python爬虫基础之简易网页搜集器
简易网页搜集器
前面我们已经学会了简单爬取浏览器页面的爬虫。但事实上我们的需求当然不是爬取搜狗首页或是B站首页这么简单,再不济,我们都希望可以爬取某个特定的有信息的页面。
不知道在学会了爬取之后,你有没有跟我一样试着去爬取一些搜索页面,比如说百度。像这样的页面
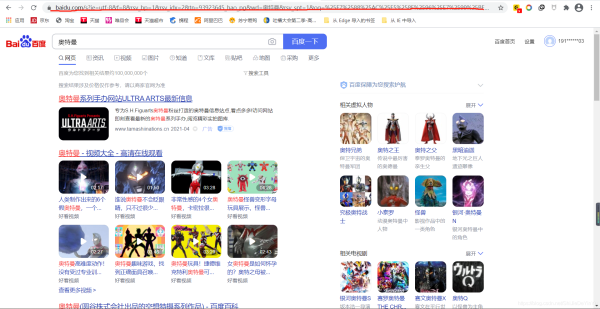
注意我红笔划的部分,这是我打开的网页。现在我希望能爬取这一页的数据,按我们前面学的代码,应该是这样写的:
import requests
if __name__ == "__main__":
# 指定URL
url = "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&tn=93923645_hao_pg&wd=%E5%A5%A5%E7%89%B9%E6%9B%BC&rsv_spt=1&oq=%25E7%2588%25AC%25E5%258F%2596%25E7%2599%25BE%25E5%25BA%25A6%25E9%25A6%2596%25E9%25A1%25B5&rsv_pq=b233dcfd0002d2d8&rsv_t=ccdbEuqbJfqtjnkFvevj%2BfxQ0Sj2UP88ixXHTNUNsmTa9yWEWTUEgxTta9r%2Fj3mXxDs%2BT1SU&rqlang=cn&rsv_dl=tb&rsv_enter=1&rsv_sug3=8&rsv_sug1=5&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=1424&rsv_sug4=1424"
# 发送请求
response = requests.get(url)
# 获取数据
page_text = response.text
# 存储
with open("./奥特曼.html", "w", encoding = "utf-8") as fp:
fp.write(page_text)
print("爬取成功!!!")
然而打开我们保存的文件,发现结果跟我们想的不太一样
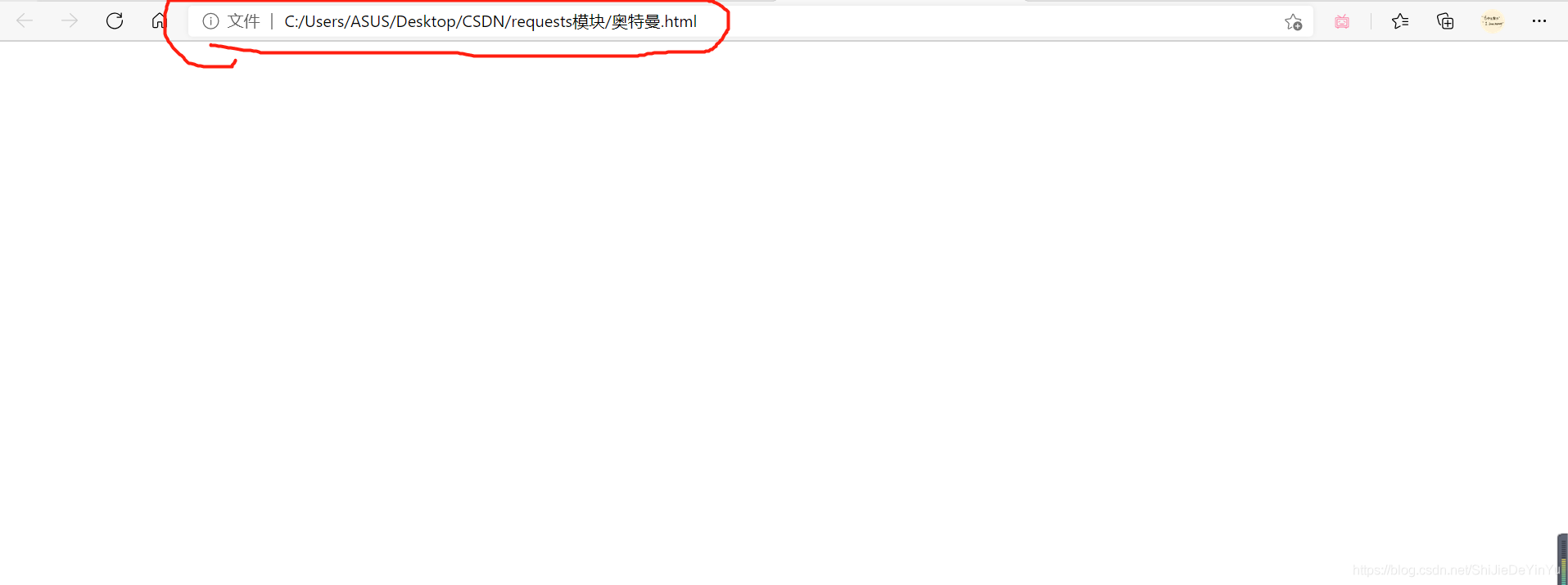
我们发现我们保存的文件是一个空白的页面,这是为什么呢?
其实上我们把网址改成搜狗的可能或更直观一些(不知道为什么我这边的搜狗总是打不开,所以就用百度做例子,可以自己写写有关搜狗搜索的代码),同样的代码改成搜狗的网址结果是这样的
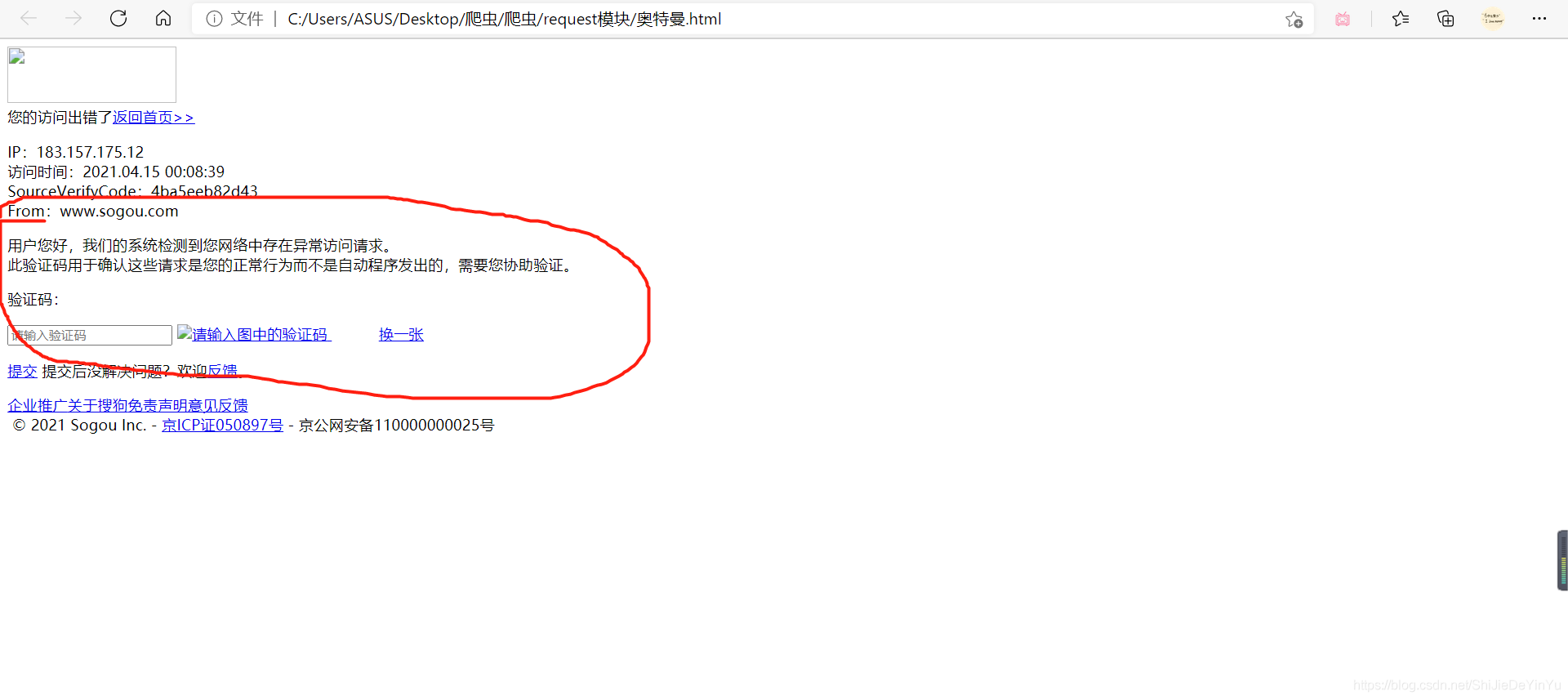
我们发现其中有句话是 “ 网络中存在异常访问 ”,那么这句话是什么意思呢?
这句话的意思就是说,搜狗或是百度注意到发送请求的是爬虫程序,而不是人工操作。
那么这其中的原理又是什么呢?
简单来说,就是程序访问和我们使用浏览器访问是有区别的,被请求的服务器都是靠 user-agent 来判断访问者的身份,如果是浏览器就接受请求,否则就拒绝。这就是一个很常见的反爬机制。
那是不是我们就没有办法呢?
非也~所谓魔高一尺,道高一丈。既然要识别 user-agent ,那么我们就让爬虫模拟 user-agent 好了。
在 python 中模拟输入数据或是 user-agent ,我们一般用字典
就这样子写:
header = {
"user-agent": "" # user-agent 的值 是一个长字符串
}
那么 user-agent 的值又是怎么得到的呢?
1. 打开任意网页,右键点击,选择“检查”
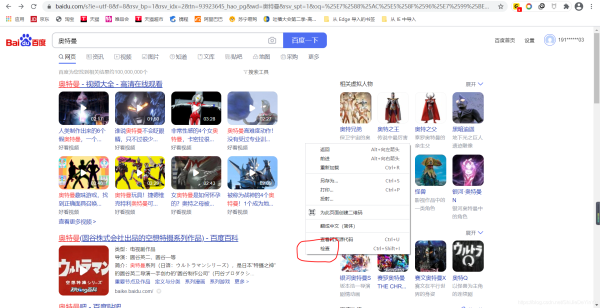
2. 选择“ Network ”(谷歌浏览器)(如果是中文,就选择 “网络” 这一项)
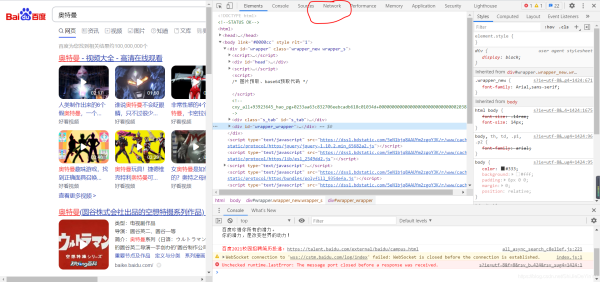
3. 如果发现点开是空白的,像这样,那就刷新网页
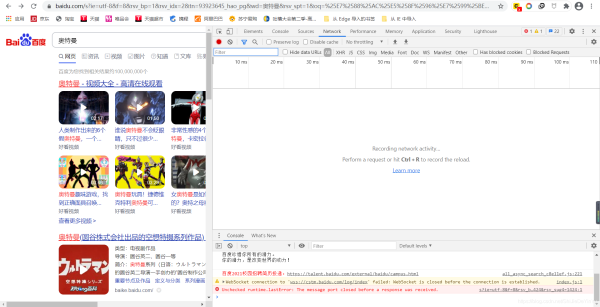
刷新后是这样的:
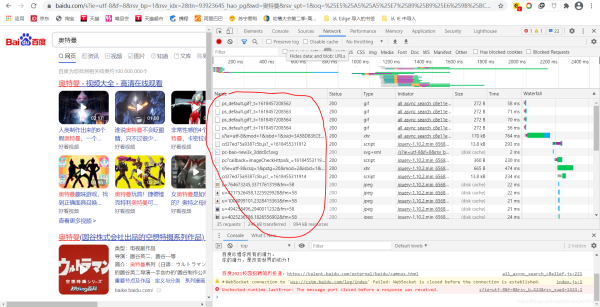
然后随机选择红笔圈起来的一项,我们会看到这样的东西,然后在里面找到“user-agent”,把它的值复制下来就行了
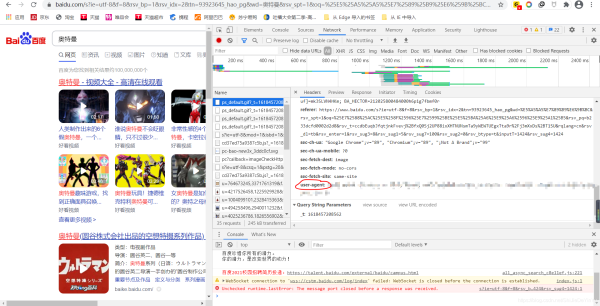
有了 “user-agent”, 我们在重新写我们的爬取网页的代码,就可以了
import requests
if __name__ == "__main__":
# 指定URL
url = "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&tn=93923645_hao_pg&wd=%E5%A5%A5%E7%89%B9%E6%9B%BC&rsv_spt=1&oq=%25E7%2588%25AC%25E5%258F%2596%25E7%2599%25BE%25E5%25BA%25A6%25E9%25A6%2596%25E9%25A1%25B5&rsv_pq=b233dcfd0002d2d8&rsv_t=ccdbEuqbJfqtjnkFvevj%2BfxQ0Sj2UP88ixXHTNUNsmTa9yWEWTUEgxTta9r%2Fj3mXxDs%2BT1SU&rqlang=cn&rsv_dl=tb&rsv_enter=1&rsv_sug3=8&rsv_sug1=5&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=1424&rsv_sug4=1424"
# 模拟 “user-agent”,即 UA伪装
header = {
"user-agent" : "" # 复制的 user-agent 的值
}
# 发送请求
response = requests.get(url, headers = header)
# 获取数据
page_text = response.text
# 存储
with open("./奥特曼(UA伪装).html", "w", encoding = "utf-8") as fp:
fp.write(page_text)
print("爬取成功!!!")
再次运行,然后打开文件
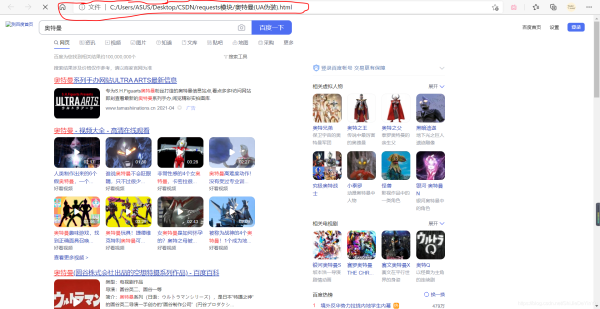
这次成功了,说明我们的爬虫程序完美地骗过了服务器
到此这篇关于python爬虫基础之简易网页搜集器的文章就介绍到这了,更多相关python网页搜集器内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
python爬虫之利用selenium模块自动登录CSDN
一.页面分析 CSDN登录页面如下图 二.引入selenium模块及驱动 2.1 并将安装好的Chromedriver.exe引入到代码中 # -*- coding:utf-8 -*- from selenium import webdriver import os import time #引入chromedriver.exe chromedriver="C:/Users/lex/AppData/Local/Google/Chrome/Application/chromedriver.exe&
-
python爬虫之爬取笔趣阁小说
前言 为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 一.首先导入相关的模块 import os import requests from bs4 import BeautifulSoup 二.向网站发送请求并获取网站数据 网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例. 进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取 # 声明请求头 headers = { 'Use
-
Python爬虫爬取爱奇艺电影片库首页的实例代码
上篇文章给大家介绍了Python爬取爱奇艺电影信息代码实例 感兴趣的朋友点击查看下. 今天给大家介绍Python爬虫爬取爱奇艺电影片库首页,下面是实例代码,参考下: import time import traceback import requests from lxml import etree import re from bs4 import BeautifulSoup from lxml.html.diff import end_tag import json import pymys
-
python爬虫之bs4数据解析
一.实现数据解析 因为正则表达式本身有难度,所以在这里为大家介绍一下 bs4 实现数据解析.除此之外还有 xpath 解析.因为 xpath 不仅可以在 python 中使用,所以 bs4 和 正则解析一样,仅仅是简单地写两个案例(爬取可翻页的图片,以及爬取三国演义).以后的重点会在 xpath 上. 二.安装库 闲话少说,我们先来安装 bs4 相关的外来库.比较简单. 1.首先打开 cmd 命令面板,依次安装bs4 和 lxml. 2. 命令分别是 pip install bs4 和 pip
-
python爬虫之爬取百度翻译
破解百度翻译 翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢? 爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的.百度做到这一点是用 AJAX 实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新. 了解了这一点,那么我们要怎么得到 AJAX 工作时请求的URL呢?老规矩,使用抓包工具. 爬虫步骤 在 "百度
-
Python爬虫之爬取哔哩哔哩热门视频排行榜
一.bs4解析 import requests from bs4 import BeautifulSoup import datetime if __name__=='__main__': url = 'https://www.bilibili.com/v/popular/rank/all' headers = { //设置自己浏览器的请求头 } page_text=requests.get(url=url,headers=headers).text soup=BeautifulSoup(pag
-
用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈. 今天分享个如何简单处理滑动图片的验证码的案例. 类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别.同时也能拦截掉大部分初级爬虫. 作为一只python爬虫,如何正确地自动完成这个验证过程呢? 先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium
-
Python爬虫之爬取最新更新的小说网站
一.引言 这个五一假期自驾回老家乡下,家里没装宽带,用手机热点方式访问网络.这次回去感觉4G信号没有以前好,通过百度查找小说最新更新并打开小说网站很慢,有时要打开好多个网页才能找到可以正常打开的最新更新.为了躲懒,老猿决定利用Python爬虫知识,写个简单应用自己查找小说最新更新并访问最快的网站,花了点时间研究了一下相关报文,经过近一天时间研究和编写,终于搞定,下面就来介绍一下整个过程. 二.关于相关访问请求及应答报文 2.1.百度搜索请求 我们通过百度网页的搜索框进行搜索时,提交的url请求是
-
python基础之爬虫入门
前言 python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程. 爬虫分为四个步骤:请求,解析数据,提取数据,存储数据.本文也会从这四个角度介绍基础爬虫的案例. 一.简单静态网页的爬取 我们要爬取的是一个壁纸网站的所有壁纸 http://www.netbian.com/dongman/ 1.1 选取爬虫策略--缩略图 首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的img标签并向它发送请求就可以得到壁纸的预览图
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
上手简单,功能强大的Python爬虫框架——feapder
简介 feapder 是一款上手简单,功能强大的Python爬虫框架,使用方式类似scrapy,方便由scrapy框架切换过来,框架内置3种爬虫: AirSpider爬虫比较轻量,学习成本低.面对一些数据量较少,无需断点续爬,无需分布式采集的需求,可采用此爬虫. Spider是一款基于redis的分布式爬虫,适用于海量数据采集,支持断点续爬.爬虫报警.数据自动入库等功能 BatchSpider是一款分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫. feapder除了支持断点续爬.数