能,比如图片裁剪.编辑.打印等. 今天小F就带大家学习一个Python制作相册播放器的实战项目. 功能嘛,当然没有系统自带的好,仅做学习哈. 默认5秒切换一张图片,点击向前按钮,可以快速切换到下一张图片. 主要使用到P
-
基于Python实现本地音乐播放器的制作
制作这个播放器的目的是为了将下载下来的mp3文件进行随机或是顺序的播放.选择需要播放的音乐的路径,选择播放方式,经过测试可以完美的播放本地音乐. 在开始之前介绍一个免费下载mp3音乐的网站,有需要的可以下载自己喜欢的音乐.当然有各大音乐平台会员的大佬就不需要了. 缺少音乐素材的可以去免费下载即可,准备好音乐素材后将其放到一个文件夹下面即可. 在应用实现过程中,总共使用了下面这些库,特别需要注意的是这个库playsound使用的版本是1.3.0,听说其他版本在播放音乐时可能存在问题.也可以将播放音
-
基于Python实现体育彩票选号器功能代码实例
一,概要 需求: 实现一个GUI界面下的 6+1体育彩票选号器. (1) 要求界面可以加载系统时间及开奖时间 (2) 功能区完成人选及机选的功能 人选 --> 手动输入6+1位数字.前6位必须在0-9之间的数字.后1位必须是0-4之间的数字 机选 --> (1) 填写数量(加校验必须为数字且不能为空)点击开始按钮后把选举的数字添加到展示界面中 (2) 允许选举的数字重复及不重复两种选择 (3) 展示区的设置,显示已选的彩票号码 (4) 完成清空展示区内容功能 (5) 完成关闭整个界面窗口功能
-
Python+Django+MySQL实现基于Web版的增删改查的示例代码
前言 本篇使用Python Web框架Django连接和操作MySQL数据库学生信息管理系统(SMS),主要包含对学生信息增删改查功能,旨在快速入门Python Web,少走弯路.效果演示在项目实战最后一节,文章结尾有整个项目的源码地址. 开发环境 开发工具:Pycharm 2020.1 开发语言:Python 3.8.0 Web框架:Django 3.0.6 数据库:MySQL5.7 操作系统:Windows 10 项目实战 1. 创建项目 File->New Project->Django
-
如何Docker化Python Django应用程序
Docker是一个开源项目,为开发人员和系统管理员提供了一个开放平台,可以将应用程序构建.打包为一个轻量级容器,并在任何地方运行.Docker 会在软件容器中自动部署应用程序. Django 是一个用 Python 编写的 Web 应用程序框架,遵循 MVC(模型-视图-控制器)架构.它是免费的,并在开源许可下发布.它速度很快,旨在帮助开发人员尽快将他们的应用程序上线. 在本教程中,我将逐步向你展示在 Ubuntu 16.04 中如何为现有的 Django 应用程序创建 docker 镜像.我们
-
Django实现whoosh搜索引擎使用jieba分词
本文介绍了Django实现whoosh搜索引擎使用jieba分词,分享给大家,具体如下: Django版本:3.0.4 python包准备: pip install django-haystack pip install jieba 使用jieba分词 1.cd到site-packages内的haystack包,创建并编辑ChineseAnalyzer.py文件 # (注意:pip安装的是django-haystack,但是实际包的文件夹名字为haystack) cd /usr/local/li
-
Python基于jieba分词实现snownlp情感分析
情感分析(sentiment analysis)是2018年公布的计算机科学技术名词. 它可以根据文本内容判断出所代表的含义是积极的还是负面的,也可以用来分析文本中的意思是褒义还是贬义. 一般应用场景就是能用来做电商的大量评论数据的分析,比如好评率或者差评率的统计等等. 我们这里使用到的情感分析的模块是snownlp,为了提高情感分析的准确度选择加入了jieba模块的分词处理. 由于以上的两个python模块都是非标准库,因此我们可以使用pip的方式进行安装. pip install jieba
-
Python中文分词库jieba(结巴分词)详细使用介绍
一,jieba的介绍 jieba 是目前表现较为不错的 Python 中文分词组件,它主要有以下特性: 支持四种分词模式: 精确模式 全模式 搜索引擎模式 paddle模式 支持繁体分词 支持自定义词典 MIT 授权协议 二,安装和使用 1,安装 pip3 install jieba 2,使用 import jieba 三,主要分词功能 1,jieba.cut 和jieba.lcut lcut 将返回的对象转化为list对象返回 传入参数解析: def cut(self, sentence, c
-
浅谈python jieba分词模块的基本用法
jieba(结巴)是一个强大的分词库,完美支持中文分词,本文对其基本用法做一个简要总结. 特点 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析: 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义: 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词. 支持繁体分词 支持自定义词典 MIT 授权协议 安装jieba pip install jieba 简单用法 结巴分词分为三种模式:精确模式(默认).全模式和搜索引擎