python beautiful soup库入门安装教程
目录
- beautiful soup库的安装
- beautiful soup库的理解
- beautiful soup库的引用
- BeautifulSoup类
- 回顾demo.html
- Tag标签
- Tag的attrs(属性)
- Tag的NavigableString
- HTML基本格式
- 标签树的下行遍历
- 标签树的上行遍历
- 标签的平行遍历
- bs库的prettify()方法
- bs4库的编码
beautiful soup库的安装
pip install beautifulsoup4
beautiful soup库的理解
beautiful soup库是解析、遍历、维护“标签树”的功能库
beautiful soup库的引用
from bs4 import BeautifulSoup import bs4
BeautifulSoup类
BeautifulSoup对应一个HTML/XML文档的全部内容
回顾demo.html
import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
print(demo)
<html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p> </body></html>
Tag标签
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.title)
tag = soup.a
print(tag)
<title>This is a python demo page</title> <a href="http://www.icourse163.org/course/BIT-268001" >Basic Python</a>
任何存在于HTML语法中的标签都可以用soup.访问获得。当HTML文档中存在多个相同对应内容时,soup.返回第一个
Tag的name
| 基本元素 | 说明 |
|---|---|
| Name | 标签的名字,
… 的名字是'p',格式:.name |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.name)
print(soup.a.parent.name)
print(soup.a.parent.parent.name)
a p body
Tag的attrs(属性)
| 基本元素 | 说明 |
|---|---|
| Attributes | 标签的属性,字典形式组织,格式:.attrs |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
tag = soup.a
print(tag.attrs)
print(tag.attrs['class'])
print(tag.attrs['href'])
print(type(tag.attrs))
print(type(tag))
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
['py1']
http://www.icourse163.org/course/BIT-268001
<class 'dict'>
<class 'bs4.element.Tag'>
Tag的NavigableString
Tag的NavigableString
| 基本元素 | 说明 |
|---|---|
| NavigableString | 标签内非属性字符串,<>…</>中字符串,格式:.string |
Tag的Comment
| 基本元素 | 说明 |
|---|---|
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
import requests
from bs4 import BeautifulSoup
newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>","html.parser")
print(newsoup.b.string)
print(type(newsoup.b.string))
print(newsoup.p.string)
print(type(newsoup.p.string))
This is a comment <class 'bs4.element.Comment'> This is not a comment <class 'bs4.element.NavigableString'>
HTML基本格式
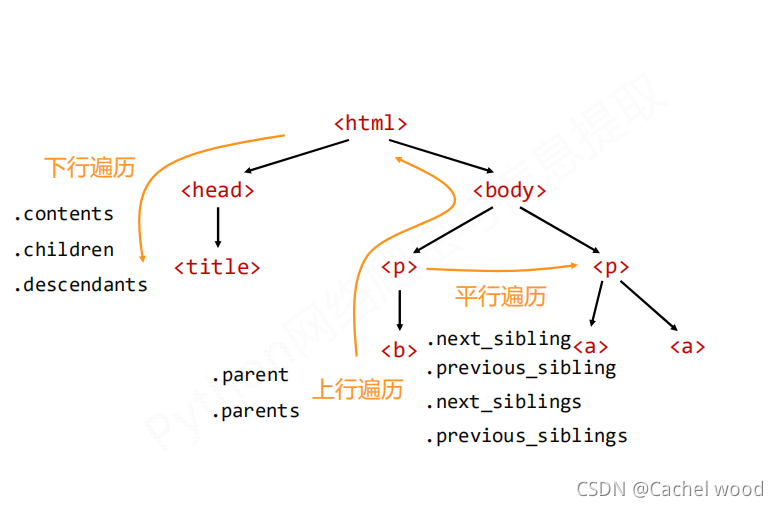
标签树的下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将所有儿子结点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子结点 |
| .descendents | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
BeautifulSoup类型是标签树的根节点
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.head)
print(soup.head.contents)
print(soup.body.contents)
print(len(soup.body.contents))
print(soup.body.contents[1])
<head><title>This is a python demo page</title></head> [<title>This is a python demo page</title>] ['\n', <p ><b>The demo python introduces several python courses.</b></p>, '\n', <p >Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" >Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" >Advanced Python</a>.</p>, '\n'] 5 <p ><b>The demo python introduces several python courses.</b></p>
for child in soup.body.children: print(child) #遍历儿子结点 for child in soup.body.descendants: print(child) #遍历子孙节点
标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.title.parent)
print(soup.html.parent)
<head><title>This is a python demo page</title></head> <html><head><title>This is a python demo page</title></head> <body> <p ><b>The demo python introduces several python courses.</b></p> <p >Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" >Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" >Advanced Python</a>.</p> </body></html>
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p body html [document]
标签的平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous.sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous.siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
print(soup.a.previous_sibling.previous_sibling)
print(soup.a.parent)
and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: None <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
for sibling in soup.a.next_sibling: print(sibling) #遍历后续节点 for sibling in soup.a.previous_sibling: print(sibling) #遍历前续节点
bs库的prettify()方法
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.prettify())
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
.prettify()为HTML文本<>及其内容增加更加'\n'
.prettify()可用于标签,方法:.prettify()
bs4库的编码
bs4库将任何HTML输入都变成utf-8编码
python 3.x默认支持编码是utf-8,解析无障碍
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>中文</p>","html.parser")
print(soup.p.string)
print(soup.p.prettify())
中文 <p> 中文 </p>
到此这篇关于python beautiful soup库入门安装教程的文章就介绍到这了,更多相关python beautiful soup库入门内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python中使用Beautiful Soup库的超详细教程
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码.你不需要考虑编码方式,除非文档没有指
-
Python爬虫库BeautifulSoup获取对象(标签)名,属性,内容,注释
一.Tag(标签)对象 1.Tag对象与XML或HTML原生文档中的tag相同. from bs4 import BeautifulSoup soup = BeautifulSoup('<b class="boldest">Extremely bold</b>','lxml') tag = soup.b type(tag) bs4.element.Tag 2.Tag的Name属性 每个tag都有自己的名字,通过.name来获取 tag.name 'b' tag.
-
使用python BeautifulSoup库抓取58手机维修信息
直接上代码: 复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*- import urllib import os,datetime,string import sys from bs4 import BeautifulSoup reload(sys) sys.setdefaultencoding('utf-8') __BASEURL__ = 'http://bj.58.com/' __INITURL__ = "http://bj.58.com/
-
python用BeautifulSoup库简单爬虫实例分析
会用到的功能的简单介绍 1.from bs4 import BeautifulSoup #导入库 2.请求头herders headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36','referer':"www.mmjpg.com" } all_url = 'http://ww
-
python3解析库BeautifulSoup4的安装配置与基本用法
前言 Beautiful Soup是python的一个HTML或XML的解析库,我们可以用它来方便的从网页中提取数据,它拥有强大的API和多样的解析方式. Beautiful Soup的三个特点: Beautiful Soup提供一些简单的方法和python式函数,用于浏览,搜索和修改解析树,它是一个工具箱,通过解析文档为用户提供需要抓取的数据 Beautiful Soup自动将转入稳定转换为Unicode编码,输出文档转换为UTF-8编码,不需要考虑编码,除非文档没有指定编码方式,这时只需要指
-
使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解
下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最基础的内容 html_doc = """ <html><head><title>The Dormouse's story</title></head> <p class="title"><b>The Dormouse's story</b></p>
-
Python使用BeautifulSoup库解析HTML基本使用教程
BeautifulSoup是Python的一个第三方库,可用于帮助解析html/XML等内容,以抓取特定的网页信息.目前最新的是v4版本,这里主要总结一下我使用的v3版本解析html的一些常用方法. 准备 1.Beautiful Soup安装 为了能够对页面中的内容进行解析,本文使用Beautiful Soup.当然,本文的例子需求较简单,完全可以使用分析字符串的方式. 执行 sudo easy_install beautifulsoup4 即可安装. 2.requests模块的安装 reque
-
python3第三方爬虫库BeautifulSoup4安装教程
Python3安装第三方爬虫库BeautifulSoup4,供大家参考,具体内容如下 在做Python3爬虫练习时,从网上找到了一段代码如下: #使用第三方库BeautifulSoup,用于从html或xml中提取数据 from bs4 import BeautifulSoup 自己实践后,发现出现了错误,如下所示: 以上错误提示是说没有发现名为"bs4"的模块.即"bs4"模块未安装. 进入Python安装目录,以作者IDE为例, 控制台提示第三
-
python beautiful soup库入门安装教程
目录 beautiful soup库的安装 beautiful soup库的理解 beautiful soup库的引用 BeautifulSoup类 回顾demo.html Tag标签 Tag的attrs(属性) Tag的NavigableString HTML基本格式 标签树的下行遍历 标签树的上行遍历 标签的平行遍历 bs库的prettify()方法 bs4库的编码 beautiful soup库的安装 pip install beautifulsoup4 beautiful soup库的理
-
Python爬虫进阶之Beautiful Soup库详解
一.Beautiful Soup库简介 BeautifulSoup4 是一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的数据.和 lxml 库一样. lxml 只会局部遍历,而 BeautifulSoup4 是基于 HTML DOM 的,会加载整个文档,解析 整个 DOM 树,因此内存开销比较大,性能比较低. BeautifulSoup4 用来解析 HTML 比较简单,API 使用非常人性化,支持 CSS 选择器,是 Python 标准库中的 HTML 解析器,也支
-
Python 页面解析Beautiful Soup库的使用方法
目录 1.Beautiful Soup库简介 2.Beautiful Soup库方法介绍 2.1 find_all() 2.2 find() 2.3 select() 3.代码实例 1.Beautiful Soup库简介 Beautiful Soup 简称 BS4(其中 4 表示版本号)是一个 Python 中常用的页面解析库,它可以从 HTML 或 XML 文档中快速地提取指定的数据. 相比于之前讲过的 lxml 库,Beautiful Soup 更加简单易用,不像正则和 XPath 需要刻意
-
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
音频处理 windows10下python三方库librosa安装教程
librosa是处理音频库里的opencv,使用python脚本研究音频,先安装三方库librosa. 如下通过清华镜像源安装librosa: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple librosa D:\D00_Python3\D00A2_python3.7.3\install>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple librosa Looking
-
python开发之Docker入门安装部署教程
一.安装Docker 安装环境: 系统:CentOS Linux7 x86_64 安装脚本 wget -qO- https://get.docker.com/ | sh 回车后系统就开始安装docker 安装完成后可以通过以下脚本查看安装结果 docker --version 通过上面的脚本可以查看当前docker的版本,若出现版本信息则说明安装成功 docker system info 执行上面脚本如果出现"Cannot connect to the Docker daemon at"
-
Python和Anaconda和Pycharm安装教程图文详解
Anaconda 是一个基于 Python 的数据处理和科学计算平台,它已经内置了许多非常有用的第三方库,装上Anaconda,就相当于把 Python 和一些如 Numpy.Pandas.Scrip.Matplotlib 等常用的库自动安装好了,使得安装比常规 Python 安装要容易.如果选择安装Python的话,那么还需要 pip install 一个一个安装各种库,安装起来比较痛苦,还需要考虑兼容性,非如此的话,就要去Python官网(https://www.python.org/dow
-
python深度学习tensorflow入门基础教程示例
目录 正文 1.编辑器 2.常量 3.变量 4.占位符 5.图(graph) 例子1:hello world 例子2:加法和乘法 例子3: 矩阵乘法 正文 TensorFlow用张量这种数据结构来表示所有的数据. 用一阶张量来表示向量,如:v = [1.2, 2.3, 3.5] ,如二阶张量表示矩阵,如:m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]],可以看成是方括号嵌套的层数. 1.编辑器 编写tensorflow代码,实际上就是编写py文件,最好找一个好用的编辑器
-
Win10下python 2.7与python 3.7双环境安装教程图解
Win10下python 2.7与python 3.7双环境安装教程,具体内容如下所示: 1.python软件下载网址: https://www.python.org/downloads/windows/ 2. 安装python2.7.16 第一步双击安装包,选择你要安装的路径 第二步默认next,这里不能配置环境变量,只能安装好后手动配. 点击finish安装完成.这样python2和python3都已经安装好了. 3.安装python3.7.4 建议不要安装在系统盘,可以安装在D盘,建一个P
-
详解python中docx库的安装过程
python中docx库的简介 python-docx包,这是一个很强大的包,可以用来创建docx文档,包含段落.分页符.表格.图片.标题.样式等几乎所有的word文档中能常用的功能都包含了,这个包的主要功能便是用来创建文档,相对来说用来修改功能不是很强大.一般情况下在Anaconda中不自带,需另行下载. 导入docx的方法 我的实现方法是通过pip工具在线下载:首先打开cmd命令窗口,然后输入pip install python-docx,然后回车静等.最后命令行中出现Successfull