Python7个爬虫小案例详解(附源码)中篇
目录
- 前言
- 题目三:
- 分别使用XPath和Beautiful Soup4两种方式爬取并保存非异步加载的“豆瓣某排行榜”如https://movie.douban.com/top250的名称、描述、评分和评价人数等数据
- 题目四:
- 实现某东商城某商品评论数据的爬取(评论数据不少于100条,包括评论内容、时间和评分)
本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。
前言
关于Python7个爬虫小案例的文章分为三篇,本篇为中篇,共两题,其余两篇内容请关注!
题目三:
分别使用XPath和Beautiful Soup4两种方式爬取并保存非异步加载的“豆瓣某排行榜”如https://movie.douban.com/top250的名称、描述、评分和评价人数等数据
先分析:
首先,来到豆瓣Top250页面,首先使用Xpath版本的来抓取数据,先分析下电影列表页的数据结构,发下都在网页源代码中,属于静态数据

接着我们找到数据的规律,使用xpath提取每一个电影的链接及电影名

然后根据链接进入到其详情页
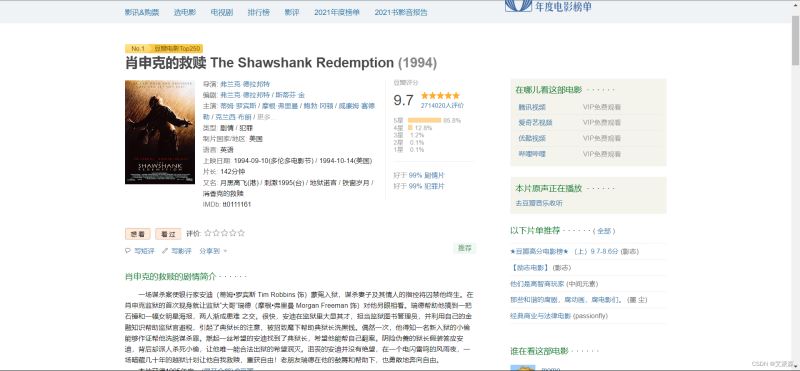
分析详情页的数据,发现也是静态数据,继续使用xpath提取数据

最后我们将爬取的数据进行存储,这里用csv文件进行存储

接着是Beautiful Soup4版的,在这里,我们直接在电影列表页使用bs4中的etree进行数据提取

最后,同样使用csv文件进行数据存储
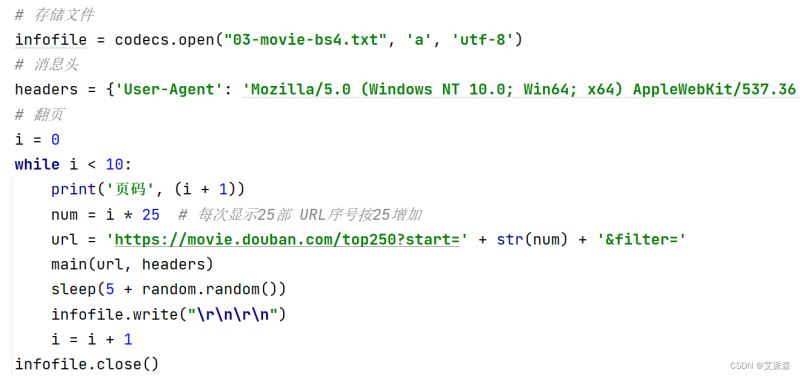
源代码即结果截图:
XPath版:
import re
from time import sleep
import requests
from lxml import etree
import random
import csv
def main(page,f):
url = f'https://movie.douban.com/top250?start={page*25}&filter='
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',}
resp = requests.get(url,headers=headers)
tree = etree.HTML(resp.text)
# 获取详情页的链接列表
href_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/@href')
# 获取电影名称列表
name_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
for url,name in zip(href_list,name_list):
f.flush() # 刷新文件
try:
get_info(url,name) # 获取详情页的信息
except:
pass
sleep(1 + random.random()) # 休息
print(f'第{i+1}页爬取完毕')
def get_info(url,name):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'Host': 'movie.douban.com',
}
resp = requests.get(url,headers=headers)
html = resp.text
tree = etree.HTML(html)
# 导演
dir = tree.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]
# 电影类型
type_ = re.findall(r'property="v:genre">(.*?)</span>',html)
type_ = '/'.join(type_)
# 国家
country = re.findall(r'地区:</span> (.*?)<br',html)[0]
# 上映时间
time = tree.xpath('//*[@id="content"]/h1/span[2]/text()')[0]
time = time[1:5]
# 评分
rate = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
# 评论人数
people = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span/text()')[0]
print(name,dir,type_,country,time,rate,people) # 打印结果
csvwriter.writerow((name,dir,type_,country,time,rate,people)) # 保存到文件中
if __name__ == '__main__':
# 创建文件用于保存数据
with open('03-movie-xpath.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
# 写入表头标题
csvwriter.writerow(('电影名称','导演','电影类型','国家','上映年份','评分','评论人数'))
for i in range(10): # 爬取10页
main(i,f) # 调用主函数
sleep(3 + random.random())

Beautiful Soup4版:
import random
import urllib.request
from bs4 import BeautifulSoup
import codecs
from time import sleep
def main(url, headers):
# 发送请求
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
# 用BeautifulSoup解析网页
soup = BeautifulSoup(contents, "html.parser")
infofile.write("")
print('爬取豆瓣电影250: \n')
for tag in soup.find_all(attrs={"class": "item"}):
# 爬取序号
num = tag.find('em').get_text()
print(num)
infofile.write(num + "\r\n")
# 电影名称
name = tag.find_all(attrs={"class": "title"})
zwname = name[0].get_text()
print('[中文名称]', zwname)
infofile.write("[中文名称]" + zwname + "\r\n")
# 网页链接
url_movie = tag.find(attrs={"class": "hd"}).a
urls = url_movie.attrs['href']
print('[网页链接]', urls)
infofile.write("[网页链接]" + urls + "\r\n")
# 爬取评分和评论数
info = tag.find(attrs={"class": "star"}).get_text()
info = info.replace('\n', ' ')
info = info.lstrip()
print('[评分评论]', info)
# 获取评语
info = tag.find(attrs={"class": "inq"})
if (info): # 避免没有影评调用get_text()报错
content = info.get_text()
print('[影评]', content)
infofile.write(u"[影评]" + content + "\r\n")
print('')
if __name__ == '__main__':
# 存储文件
infofile = codecs.open("03-movie-bs4.txt", 'a', 'utf-8')
# 消息头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
# 翻页
i = 0
while i < 10:
print('页码', (i + 1))
num = i * 25 # 每次显示25部 URL序号按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
main(url, headers)
sleep(5 + random.random())
infofile.write("\r\n\r\n")
i = i + 1
infofile.close()

题目四:
实现某东商城某商品评论数据的爬取(评论数据不少于100条,包括评论内容、时间和评分)
先分析:
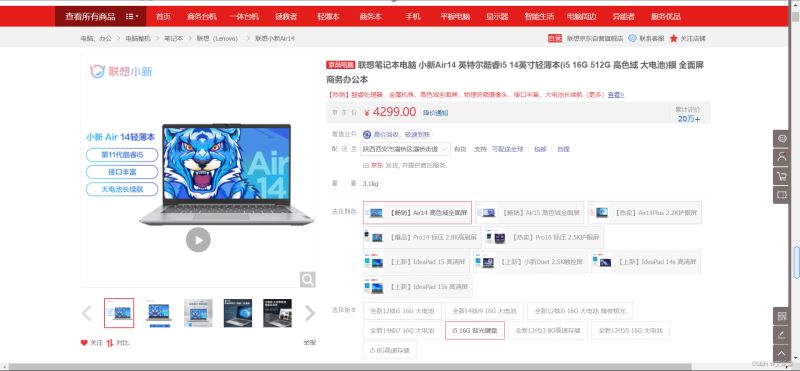
本次选取的某东官网的一款联想笔记本电脑,数据为动态加载的,通过开发者工具抓包分析即可。
源代码及结果截图:
import requests
import csv
from time import sleep
import random
def main(page,f):
url = 'https://club.jd.com/comment/productPageComments.action'
params = {
'productId': 100011483893,
'score': 0,
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'referer': 'https://item.jd.com/'
}
resp = requests.get(url,params=params,headers=headers).json()
comments = resp['comments']
for comment in comments:
content = comment['content']
content = content.replace('\n','')
comment_time = comment['creationTime']
score = comment['score']
print(score,comment_time,content)
csvwriter.writerow((score,comment_time,content))
print(f'第{page+1}页爬取完毕')
if __name__ == '__main__':
with open('04.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('评分','评论时间','评论内容'))
for page in range(15):
main(page,f)
sleep(5+random.random())
到此这篇关于Python7个爬虫小案例详解(附源码)中篇的文章就介绍到这了,其他两个部分的内容(上、下篇)请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫之超级鹰验证码应用
目录 超级鹰平台 基础使用 剪切验证码 超级鹰平台 验证码的破解可以有以下方式: 简单的数字字母组合可以使用图像识别(python 现成模块),成功率不高 使用第三方打码平台(破解验证码平台),花钱,把验证码图片给它,返回识别完的结果 第三方平台有超级鹰等等. 基础使用 在其官网注册账号后,绑定微信会提供免费的1000题分,可用于验证码识别 创建开发者账号,并且注册一个软件 下载 python demo 基础使用 下载的demo是使用python2编写的,需要简单修改 import reques
-
Python爬虫学习之requests的使用教程
目录 requests库简介 requests库安装 1.pip命令安装 2.下载代码进行安装 requests库的使用 发送请求 get请求 抓取二进制数据 post请求 POST请求的文件上传 利用requests返回响应状态码 requests库简介 requests 库是一个常用的用于 http 请求的模块,它使用 python 语言编写,可以方便的对网页进行爬取,是学习 python 爬虫的较好的http请求模块. 它基于 urllib 库,但比 urllib 方便很多,能完全满足我们
-
Python爬虫程序中使用生产者与消费者模式时进程过早退出的问题
之前写爬虫程序的时候,采用生产者和消费者的模式,利用Queue作为生产者进程和消费者进程之间的同步队列. 执行程序时,总是秒退,加了断点也无法中断,加打印也无法输出,我知道肯定是进程退出了,但还是百思不得解,为什么会这么快就退出. 一开始以为是我的进程代码写的有问题,在某个地方崩溃导致程序提前退出,排查了一遍又一遍,并没有发现什么明显的问题,后来走读代码,看到主模块中消费者和生产者进程的启动后,发现了问题,原因是我通过start()方法启动进程后,使用join()的方式有问题.消费者进程必须执行
-
Python爬虫Requests库的使用详情
目录 一.Requests库的7个主要的方法 二.Response对象的属性 三.爬取网页通用代码 四.Resquests库的常见异常 五.Robots协议展示 六.案例展示 一.Requests库的7个主要的方法 1.request() 构造请求,支撑以下的基础方法 2.get() 获取HTML页面的主要方法,对应于http的get 3.head() 获取HTML页面的头部信息的主要方法,对应于http的head -以很少的流量获取索要信息的概要内容 4.post() 向HTML提
-
Python7个爬虫小案例详解(附源码)上篇
目录 前言 题目一: 使用正则表达式和文件操作爬取并保存“百度贴吧”某帖子全部内容(该帖不少于5页) 题目二: 实现多线程爬虫爬取某小说部分章节内容并以数据库存储(不少于10个章节) 本次的7个python爬虫小案例涉及到了re正则.xpath.beautiful soup.selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习. 前言 关于Python7个爬虫小案例的文章分为三篇,本篇为上篇,共两题,其余两篇内容请关注! 题目一: 使用正则表达式和文件操作爬取并保存“百度贴吧
-
Python爬虫eval实现看漫画漫画柜mhgui实战分析
目录 ️ 看漫画MHG mhgui 实战分析 通过开发者工具的 DOM 事件绑定器 截取相应的代码文件 eval 函数解析 ️ 看漫画MHG mhgui 实战分析 本文所有MHG使用 MHG 替代~ 本次爬虫采集的案例是MHG,该站点貌似本身就游走在法律的边缘. 站点地址直接检索即可进入,在该目标站点,橡皮擦发现了 eval 加密的双重用法. 页面所有点位都无太大难点,而且漫画超多,但是当点击详情页的时候,发现加密点位了. https://i.看评论区.com/ps1/u/17287/cmdty
-
python爬虫实战项目之爬取pixiv图片
自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下. 爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不例外. 首先我们来实现模拟登陆,虽然大多数情况不需要我们实现模拟登录,但如果你是会员之类的,登录和不登录网页就有区别.思路是登录时抓包抓到post请求,看pixiv构建的post的数据表格是什么格式,我们根据这个格式构建form,然后调用post方法去请求,再
-
通过python爬虫mechanize库爬取本机ip地址的方法
目录 需求分析 实现分析 实际使用 完整代码演示 需求分析 最近,各平台更新的ip属地功能非常火爆,因此呢,也出现了许多新的网络用语,比如说“xx加几分”,“xx扣大分”等等,非常的有趣啊 可是呢,最近一个小伙伴和我说,“仙草哥哥,我也想查看一下自己的ip地址,可是我不会啊,我应该怎么样才能查看到自己的ip地址呢?” 关于如何查看自己的ip地址,这个我记得我在很早之前已经写过了,有兴趣的话可以查看一下我的这篇文章,当然这次呢,我会换一个复古的方式,使用mechanize进行爬取 实现分析 pyt
-
Python利用yield form实现异步协程爬虫
目录 1.什么是yield 2.yield于列表的区别 3.yield from 实现协程 很古老的用法了,现在大多用的aiohttp库实现,这篇记录仅仅用做个人的协程底层实现的学习. 争取用看得懂的字来描述问题. 1.什么是yield 如果还没有怎么用过的话,直接把yield看做成一种特殊的return(PS:本质 generator(生成器))return是返回一个值然后就终断函数了,而yield返回的是一个生成器(PS:不知道的直接看作特殊列表,看下面的代码案例) # -*- coding
-
Python7个爬虫小案例详解(附源码)下篇
目录 前言 题目五: 实现多种方法模拟登录知乎,并爬取与一个与江汉大学有关问题和答案 题目六: 综合利用所学知识,爬取某个某博用户前5页的微博内容 题目七: 自选一个热点或者你感兴趣的主题,爬取数据并进行简要数据分析 本次的7个python爬虫小案例涉及到了re正则.xpath.beautiful soup.selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习. 前言 关于Python7个爬虫小案例的文章分为三篇,本篇为下篇,共三题,其余两篇内容请关注! 题目五: 实现多种方
-
python爬虫之代理ip正确使用方法实例
目录 代理ip原理 输入网址后发生了什么呢? 代理ip做了什么呢? 为什么要用代理呢? 爬虫代码中使用代理ip 检验代理ip是否生效 未生效问题排查 1.请求协议不匹配 2.代理失效 总结 主要内容:代理ip使用原理,怎么在自己的爬虫里设置代理ip,怎么知道代理ip是否生效,没生效的话哪里出了问题,个人使用的代理ip(付费). 代理ip原理 输入网址后发生了什么呢? 1.浏览器获取域名 2.通过DNS协议获取域名对应服务器的ip地址 3.浏览器和对应的服务器通过三次握手建立TCP连接 4.浏览器
-
使用python爬虫实现子域名探测问题
目录 前言 一.爬虫 1.ip138 2.bing 二.通过字典进行子域名爆破 三.python爬虫操作步骤 1.写出请求头headers与目标网站url 2.生成请求 3.抓取数据 4.分析源码,截取标签中内容 四.爬虫一些总结 前言 意义:子域名枚举是为一个或多个域查找子域的过程,它是信息收集阶段的重要组成部分.实现方法:使用爬虫与字典爆破. 一.爬虫 1.ip138 def search_2(domain): res_list = [] headers = { 'Accept': '*/*
-
python爬虫beautiful soup的使用方式
目录 前言 一,Beautiful Soup简介 二,Beautiful Soup的解析器 2.1 各种解析器一览 2.2 引入解析器的语法 三,Beautiful Soup解析得到的四种对象 3.1 四种对象 一览 3.2 bs对象的tag属性 3.3 bs对象的prettify属性及prettify()方法 3.4 bs对象tag对象的属性获取 3.5 NavigableString对象 3.6 comment对象及beautiful soup对象 四,标签的定位 4.1 find()&f
-
Python爬虫框架NewSpaper使用详解
目录 写在前面 newspaper newspaper框架的使用 例如:单条新闻内容获取 newspaper文章缓存 其他功能 写在后面 写在前面 原计划继续写一篇Portia的使用博客,结果在编写代码途中发现,在windows7的DockerToolbox里面使用Portia错误实在是太多了,建议大家还是在Linux虚拟机或者直接在服务器上去运行.否则太耗费精力了~ 今天我们转移一下,介绍一款newspaper newspaper github地址 : github.com/codelucas
-
python 基于aiohttp的异步爬虫实战详解
目录 引言 aiohttp是什么 requests和aiohttp区别 安装aiohttp aiohttp使用介绍 基本实例 URL参数设置 请求类型 响应的几个方法 超时设置 并发限制 aiohttp异步爬取实战 总结 引言 钢铁知识库,一个学习python爬虫.数据分析的知识库.人生苦短,快用python. 之前我们使用requests库爬取某个站点的时候,每发出一个请求,程序必须等待网站返回响应才能接着运行,而在整个爬虫过程中,整个爬虫程序是一直在等待的,实际上没有做任何事情. 像这种占用
-
python爬虫模拟登录之图片验证码实现详解
我们在用爬虫对门户网站进行模拟登录是总会有输入图片验证码的,例如这种 那我们怎么解决这个问题实现全自动的模拟登录呢?只要思想不滑坡,办法总比困难多.我这里使用的是百度智能云里面的文字识别功能,每天好像可以免费使用个几百次,识别效果也还行,对一般人而言是够用了. 接下来说说,怎么使用. 首先,打开百度智能云(https://cloud.baidu.com/)进行登入,再进入人工智能->文字识别里创建应用. 在使用名称和底下应用描述随便写写,然后点立即创建. 创建完成,就可以拿到 AppID .AP
-
Python爬虫库urllib的使用教程详解
目录 Python urllib库 urllib.request模块 urlopen函数 Request 类 urllib.error模块 URLError 示例 HTTPError示例 URLError和HTTPError混合使用 urllib.parse模块 urlparse() urlunparse() urlsplit() urljoin() URL 转码 编码quote(string) 编码urlencode() 解码 unquote(string) urllib.robotparse
-
python爬虫之requests库使用代理方式
目录 安装上requests库 GET方法 谷歌浏览器的开发者工具 POST方法 使用代理 在看这篇文章之前,需要大家掌握的知识技能: python基础 html基础 http状态码 让我们看看这篇文章中有哪些知识点: get方法 post方法 header参数,模拟用户 data参数,提交数据 proxies参数,使用代理 进阶学习 安装上requests库 pip install requests 先来看下帮助文档,看看requests的介绍,用python自带的help命令 import