MySQL内部临时表的具体使用
目录
- UNION
- 表初始化
- 执行语句
- UNION RESULT
- UNION ALL
- GROUP BY
- 内存充足
- 执行语句
- 执行过程
- 排序过程
- ORDER BY NULL
- 内存不足
- 执行语句
- 优化方案
- 优化索引
- 直接排序
- 执行过程
- 对比DISTINCT
- 小结
- 参考资料
UNION
UNION语义:取两个子查询结果的并集,重复的行只保留一行
表初始化
CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a));
DELIMITER ;;
CREATE PROCEDURE idata()
BEGIN
DECLARE i INT;
SET i=1;
WHILE (i<= 1000) DO
INSERT INTO t1 VALUES (i,i,i);
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
CALL idata();
执行语句
(SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2); mysql> EXPLAIN (SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2); +----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+ | 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used | | 2 | UNION | t1 | NULL | index | NULL | PRIMARY | 4 | NULL | 2 | 100.00 | Backward index scan; Using index | | NULL | UNION RESULT | <union1,2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary | +----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
第二行的Key=PRIMARY,Using temporary
- 表示在对子查询的结果做
UNION RESULT的时候,使用了临时表
UNION RESULT
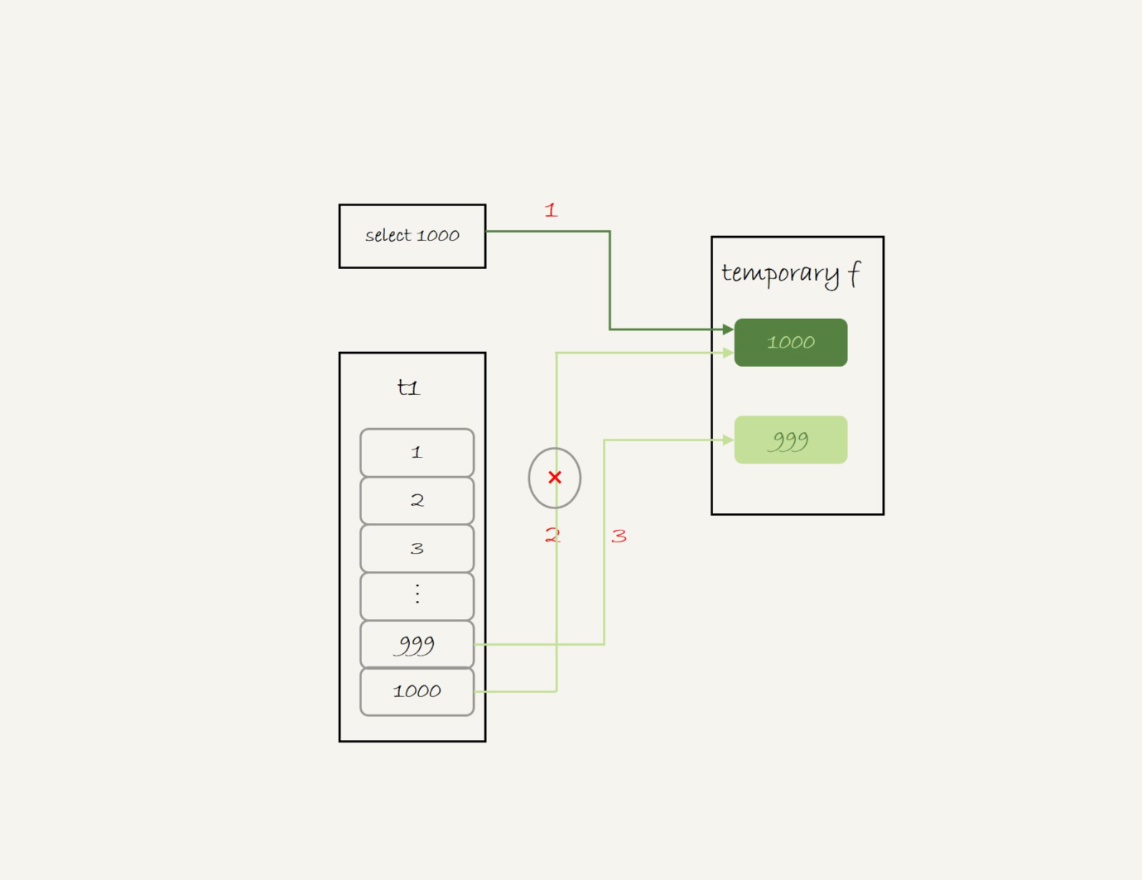
- 创建一个内存临时表,这个内存临时表只有一个整型字段f,并且f为主键
- 执行第一个子查询,得到1000,并存入内存临时表中
- 执行第二个子查询
- 拿到第一行id=1000,试图插入到内存临时表,但由于1000这个值已经存在于内存临时表
- 违反唯一性约束,插入失败,继续执行
- 拿到第二行id=999,插入内存临时表成功
- 拿到第一行id=1000,试图插入到内存临时表,但由于1000这个值已经存在于内存临时表
- 从内存临时表中按行取出数据,返回结果,并删除内存临时表,结果中包含id=1000和id=999两行
- 内存临时表起到了暂存数据的作用,还用到了内存临时表主键id的唯一性约束,实现UNION的语义
UNION ALL
UNION ALL没有去重的语义,一次执行子查询,得到的结果直接发给客户端,不需要内存临时表
mysql> EXPLAIN (SELECT 1000 AS f) UNION ALL (SELECT id FROM t1 ORDER BY id DESC LIMIT 2); +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+ | 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used | | 2 | UNION | t1 | NULL | index | NULL | PRIMARY | 4 | NULL | 2 | 100.00 | Backward index scan; Using index | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
GROUP BY
内存充足
-- 16777216 Bytes = 16 MB mysql> SHOW VARIABLES like '%tmp_table_size%'; +----------------+----------+ | Variable_name | Value | +----------------+----------+ | tmp_table_size | 16777216 | +----------------+----------+
执行语句
-- MySQL 5.6上执行 mysql> EXPLAIN SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m; +----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------+ | 1 | SIMPLE | t1 | index | PRIMARY,a | a | 5 | NULL | 1000 | Using index; Using temporary; Using filesort | +----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------+ mysql> SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m; +------+-----+ | m | c | +------+-----+ | 0 | 100 | | 1 | 100 | | 2 | 100 | | 3 | 100 | | 4 | 100 | | 5 | 100 | | 6 | 100 | | 7 | 100 | | 8 | 100 | | 9 | 100 | +------+-----+
Using index:表示使用了覆盖索引,选择了索引a,不需要回表
Using temporary:表示使用了临时表
Using filesort:表示需要排序
执行过程

- 创建内存临时表,表里有两个字段m和c,m为主键
- 扫描t1的索引a,依次取出叶子节点上的id值,计算id%10,记为x
- 如果内存临时表中没有主键为x的行,插入一行记录
(x,1) - 如果内存临时表中有主键为x的行,将x这一行的c值加1
- 如果内存临时表中没有主键为x的行,插入一行记录
- 遍历完成后,再根据字段m做排序,得到结果集返回给客户端
排序过程
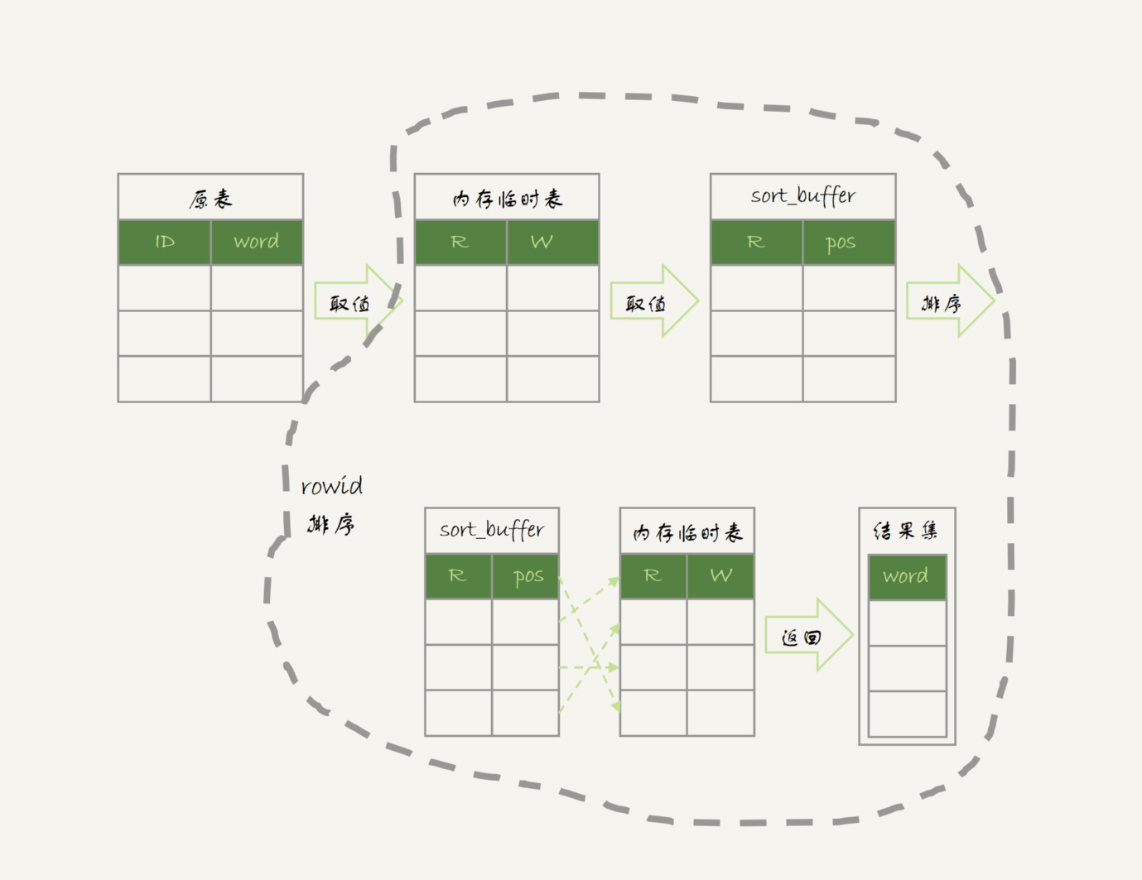
ORDER BY NULL
-- 跳过最后的排序阶段,直接从临时表中取回数据 mysql> EXPLAIN SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m ORDER BY NULL; +----+-------------+-------+-------+---------------+------+---------+------+------+------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+------+------------------------------+ | 1 | SIMPLE | t1 | index | PRIMARY,a | a | 5 | NULL | 1000 | Using index; Using temporary | +----+-------------+-------+-------+---------------+------+---------+------+------+------------------------------+ -- t1中的数据是从1开始的 mysql> SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m ORDER BY NULL; +------+-----+ | m | c | +------+-----+ | 1 | 100 | | 2 | 100 | | 3 | 100 | | 4 | 100 | | 5 | 100 | | 6 | 100 | | 7 | 100 | | 8 | 100 | | 9 | 100 | | 0 | 100 | +------+-----+
内存不足
SET tmp_table_size=1024;
执行语句
-- 内存临时表的上限为1024 Bytes,但内存临时表不能完全放下100行数据,内存临时表会转成磁盘临时表,默认采用InnoDB引擎 -- 如果t1很大,这个查询需要的磁盘临时表就会占用大量的磁盘空间 mysql> SELECT id%100 AS m, count(*) AS c FROM t1 GROUP BY m ORDER BY NULL LIMIT 10; +------+----+ | m | c | +------+----+ | 1 | 10 | | 2 | 10 | | 3 | 10 | | 4 | 10 | | 5 | 10 | | 6 | 10 | | 7 | 10 | | 8 | 10 | | 9 | 10 | | 10 | 10 | +------+----+
优化方案
优化索引
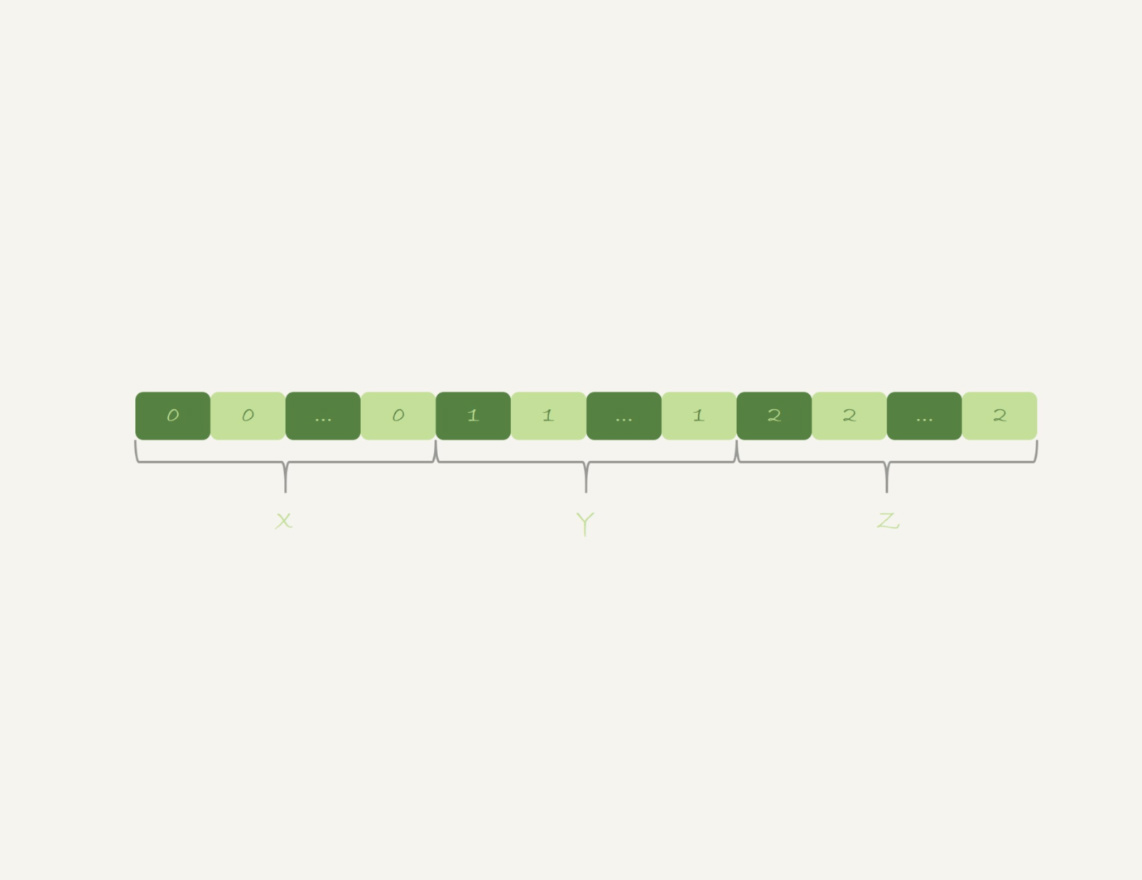
不论使用内存临时表还是磁盘临时表,GROUP BY都需要构造一个带唯一索引的表,执行代价较高
需要临时表的原因:每一行的id%100是无序的,因此需要临时表,来记录并统计结果
如果可以确保输入的数据是有序的,那么计算GROUP BY时,只需要
从左到右顺序扫描,依次累加即可
- 当碰到第一个1的时候,已经累积了X个0,结果集里的第一行为
(0,X) - 当碰到第一个2的时候,已经累积了Y个1,结果集里的第一行为
(1,Y) - 整个过程不需要临时表,也不需要排序
-- MySQL 5.7上执行 ALTER TABLE t1 ADD COLUMN z INT GENERATED ALWAYS AS(id % 100), ADD INDEX(z); -- 使用了覆盖索引,不需要临时表,也不需要排序 mysql> EXPLAIN SELECT z, COUNT(*) AS c FROM t1 GROUP BY z; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | index | z | z | 5 | NULL | 1000 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ 2
直接排序
一个GROUP BY语句需要放到临时表的数据量特别大,还是按照先放在内存临时表,再退化成磁盘临时表
可以直接用磁盘临时表的形式,在GROUP BY语句中SQL_BIG_RESULT(告诉优化器涉及的数据量很大)
磁盘临时表原本采用B+树存储,存储效率还不如数组,优化器看到SQL_BIG_RESULT,会直接用数组存储
- 即放弃使用临时表,直接进入排序阶段
执行过程
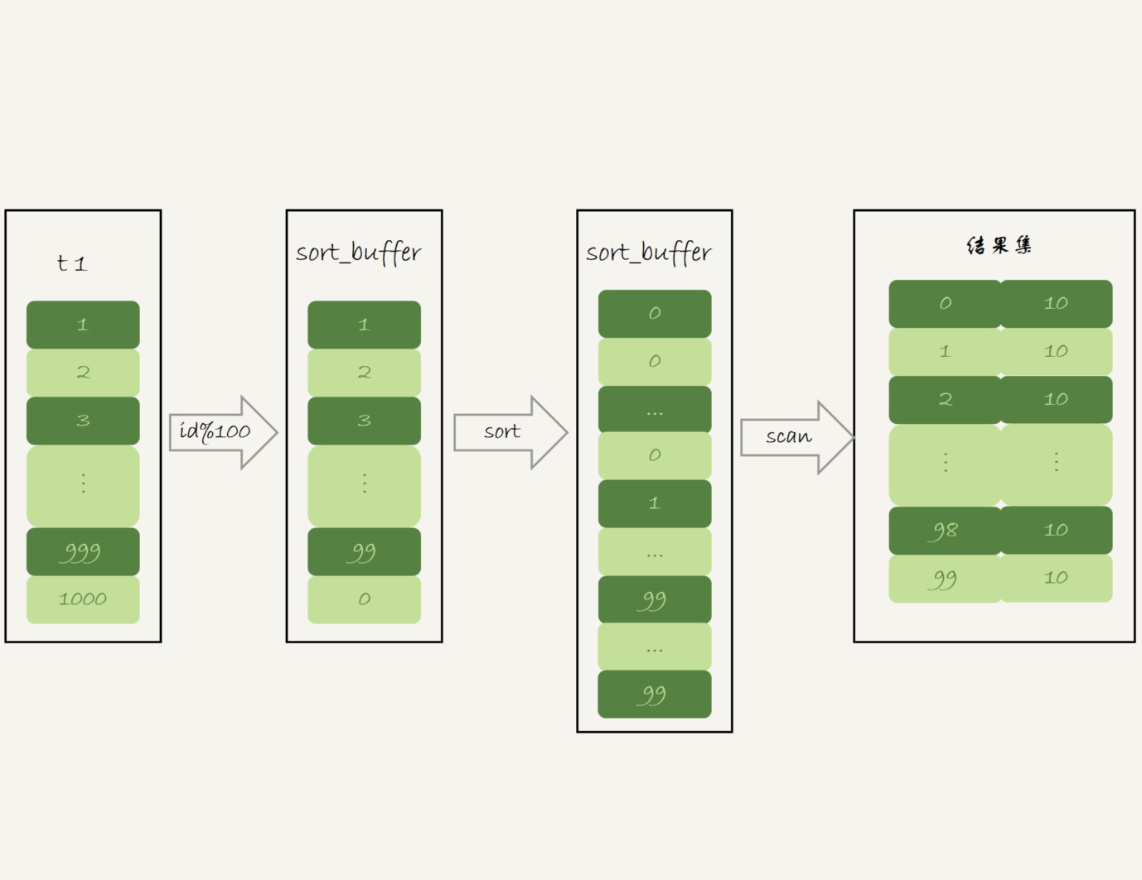
-- 没有再使用临时表,而是直接使用了排序算法 mysql> EXPLAIN SELECT SQL_BIG_RESULT id%100 AS m, COUNT(*) AS c FROM t1 GROUP BY m; +----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------------+ | 1 | SIMPLE | t1 | index | PRIMARY,a | a | 5 | NULL | 1000 | Using index; Using filesort | +----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------------+
初始化sort_buffer,确定放入一个整型字段,记为m
扫描t1的索引a,依次取出里面的id值,将id%100的值放入sort_buffer
扫描完成后,对sort_buffer的字段m做排序(sort_buffer内存不够时,会利用磁盘临时文件辅助排序)
排序完成后,得到一个有序数组,遍历有序数组,得到每个值出现的次数(类似上面优化索引的方式)
对比DISTINCT
-- 标准SQL,SELECT部分添加一个聚合函数COUNT(*) SELECT a,COUNT(*) FROM t GROUP BY a ORDER BY NULL; -- 非标准SQL SELECT a FROM t GROUP BY a ORDER BY NULL; SELECT DISTINCT a FROM t;
标准SQL:按照字段a分组,计算每组a出现的次数
非标准SQL:没有了COUNT(*),不再需要执行计算总数的逻辑
- 按照字段a分组,相同的a的值只返回一行,与
DISTINCT语义一致
如果不需要执行聚合函数 ,DISTINCT和GROUP BY的语义、执行流程和执行性能是相同的
- 创建一个临时表,临时表有一个字段a,并且在这个字段a上创建一个唯一索引
- 遍历表t,依次取出数据插入临时表中
- 如果发现唯一键冲突,就跳过
- 否则插入成功
- 遍历完成后,将临时表作为结果集返回给客户端
小结
- 用到内部临时表的场景
- 如果语句执行过程中可以一边读数据,一边得到结果,是不需要额外内存的
- 否则需要额外内存来保存中间结果
join_buffer是无序数组,sort_buffer是有序数组,临时表是二维表结构- 如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表如果对
GROUP BY语句的结果没有明确的排序要求,加上ORDER BY NULL(MySQL 5.6) - 尽量让
GROUP BY过程用上索引,确认EXPLAIN结果没有Using temporary和Using filesort - 如果
GROUP BY需要统计的数据量不大,尽量使用内存临时表(可以适当调大tmp_table_size) - 如果数据量实在太大,使用
SQL_BIG_RESULT来告诉优化器直接使用排序算法(跳过临时表)
参考资料
《MySQL实战45讲》
到此这篇关于MySQL内部临时表的具体使用的文章就介绍到这了,更多相关MySQL内部临时表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈Mysql在什么情况下会使用内部临时表
union执行 为了便于分析,使用一下sql来进行举例 CREATE TABLE t1 ( id INT PRIMARY KEY, a INT, b INT, INDEX ( a ) ); delimiter ;; CREATE PROCEDURE idata ( ) BEGIN DECLARE i INT; SET i = 1; WHILE ( i <= 1000 ) DO INSERT INTO t1 VALUES ( i, i, i ); SET i = i + 1; END WHILE;
-
MySQL内部临时表的具体使用
目录 UNION 表初始化 执行语句 UNION RESULT UNION ALL GROUP BY 内存充足 执行语句 执行过程 排序过程 ORDER BY NULL 内存不足 执行语句 优化方案 优化索引 直接排序 执行过程 对比DISTINCT 小结 参考资料 UNION UNION语义:取两个子查询结果的并集,重复的行只保留一行 表初始化 CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a)); DELIMITER ;; C
-
MySQL使用临时表加速查询的方法
本文实例讲述了MySQL使用临时表加速查询的方法.分享给大家供大家参考.具体分析如下: 使用MySQL临时表,有时是可以加速查询的,下面就为您详细介绍使用MySQL临时表加速查询的方法. 把表的一个子集进行排序并创建MySQL临时表,有时能加速查询.它有助于避免多重排序操作,而且在其他方面还能简化优化器的工作.例如: 复制代码 代码如下: SELECT cust.name,rcVBles.balance,--other columns SELECT cust.name,rcVBles.bala
-
MySQL中临时表的使用示例
这两天事情稍微有点多,公众号也停止更新了几天,结果有读者催更了,也是,说明还是有人关注,利己及人,挺好. 今天分享的内容是MySQL中的临时表,对于临时表,之前我其实没有过多的研究,只是知道MySQL在某些特定场景下会使用临时表来辅助进行group by等一些列操作,今天就来认识下临时表吧. 1.首先.临时表是session级别的,当前session创建的表,在其他session中看不到. session 1: mysql> create temporary table test3 (id_tm
-
MySQL为什么临时表可以重名
目录 临时表的特性 临时表的应用 为什么临时表可以重名? 临时表和主备复制 主库上不同的线程创建同名的临时表是没关系的,但是传到备库执行是怎么处理的呢? 今天我们就从这个问题说起:临时表有哪些特征,适合哪些场景? 这里,我需要先帮你厘清一个容易误解的问题:有的人可能会认为,临时表就是内存表.但是,这两个概念可是完全不同的. 内存表,指的是使用Memory引擎的表,建表语法是create table …engine=memory.**这种表的数据都保存在内存里,系统重启的时候会被清空,但是表结构还
-
MySQL中临时表的基本创建与使用教程
当工作在非常大的表上时,你可能偶尔需要运行很多查询获得一个大量数据的小的子集,不是对整个表运行这些查询,而是让MySQL每次找出所需的少数记录,将记录选择到一个临时表可能更快些,然后在这些表运行查询. 创建临时表很容易,给正常的CREATE TABLE语句加上TEMPORARY关键字: CREATE TEMPORARY TABLE tmp_table ( name VARCHAR(10) NOT NULL, value INTEGER NOT NULL ) 临时表将在你连接MySQL期间存在.当
-
MySQL的内存表的基础学习教程
内存表,就是放在内存中的表,所使用内存的大小可通过My.cnf中的max_heap_table_size指定,如max_heap_table_size=1024M,内存表与临时表并不相同,临时表也是存放在内存中,临时表最大所需内存需要通过tmp_table_size = 128M设定.当数据超过临时表的最大值设定时,自动转为磁盘表,此时因需要进行IO操作,性能会大大下降,而内存表不会,内存表满后,会提示数据满错误. 临时表和内存表都可以人工创建,但临时表更多的作用是系统自己创建后,组织数据以提升
-
MySQL两种临时表的用法详解
外部临时表 通过CREATE TEMPORARY TABLE 创建的临时表,这种临时表称为外部临时表.这种临时表只对当前用户可见,当前会话结束的时候,该临时表会自动关闭.这种临时表的命名与非临时表可以同名(同名后非临时表将对当前会话不可见,直到临时表被删除). 内部临时表 内部临时表是一种特殊轻量级的临时表,用来进行性能优化.这种临时表会被MySQL自动创建并用来存储某些操作的中间结果.这些操作可能包括在优化阶段或者执行阶段.这种内部表对用户来说是不可见的,但是通过EXPLAIN或者SHOW S
-
mysql中的临时表如何使用
目录 1.什么是临时表 2.临时表的使用场景 union groupby 3.groupby 如何优化 总结 1.什么是临时表 内部临时表是sql语句执行过程中,用来存储中间结果的的数据表,其作用类似于:join语句执行过程中的joinbuffer,order by语句执行过程中的sortBuffer一样. 这个表是mysql自己创建出来的,对客户端程序不可见.那么mysql什么时候会创建内部临时表呢?创建的内部临时表的表结构又是怎么样的呢? 2.临时表的使用场景 在mysql中常见的使用临时表
-
关于JDBC与MySQL临时表空间的深入解析
背景 临时表空间用来管理数据库排序操作以及用于存储临时表.中间排序结果等临时对象,相信大家在开发中经常会遇到相关的需求,下面本文将给大家详细JDBC与MySQL临时表空间的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 应用 JDBC 连接参数采用 useCursorFetch=true,查询结果集存放在 mysqld 临时表空间中,导致ibtmp1 文件大小暴增到90多G,耗尽服务器磁盘空间.为了限制临时表空间的大小,设置了: innodb_temp_data_fil