Redis实现UV统计的示例代码
目录
- 一、HyperLogLog
- 1、为什么用HyperLogLog
- 2、HyperLogLog是什么
- 二、实现UV统计
一、HyperLogLog
1、为什么用HyperLogLog
先介绍两个概念:
UV:全称 Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人、1 天内同一个用户多次访问该网站,只记录 1 次。
PV:全称 Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录一次 PV,用户多次打开页面,则记录多次 PV。往往用来衡量网站的流量。
UV 统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis 中,数据量会非常恐怖。
那么我们要怎么更好的记录呢?就用到 HyperLogLog
2、HyperLogLog是什么
HyperLogLog(HLL)是从 Loglog 算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。
Redis 中的 HLL 是基于 String 结构实现的,单个 HLL 的内存永远小于 16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于 0.81% 的误差。不过对于 UV 统计来说,这完全可以忽略。
不管加入多少重复元素,HyperLogLog都只记录一次,天生适合做uv的统计
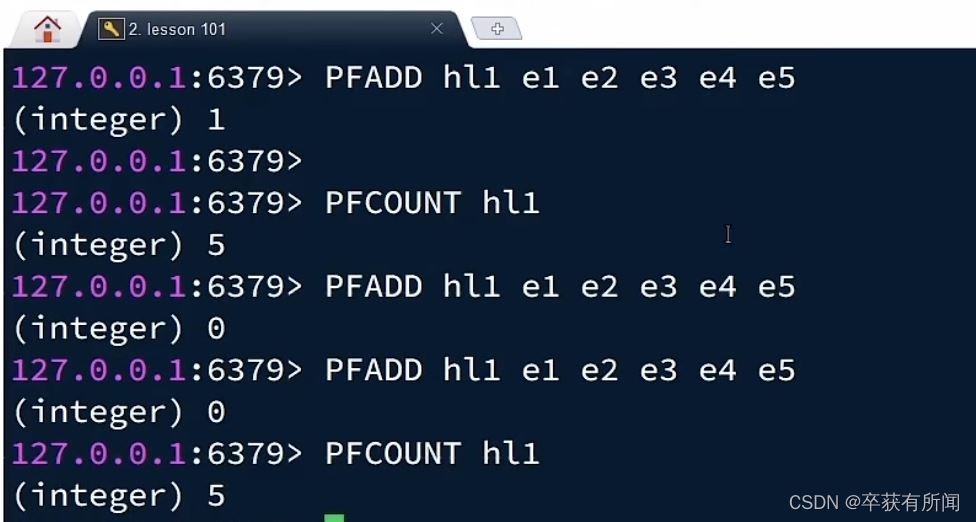
二、实现UV统计
我们直接用单元测试,向 HyperLogLog 中添加 100 万条数据,看看内存占用和统计效果如何:
@Test
void testHyperLogLog() {
String[] values = new String[1000];
int j = 0;
for (int i = 0; i < 1000000; i++) {
j = i % 1000;
values[j] = "user_" + i;
if(j == 999){
// 发送到 Redis
stringRedisTemplate.opsForHyperLogLog().add("hl2", values);
}
}
// 统计数量
Long count = stringRedisTemplate.opsForHyperLogLog().size("hl2");
System.out.println("count = " + count);
}
测试结果:
我们统计出来的数据跟100万非常接近,误差在0.02。而且发现内存只消耗了14kb非常非常低
到此这篇关于Redis实现UV统计的示例代码的文章就介绍到这了,更多相关Redis UV统计内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
微服务Spring Boot 整合 Redis 实现UV 数据统计的详细过程
目录 引言 一.HyperLoglog基础用法 HyperLoglog 基本语法.命令 HyperLoglog 命令完成功能实现 二.UV统计 测试百万数据的统计 ️什么是UV统计 使用SpringBoot单元测试进行测试百万数据统计 小结 引言 本文参考黑马 点评项目 在各个项目中,我们都可能需要用到UV数据统计功能,这样可以使我们更加方便.快捷的查看网站的活跃度! 一.HyperLoglog基础用法 HyperLoglog 基本语法.命令 HyperLogLog PFADD :将指定元素添加
-
Redis实现UV统计的示例代码
目录 一.HyperLogLog 1.为什么用HyperLogLog 2.HyperLogLog是什么 二.实现UV统计 一.HyperLogLog 1.为什么用HyperLogLog 先介绍两个概念: UV:全称 Unique Visitor,也叫独立访客量,是指通过互联网访问.浏览这个网页的自然人.1 天内同一个用户多次访问该网站,只记录 1 次.PV:全称 Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录一次 PV,用户多次打开页面,则记录多次 PV.往往用来衡量
-

SpringBoot整合Redis实现访问量统计的示例代码
目录 前言 Spring Boot 整合 Redis 引入依赖.增加配置 翠花!上代码 前言 之前开发系统的时候客户提到了一个需求:需要统计某些页面的访问量,记得当时还纠结了一阵子,不知道怎么去实现这个功能,后来还是在大佬的带领下借助 Redis 实现了这个功能.今天又回想起了这件事,正好和大家分享一下 Spring Boot 整合 Redis 实现访问量统计的全过程. 首先先解释一下为什么需要借助 Redis,其实原因也很简单,就是因为它非常快(每秒可执行大约110000次的 SET 操作,每
-
利用Redis实现点赞功能的示例代码
目录 MySQL 和 Redis优缺点 1.Redis 缓存设计及实现 部分代码如下 Redis 存储结构如图 2.数据库设计 3.开启定时任务持久化存储到数据库 部分代码如下 提到点赞,大家一想到的是不是就是朋友圈的点赞呀?其实点赞对我们来说并不陌生,我们经常会在手机软件或者网页中看到它,今天就让我们来了解一下它的实现吧.我们常见的设计思路大概分为两种:一种自然是用 MySQL 等数据库直接落地存储, 另外一种就是将点赞的数据保存到 Redis 等缓存里,在一定时间后刷回 MySQL 等数据库
-
Java利用Redis实现消息队列的示例代码
本文介绍了Java利用Redis实现消息队列的示例代码,分享给大家,具体如下: 应用场景 为什么要用redis? 二进制存储.java序列化传输.IO连接数高.连接频繁 一.序列化 这里编写了一个java序列化的工具,主要是将对象转化为byte数组,和根据byte数组反序列化成java对象; 主要是用到了ByteArrayOutputStream和ByteArrayInputStream; 注意:每个需要序列化的对象都要实现Serializable接口; 其代码如下: package Utils
-
Docker 部署 SpringBoot 项目整合 Redis 镜像做访问计数示例代码
最终效果如下 大概就几个步骤 1.安装 Docker CE 2.运行 Redis 镜像 3.Java 环境准备 4.项目准备 5.编写 Dockerfile 6.发布项目 7.测试服务 环境准备 系统:Ubuntu 17.04 x64 Docker 17.12.0-ce IP:45.32.31.101 一.安装 Docker CE 国内不建议使用:"脚本进行安装",会下载安装很慢,使用步骤 1 安装,看下面的链接:常规安装方式 1.常规安装方式 Ubuntu 17.04 x64 安装
-
MyBatis整合Redis实现二级缓存的示例代码
MyBatis框架提供了二级缓存接口,我们只需要实现它再开启配置就可以使用了. 特别注意,我们要解决缓存穿透.缓存穿透和缓存雪崩的问题,同时也要保证缓存性能. 具体实现说明,直接看代码注释吧! 1.开启配置 SpringBoot配置 mybatis: configuration: cache-enabled: true 2.Redis配置以及服务接口 RedisConfig.java package com.leven.mybatis.api.config; import com.fasterx
-
SpringBoot集成redis实现分布式锁的示例代码
1.准备 使用redis实现分布式锁,需要用的setnx(),所以需要集成Jedis 需要引入jar,jar最好和redis的jar版本对应上,不然会出现版本冲突,使用的时候会报异常redis.clients.jedis.Jedis.set(Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;I)Ljava/lang/String; 我使用的redis版本是2.3.0,Jedis使用的是3.3.0 <de
-
用Go+Redis实现分布式锁的示例代码
目录 为什么需要分布式锁 分布式锁需要具备特性 实现 Redis 锁应先掌握哪些知识点 set 命令 Redis.lua 脚本 go-zero 分布式锁 RedisLock 源码分析 关于分布式锁还有哪些实现方案 项目地址 为什么需要分布式锁 用户下单 锁住 uid,防止重复下单. 库存扣减 锁住库存,防止超卖. 余额扣减 锁住账户,防止并发操作. 分布式系统中共享同一个资源时往往需要分布式锁来保证变更资源一致性. 分布式锁需要具备特性 排他性 锁的基本特性,并且只能被第一个持有者持有. 防死锁
-
Redis实现排名功能的示例代码
目录 前言 一.实现思路 二.具体实现 小结 前言 之前在消费金融平台的时候,公司有一个专门给线下销售人员使用的APP,APP记录销售推广公司贷款产品赚取的佣金以及一些门店开拓和打卡的功能,后端是由我和另外一个同事开发的,其中有一个模块是全国门店内的销售佣金实时排名,说到排名很多人的第一反应都是这是个Top N的问题,从数据库取出来用MySQL的top函数不就可以实现了,事实上当时无法从表里取到数据,数据还要配合权限,有全国和大区的排名,还需要计算大区经理下所有人员的有效佣金,还要求是实时的,从
-
SpringBoot+Redis实现布隆过滤器的示例代码
目录 简述 Redis安装BloomFilter 基本指令 结合SpingBoot 方式一 方式二 简述 关于布隆过滤器的详细介绍,我在这里就不再赘述一遍了 我们首先知道:BloomFilter使用长度为m bit的字节数组,使用k个hash函数,增加一个元素: 通过k次hash将元素映射到字节数组中k个位置中,并设置对应位置的字节为1.查询元素是否存在: 将元素k次hash得到k个位置,如果对应k个位置的bit是1则认为存在,反之则认为不存在. Guava 中已经有具体的实现,而在我们实际生产