R语言-summary()函数的用法解读
summary():获取描述性统计量,可以提供最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等。
结果解读如下:
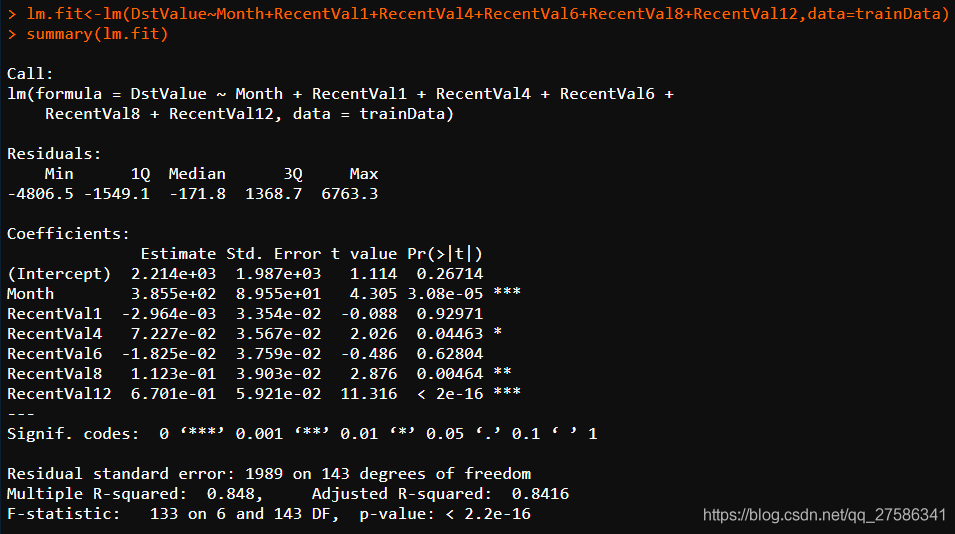
1. 调用:Call
lm(formula = DstValue ~ Month + RecentVal1 + RecentVal4 + RecentVal6 + RecentVal8 + RecentVal12, data = trainData)
当创建模型时,以上代码表明lm是如何被调用的。
2. 残差统计量:Residuals
Min 1Q Median 3Q Max
-4806.5 -1549.1 -171.8 1368.7 6763.3
残差第一四分位数(1Q)和第三分位数(Q3)有大约相同的幅度,意味着有较对称的钟形分布。
3. 系数:Coefficients
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.345e+06 5.659e+05 2.377 0.01879 *
Month 8.941e+02 2.072e+02 4.316 3.00e-05 ***
分别表示: 估值 标准误差 T值 P值
Intercept:表示截距
Month:影响因子/特征
Estimate的列:包含由普通最小二乘法计算出来的估计回归系数。
Std. Error的列:估计的回归系数的标准误差。
P值估计系数不显著的可能性,有较大P值的变量是可以从模型中移除的候选变量。
t 统计量和P值:从理论上说,如果一个变量的系数是0,那么该变量是无意义的,它对模型毫无贡献。
然而,这里显示的系数只是估计,它们不会正好为0。
因此,我们不禁会问:从统计的角度而言,真正的系数为0的可能性有多大?这是t统计量和P值的目的,在汇总中被标记为t value和Pr(>|t|)。
其 中,我们可以直接通过P值与我们预设的0.05进行比较,来判定对应的解释变量的显著性,我们检验的原假设是:该系数显著为0;若P<0.05,则拒绝原假设,即对应的变量显著不为0。
可以看到Month、RecentVal4、RecentVal8都可以认为是在P为0.05的水平下显著不为0,通过显著性检验;Intercept的P值为0.26714,不显著。
4. Multiple R-squared和Adjusted R-squared
这两个值,即R^{2},常称之为“拟合优度”和“修正的拟合优度”,指回归方程对样本的拟合程度几何,这里我们可以看到,修正的拟合优 度=0.8416,表示拟合程度良好,这个值当然是越高越好。
当然,提升拟合优度的方法很多,当达到某个程度,我们也就认为差不多了。
具体还有很复杂的判定内容,有兴趣的可以看看:http://baike.baidu.com/view/657906.htm
5. F-statistic
F-statistic,是我们常说的F统计量,也成为F检验,常常用于判断方程整体的显著性检验,其值越大越显著;其P值为p-value: < 2.2e-16,显然是<0.05的,可以认为方程在P=0.05的水平上还是通过显著性检验的。
简单总结:
T检验:检验解释变量的显著性;
R-squared:查看方程拟合程度;
F检验:是检验方程整体显著性。
如果是一元线性回归方程,T检验的值和F检验的检验效果是一样的,对应的值也是相同的。
补充:在R语言中显示美丽的数据摘要summary统计信息
总结数据集
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## ## Variable type: factor ## variable missing complete n n_unique top_counts ## 1 Species 0 150 150 3 set: 50, ver: 50, vir: 50, NA: 0 ## ordered ## 1 FALSE ## ## Variable type: numeric ## variable missing complete n mean sd min p25 median p75 max ## 1 Petal.Length 0 150 150 3.76 1.77 1 1.6 4.35 5.1 6.9 ## 2 Petal.Width 0 150 150 1.2 0.76 0.1 0.3 1.3 1.8 2.5 ## 3 Sepal.Length 0 150 150 5.84 0.83 4.3 5.1 5.8 6.4 7.9 ## 4 Sepal.Width 0 150 150 3.06 0.44 2 2.8 3 3.3 4.4 ## hist ## 1 ▇▁▁▂▅▅▃▁ ## 2 ▇▁▁▅▃▃▂▂ ## 3 ▂▇▅▇▆▅▂▂ ## 4 ▁▂▅▇▃▂▁▁
选择要汇总的特定列
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## ## Variable type: numeric ## variable missing complete n mean sd min p25 median p75 max ## 1 Petal.Length 0 150 150 3.76 1.77 1 1.6 4.35 5.1 6.9 ## 2 Sepal.Length 0 150 150 5.84 0.83 4.3 5.1 5.8 6.4 7.9 ## hist ## 1 ▇▁▁▂▅▅▃▁ ## 2 ▂▇▅▇▆▅▂▂
处理分组数据
可以处理已使用分组的数据dplyr::group_by。
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## group variables: Species ## ## Variable type: numeric ## Species variable missing complete n mean sd min p25 median ## 1 setosa Petal.Length 0 50 50 1.46 0.17 1 1.4 1.5 ## 2 setosa Petal.Width 0 50 50 0.25 0.11 0.1 0.2 0.2 ## 3 setosa Sepal.Length 0 50 50 5.01 0.35 4.3 4.8 5 ## 4 setosa Sepal.Width 0 50 50 3.43 0.38 2.3 3.2 3.4 ## 5 versicolor Petal.Length 0 50 50 4.26 0.47 3 4 4.35 ## 6 versicolor Petal.Width 0 50 50 1.33 0.2 1 1.2 1.3 ## 7 versicolor Sepal.Length 0 50 50 5.94 0.52 4.9 5.6 5.9 ## 8 versicolor Sepal.Width 0 50 50 2.77 0.31 2 2.52 2.8 ## 9 virginica Petal.Length 0 50 50 5.55 0.55 4.5 5.1 5.55 ## 10 virginica Petal.Width 0 50 50 2.03 0.27 1.4 1.8 2 ## 11 virginica Sepal.Length 0 50 50 6.59 0.64 4.9 6.23 6.5 ## 12 virginica Sepal.Width 0 50 50 2.97 0.32 2.2 2.8 3 ## p75 max hist ## 1 1.58 1.9 ▁▁▅▇▇▅▂▁ ## 2 0.3 0.6 ▂▇▁▂▂▁▁▁ ## 3 5.2 5.8 ▂▃▅▇▇▃▁▂ ## 4 3.68 4.4 ▁▁▃▅▇▃▂▁ ## 5 4.6 5.1 ▁▃▂▆▆▇▇▃ ## 6 1.5 1.8 ▆▃▇▅▆▂▁▁ ## 7 6.3 7 ▃▂▇▇▇▃▅▂ ## 8 3 3.4 ▁▂▃▅▃▇▃▁ ## 9 5.88 6.9 ▂▇▃▇▅▂▁▂ ## 10 2.3 2.5 ▂▁▇▃▃▆▅▃ ## 11 6.9 7.9 ▁▁▃▇▅▃▂▃ ## 12 3.18 3.8 ▁▃▇▇▅▃▁▂
指定统计信息和类
可以用户使用与该skim_with()功能组合的列表来指定自己的统计信息。
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## ## Variable type: numeric ## variable iqr mad ## 1 Sepal.Length 1.3 1.04
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言:数据筛选match的使用详解
数据筛选是在分析中最常用的步骤,如微生物组分析中,你的OTU表.实验设计.物种注释之间都要不断筛选,来进行数据对齐,或局部分析. 今天来详解一下此函数的用法. match match:匹配两个向量,返回x中存在的返回索引或TRUE.FALSE match函数使用格式有如下两种: 第一种方便设置参数,返回x中元素在table中的位置 match(x, table, nomatch = NA_integer_, incomparables = NULL) 第二种简洁,返回x中每个元素在table中是
-

R语言中cut()函数的用法说明
R语言cut()函数使用 cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码. 参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数. breaks采用fivenum():返回五个数据:最小值.下四分位数.中位数.上四分位数.最大值. labels为区间数,打标签 ordered_result 逻辑结果应该是一个有序的因素吗? 先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采用(]的区间,
-
R语言中c()函数与paste()函数的区别说明
c()函数:将括号中的元素连接起来,并不创建向量 paste()函数:连接括号中的元素 例如 c(1, 2:4),结果为1 2 3 4 paste(1, 2:4),结果为"1 2" "1 3" "1 4" c(2, "and"),结果为"2" "and" paste(2, "and"),结果为"2 and" 补充:R语言中paste函数的参数sep
-
R语言-生成频数表和列联表crosstable函数介绍
列联表crosstable 列联表不仅可以用来做简单的描述性统计,还可以在机器学习中用来比较识别正确率,FPR,TPR等等数据,以便我们比较不同的ML模型 or 调参. 2x2列联表一般长下面这样: Total Observations in Table: 143 | test_cancer$diagnosis lda.class | 0 | 1 | Row Total | -------------|-----------|-----------|-----------| 0 | 82 | 1
-
R语言中if(){}else{}语句和ifelse()函数的区别详解
首先看看定义: # if statement if(cond) expr if(cond) cons.expr else alt.expr # ifelse function ifelse(test, yes, no) 这两个函数(R语言中都是函数)相同的地方都是根据条件返回对应的值. 区别在于: if语句的条件是个TRUE/FALSE值,如果是个长度>1的逻辑向量,只判断第一个TRUE/FALSE值:而ifelse是长度任意的逻辑向量,返回根据逻辑向量对应对的yes/no值组合的新向量 ife
-
R语言中的fivenum与quantile()函数算法详解
fivenum()函数: 返回五个数据:最小值.下四分位数数.中位数.上四分位数.最大值 对于奇数个数字=5,fivenum()先排序,依次返回最小值.下四分位数.中位数.上四分位数.最大值 > fivenum(c(1,12,40,23,13)) [1] 1 12 13 23 40 对于奇数个数字>5,fivenum()先排序,我们可以求取最小值,最大值,中位数.在排序中,最小值与中位数中间,若为奇数,取其中位数为下四分位数,若为偶数,取最中间两个数的平均值为下四分位数:在排序中,中位数与最大
-
R语言中assign函数和get函数的用法
assign函数在循环时候,给变量赋值,算是比较方便 1.给变量赋值 for (i in 1:(length(rowSeq)-1)){ assign(paste("nginx_server_fields7_", i, sep = ""), nginx_server_fields7[(rowSeq[(i-1)+1]):(rowSeq[i+1]), ]) } 2.通过for循环给变量a1.a2.a3赋值 for (i in 1:3){ assign(paste(&quo
-
R语言-summary()函数的用法解读
summary():获取描述性统计量,可以提供最小值.最大值.四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等. 结果解读如下: 1. 调用:Call lm(formula = DstValue ~ Month + RecentVal1 + RecentVal4 + RecentVal6 + RecentVal8 + RecentVal12, data = trainData) 当创建模型时,以上代码表明lm是如何被调用的. 2. 残差统计量:Residuals Min 1Q M
-
R语言strsplit函数用法深入详解
1.R语言strsplit用于分割字符串 创建测试数据 > test <- "aa bb cc dd ee ff" ##创建测试数据 > test [1] "aa bb cc dd ee ff" > class(test) ## 测试数据为字符 [1] "character" 2.按照指定分隔符拆分字符串 > a <- strsplit(test,split = " ") ##制动分隔符为空
-
R语言seq()函数的调用方法
看到有很多读者浏览了这篇文章,心里很是开心,为了能够更好地帮助大家,决定再修改一下,帮助大家更好地理解. --------修改于:2018年4月28日 为了方便大家在开发环境中直接实验测试代码,下面,我将说明和函数的用法全部用英文给出(避免乱码),并加以注释,希望能够对大家有所帮助! 首先,我们来看一个seq()函数应用的实例! x <- seq(0, 10, by = 0.01) y <- sin(x) plot(y) 下面,我们来看函数的主要使用方法! 注意:在本文调用函数时,均采用写出入
-
R语言boxplot函数深入讲解
箱线图简介 箱线图又称箱形图或盒须图,该图是由5个特征值绘制而成的图形. 5个特征值是变量的最大值.最小值.中位数.第1四分位数和第3四分位数. 连接两个分位数画出一个箱子,箱子用中位数分割,把两个极值点与箱子用线条连接,即成箱线图. R中绘制箱线图的函数boxplot (1)基本用法 boxplot(x, ...) (2)公式形式的用法 boxplot(formula, data = NULL, ..., subset, na.action = NULL, drop = FALSE, sep
-
GO语言延迟函数defer用法分析
本文实例讲述了GO语言延迟函数defer用法.分享给大家供大家参考.具体分析如下: defer 在声明时不会立即执行,而是在函数 return 后,再按照 FILO (先进后出)的原则依次执行每一个 defer,一般用于异常处理.释放资源.清理数据.记录日志等.这有点像面向对象语言的析构函数,优雅又简洁,是 Golang 的亮点之一. 代码1:了解 defer 的执行顺序 复制代码 代码如下: package main import "fmt" func fn(n int) int {
-
Linux 中C语言getcwd()函数的用法
Linux 中C语言getcwd()函数的用法 先来看该函数的声明: #include<unistd.h> char *getcwd(char *buf,size_t size); 介绍: 参数说明:getcwd()会将当前工作目录的绝对路径复制到参数buffer所指的内存空间中,参数size为buf的空间大小. 普通的用法会是这样: #define MAX_SIZE 255 char path(MAX_SIZE); getcwd(path,sizeof(path)); puts(path);
-
用R语言绘制函数曲线图
函数曲线图是研究函数的重要工具. R 中 curve() 函数可以绘制函数的图像,代码格式如下: curve(expr, from = NULL, to = NULL, n = 101, add = FALSE, type = "l", xname = "x", xlab = xname, ylab = NULL, log = NULL, xlim = NULL, -) # S3 函数的方法 plot(x, y = 0, to = 1, from = y, xlim
-
详解R语言plot函数参数合集
最近用R语言画图,plot 函数是用的最多的函数,而他的参数非常繁多,由此总结一下,以供后续方便查阅. plot(x, y = NULL, type = "p", xlim = NULL, ylim = NULL, log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL, ann = par("ann"), axes = TRUE, frame.plot = axes, panel.
-
R语言Legend函数深入详解
legend(x, y = NULL, legend, fill = NULL, col = par("col"), border = "black", lty, lwd, pch, angle = 45, density = NULL, bty = "o", bg = par("bg"), box.lwd = par("lwd"), box.lty = par("lty"), box.
-
c语言abort函数实例用法
1.abort函数的作用是异常终止一个进程,意味着abort后面的代码将不再执行. 2.当调用abort函数时,会导致程序异常终止,而不会进行一些常规的清除工作. 实例 #include <stdio.h> #include <stdlib.h> int main(void) { puts( "About to abort..../n" ); abort(); puts( "This will never be executed!/n" );