Java面试题冲刺第十六天--消息队列
目录
- 面试题1:说说你对消息队列的理解,消息队列为了解决什么问题?
- 解耦
- 异步
- 削峰
- 追问1:消息队列有什么优缺点
- 面试题2:对于消息中间机,你们是怎么做技术选型的?
- 面试题3:如何确保消息正确地发送至 RabbitMQ?如何确保消息接收方消费了消息?
- 发送方确认模式
- 接收方确认机制
- 追问1:如何保证MQ消息的可靠传输?
- 总结
面试题1:说说你对消息队列的理解,消息队列为了解决什么问题?
我们公司业务系统一开始体量较小,很多组件都是单机版就足够,后来随着用户量逐渐扩大,我们程序也采用了微服务的设计思想,把很多服务进行了拆分,但后来在一些秒杀抢票活动或高频业务中,服务依旧扛不住大量QPS,因此我们引入了消息队列来优化该类问题。
消息队列应用的场景大致分为三类:解耦、异步、削峰。
解耦
消息队列类似设计模式中的观察者模式(Observer)或发布-订阅模式(Pub-Sub)。生产者生成和发送消息到消息队列,消费者从消息队列中取走消息进行处理,称为消费,使用消息队列将“生产者”和“消费者”之间的操作关联解耦,易于扩展。
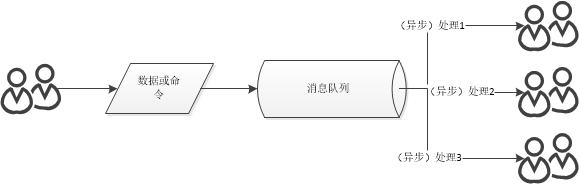
比如系统A为支付系统,一开始用户支付完调用日志记录系统B记录就完了,后来内容越来越多,支付完成要调用加积分系统C、短信通知系统D、优惠券系统E等等…
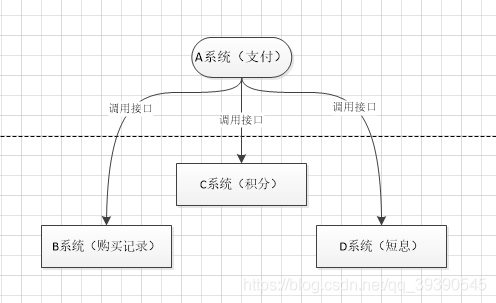
这个场景中,A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条支付成功的数据,很多系统接口都需要 A 系统调用把支付成功的数据发送过去。A 系统程序员要时刻考虑这些问题:
- 其他系统如果挂了该咋办?是不是直接程序抛异常了?
- 一天到晚加业务,每次都重新部署?领导是不是狗?
那如果引入 MQ,A 系统产生一条数据,发送到 MQ 里面去,每个子系统加上对消息队列中支付成功消息的订阅,持续监听就可以了,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。
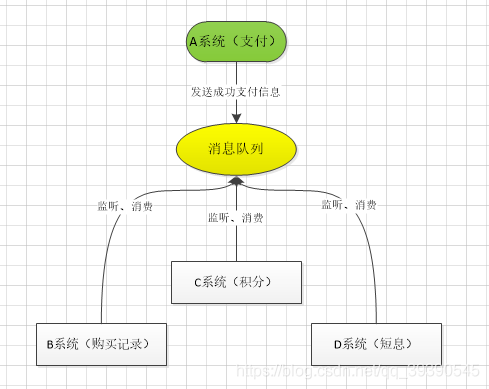
这样下来,A系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况,我只负责把支付成功的信息放到MQ里就行了,至于能否正常加积分、能否正常短信通知,管我鸟事!~~可见,通过一个 MQ,Pub/Sub 发布订阅消息这么一个模型,A 系统就跟其它系统彻底解耦了。
面试官:哦,那我听出来了,你这是喜欢甩锅啊!来,简历还你。

我:额。。不,我开玩笑的,当然不能这样做,这里其实涉及到MQ在分布式事务中数据一致性的问题;听我跟您解释。
数据一致性
这个其实是分布式服务本身就存在的一个问题,不仅仅是消息队列的问题,但是放在这里说是因为用了消息队列这个问题会更明显。
就像咱们上面说的,你支付成功的服务自己保证自己的逻辑成功处理了,你成功发了消息,但是短信系统,积分系统等等这么多系统,他们成功还是失败你就不管了?当然不行,这样坑队友的行为,狄大人都帮不了你~
怎么办?那就把所有的服务都放到一个事务里,所有都成功成功才能算这一次下单是成功的,要成功一起成功,要失败一起失败。
异步
A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、400ms、200ms。最终请求总延时是 3 + 300 + 400 + 200 = 903ms,接近 1秒,用户感觉搞个毛线?慢的一批。
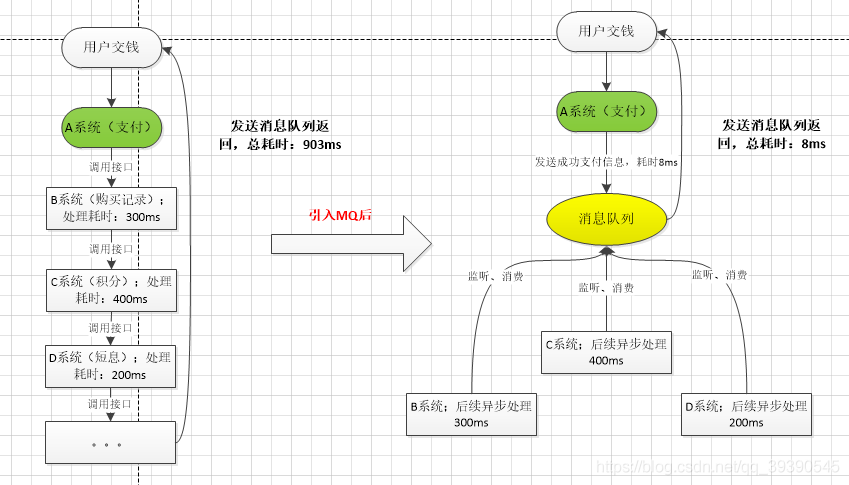
一般互联网类的企业,对于用户直接的操作,一般要求是每个请求都必须在 200 ms 以内完成,对用户几乎是无感知的,如果1秒足以说明该系统不可用,垃圾系统。
如果这里使用了消息队列,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms,对于用户而言,其实感觉上就是点个按钮,8ms 以后就直接返回了,体验感很好
削峰
比如我们系统有代售抢票业务,平时每天QPS也就50左右,A 系统风平浪静。结果每次一到春运抢票,每秒并发请求数量突然会暴增到10000以上。但是系统是直接基于 MySQL 的,大量的请求直接打到 MySQL,比如一般MySQL能抗2000条请求,现在每秒10000 条 SQL,可能就直接把 MySQL 给打死了,导致系统崩溃。但是高峰期一过就又没人了,QPS回到50,对整个系统几乎没有任何的压力。
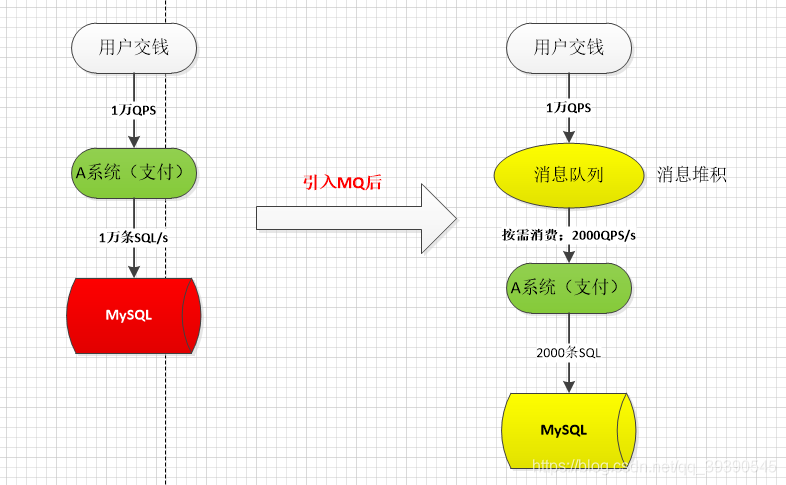
如果这里使用 MQ,每秒 1w 个请求写入 MQ,A 系统每秒钟最多处理 2000 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok了,这样下来,哪怕是高峰期的时候,A 系统也不会挂掉。当然了,用户的响应时间肯定会受影响,毕竟秒杀嘛,只要把前多少条请求处理好,其余的抢票失败就行了。
另外,MQ 每秒钟 1w 个请求进来,只处理 2k 个请求出去,结果会导致在中午高峰期,可能有几十万甚至几百万的请求积压在 MQ 中。
这个短暂的高峰期积压是 ok 的,因为高峰期过了之后,每秒钟就 50 个请求进 MQ,但是A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要高峰期一过,A 系统就会快速将积压的消息给消费掉。
追问1:消息队列有什么优缺点
- 系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,人 ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完了?如何保证消息队列的高可用?
- 系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息一定被消费?如何避免消息重复投递或重复消费?数据丢失怎么办?怎么保证消息传递的顺序性?
- 一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
面试题2:对于消息中间机,你们是怎么做技术选型的?
目前市面上比较主流的消息队列中间件主要有,Kafka、ActiveMQ、RabbitMQ、RocketMQ 等。
ActiveMQ和RabbitMQ这两由于吞吐量的原因,只有业务体量一般的公司在用,RabbitMQ由于是erlang语言开发的,我们都不了解,因此扩展和维护成本都很高,查个问题都头疼。
Kafka和RocketMQ一直在各自擅长的领域发光发亮,两者的吞吐量、可靠性、时效性等都很可观。
我们通过图表看看这几个消息中间机的对比:
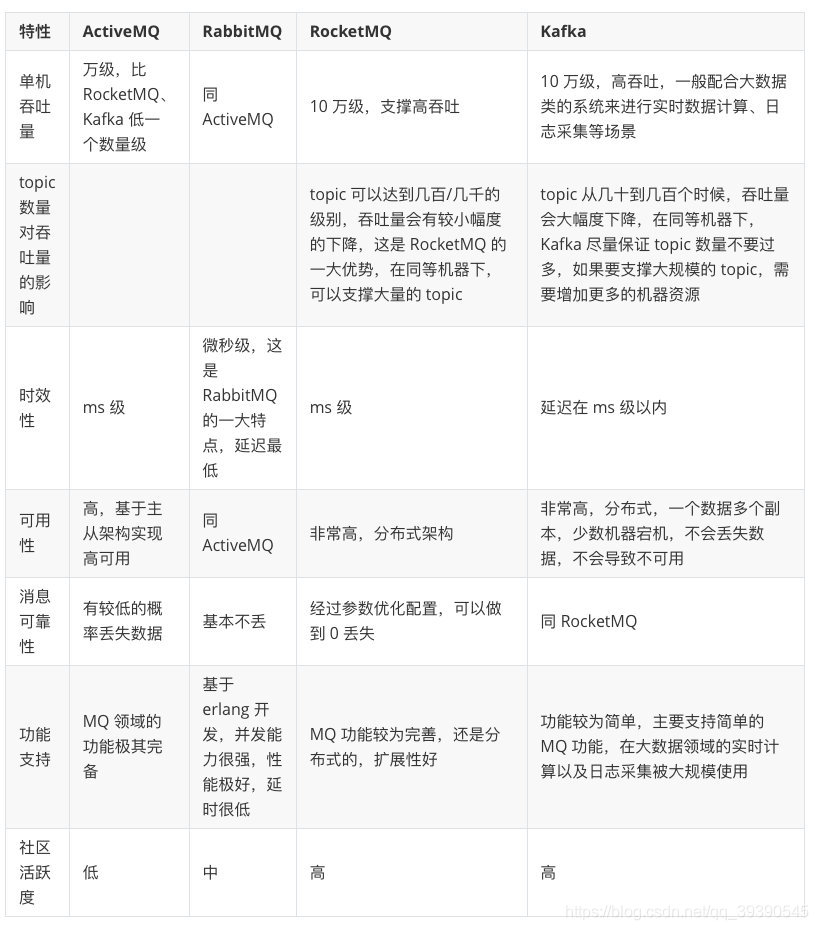
大家其实一下子就能看到差距了,就拿吞吐量来说,早期比较活跃的ActiveMQ 和RabbitMQ基本上不是后两者的对手了,在现在这样大数据的年代吞吐量是真的很重要。
面试题3:如何确保消息正确地发送至 RabbitMQ?如何确保消息接收方消费了消息?
发送方确认模式
将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。
一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。
如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条Nack(not acknowledged,未确认)消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
接收方确认机制
消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。
这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。保证数据的最终一致性;
追问1:如何保证MQ消息的可靠传输?
以我们常用的RabbitMQ为例,消息不可靠的情况可能是消息丢失,劫持等原因;
丢失又分为:生产者丢失消息、消息队列丢失消息、消费者丢失消息;
生产者丢失消息:从生产者弄丢数据这个角度来看,RabbitMQ提供confirm模式来确保生产者不丢消息;
confirm模式用的居多:一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;RabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;
如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
消息队列丢数据:消息持久化。
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
持久化配置和confirm机制配合使用,在消息持久化磁盘后,再给生产者发送一个Ack信号。
这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您关注我们的更多内容!
相关推荐
-

Java面试题冲刺第十四天--PRC框架
目录 面试题1:说说你对RPC框架的理解? 追问1:RPC框架实现原理是什么样的 1.建立通信 2.服务寻址 3.网络传输 4.服务调用 面试题2:常见的RPC框架有哪些? 面试题3:说说RPC和SOA.SOAP.REST的区别吧 1.REST 2.SOAP 3.SOA 总结 面试题1:说说你对RPC框架的理解? RPC (Remote Procedure Call)即远程过程调用,是分布式系统常见的一种通信方法.它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不
-
Java面试题冲刺第十九天--数据库(4)
目录 面试题1:说一下你对聚集索引与非聚集索引的理解,以及他们的区别? 1.聚集索引 2.非聚集索引 追问1:为什么聚集索引可以创建在任何一列上,如果此表没有主键约束,即有可能存在重复行数据呢? 追问2:聚集索引一定比非聚集索引性能优么? 面试题2:说一说你对 B树 和 B+树 的理解吧 1.B树(Balanced Tree)多路平衡查找树 多叉 2.B+ Tree (B+树是B树的变体,也是一种多路搜索树) 面试题3:说一下你对最左前缀原则的理解吧 一.最左匹配原则的原理 二.违背最左原则导致
-
Java面试题冲刺第十五天--设计模式
目录 面试题1:面向对象程序设计(OOP)的六大原则分别有哪几个 面试题2:你说一下什么是设计模式 追问1:那你怎么理解高内聚和低耦合? 面试题3:设计模式有哪几种? 追问1:你比较熟悉哪种设计模式?说说原理. 追问2:那你说说适配器模式的原理吧 适配器模式优缺点 总结 面试题1:面向对象程序设计(OOP)的六大原则分别有哪几个 开闭原则(Open Close Principle)及"开放-封闭原则"单一职责原则(Single Responsibility Principle)里氏替换
-
Java面试题冲刺第十八天--Spring框架3
面试题1:Bean 的加载过程是怎样的? 我们知道, Spring 的工作流主要包括以下两个环节: 解析,读 xml 配置,扫描类文件,从配置或者注解中获取 Bean 的定义信息,注册一些扩展功能. 加载,通过解析完的定义信息获取 Bean 实例. 下面是跟踪了 getBean的调用链创建的流程图,为了能够很好地理解 Bean 加载流程,省略一些异常.日志和分支处理和一些特殊条件的判断. 从上面的流程图中,可以看到一个 Bean 加载主要会经历这么几个阶段(标绿内容): 获取 BeanName,
-
Java面试题冲刺第十四天--基础篇3
目录 面试题1:JDK1.8的新特性有哪些? 接口的默认和静态方法: Lambda 表达式: 方法与构造函数引用: 函数式接口: Annotation 注解:支持多重注解: 新的日期时间 API: Base64编码: JavaScript引擎Nashorn: Stream的使用: Optional: 扩展注解的支持: 并行(parallel)数组: 编译器优化: 其他核心 API 的改进 Java IO改进 集合 API 的改进 面试题2:什么是内部类?内部类的作用? 内部类的作用 内部类特点
-
Java面试题冲刺第十六天--消息队列
目录 面试题1:说说你对消息队列的理解,消息队列为了解决什么问题? 解耦 异步 削峰 追问1:消息队列有什么优缺点 面试题2:对于消息中间机,你们是怎么做技术选型的? 面试题3:如何确保消息正确地发送至 RabbitMQ?如何确保消息接收方消费了消息? 发送方确认模式 接收方确认机制 追问1:如何保证MQ消息的可靠传输? 总结 面试题1:说说你对消息队列的理解,消息队列为了解决什么问题? 我们公司业务系统一开始体量较小,很多组件都是单机版就足够,后来随着用户量逐渐扩大,我们程序也采用了微服务的设
-
Java面试题冲刺第二十六天--实战编程
目录 面试题1:你们是怎样保存用户密码等敏感数据的? 面试题2:怎么控制用户请求的幂等性的? 1.设置唯一索引:防止新增脏数据 2.token机制:防止页面重复提交 3.悲观锁 4.乐观锁 5.分布式锁 面试题3:你们是如何预防SQL注入问题的? 预防方式: 1.PreparedStatement(简单有效) 2.使用正则表达式过滤传入的参数 3.使用正则表达式过滤传入的URL 总结 面试题1:你们是怎样保存用户密码等敏感数据的? 本题回答参考朱晔的<Java业务开发常见错误100例> 我们知
-
Java面试题冲刺第二十六天--实战编程2
目录 面试题2:怎么理解负载均衡的?你处理负载均衡都有哪些途径? 1.[协议层]http重定向 2.[协议层]DNS轮询 3.[协议层]CDN 4.[协议层]反向代理负载均衡 5.[网络层]IP负载均衡 面试题3:你平时是怎样定位线上问题的? 总结 面试题1:当你发现一条SQL很慢,你的处理思路是什么? 发现Bug 确定Bug不是自己造成的,如果无法确定,不要理会步骤1 向组内宣传"程序里有一个未知Bug,错不在我" 谁响应,谁对Bug负责 没人响应,就要求特定人员配合调试 如果不配合
-
Java面试题冲刺第二十四天--并发编程
目录 面试题1:说一下你对ReentrantLock的理解? CAS: AQS: 追问1:你认为 ReentrantLock 相比 synchronized 都有哪些区别? 面试题2:解释一下公平锁和非公平锁? 面试题3:能详细说一下CAS具体实现原理么? 追问1:那CAS的缺陷有哪些呢? 1.ABA: 2.自旋消耗资源: 3.多变量共享一致性问题: 追问2:讲一下什么是ABA问题?怎么解决? 总结 面试题1:说一下你对ReentrantLock的理解? ReentrantLock是JDK1.5
-
Java面试题冲刺第二十五天--实战编程2
目录 面试题2:怎么理解负载均衡的?你处理负载均衡都有哪些途径? 1.[协议层]http重定向 2.[协议层]DNS轮询 3.[协议层]CDN 4.[协议层]反向代理负载均衡 5.[网络层]IP负载均衡 面试题3:你平时是怎样定位线上问题的? 总结 面试题1:当你发现一条SQL很慢,你的处理思路是什么? 发现Bug 确定Bug不是自己造成的,如果无法确定,不要理会步骤1 向组内宣传"程序里有一个未知Bug,错不在我" 谁响应,谁对Bug负责 没人响应,就要求特定人员配合调试 如果不配合
-
Java面试题冲刺第二十五天--并发编程3
目录 面试题1:你了解线程池么?简单介绍一下. 追问1:连接池 和 线程池是一个意思么?有什么区别? 不同点 面试题2:线程池中核心线程数量大小你是怎么设置的? 追问1:核心线程数量过大或过小会造成什么后果? 面试题3:线程池都有哪些状态呀? 追问1:什么条件下会进入TERMINATED状态 总结 面试题1:你了解线程池么?简单介绍一下. java提供的一个java.util.concurrent.Executor接口的实现用于创建线程池. 线程池是一种多线程处理形式,处理过程中将任务提交到线程
-
Java面试题冲刺第二十五天--JVM2
目录 面试题1:简单说一下java的垃圾回收机制. 面试题2:JVM会在什么时候进行GC呢? 追问1:介绍一下不同代空间的垃圾回收机制 追问2:能说一下新生代空间的构成与执行逻辑么? 追问3:说一下发生OOM时,垃圾回收机制的执行流程. 面试题3:Full GC .Major GC和 Minor GC有什么不同 (1)Minor GC / Young GC (2)Old GC (3)Full GC (4)Major GC (5)Mixed GC 总结 面试题1:简单说一下java的垃圾回收机制.
-
Java面试题冲刺第二十九天--JVM3
目录 面试题1:如何判断对象是否存活 1.引用计数算法 2.可达性分析算法 面试题2:哪些对象可以作为GC Roots? 面试题3:你了解的对象引用方式都有哪些? 1 强引用 2 软引用 3 弱引用 4 虚引用 总结 面试题1:如何判断对象是否存活 对于判断对象是否存活,主要是两种基本算法,引用计数和可达性分析,目前java主要采用的是可达性分析算法 1.引用计数算法 判断对象是否存活的方式如:在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一:当引用失效时,计数器值就减一:任何