pytorch从头开始搭建UNet++的过程详解
目录
- Unet++代码
- 网络架构
- Backbone
- 上采样
- 下采样
- 深度监督
- 网络架构代码
Unet是一个最近比较火的网络结构。它的理论已经有很多大佬在讨论了。本文主要从实际操作的层面,讲解pytorch从头开始搭建UNet++的过程。
Unet++代码
网络架构
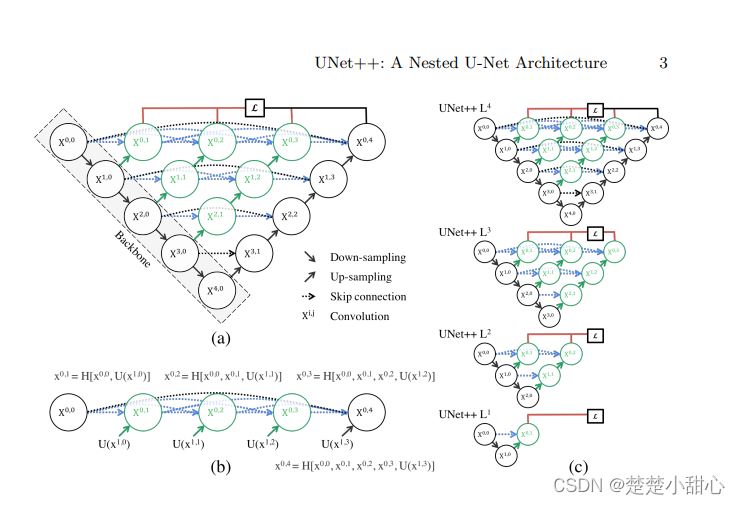
黑色部分是Backbone,是原先的UNet。
绿色箭头为上采样,蓝色箭头为密集跳跃连接。
绿色的模块为密集连接块,是经过左边两个部分拼接操作后组成的
Backbone
2个3x3的卷积,padding=1。
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
上采样
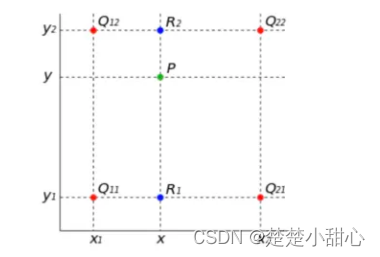
图中的绿色箭头,上采样使用双线性插值。
双线性插值就是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None)
参数说明:
①size:可以用来指定输出空间的大小,默认是None;
②scale_factor:比例因子,比如scale_factor=2意味着将输入图像上采样2倍,默认是None;
③mode:用来指定上采样算法,有’nearest’、 ‘linear’、‘bilinear’、‘bicubic’、‘trilinear’,默认是’nearest’。上采样算法在本文中会有详细理论进行讲解;
④align_corners:如果True,输入和输出张量的角像素对齐,从而保留这些像素的值,默认是False。此处True和False的区别本文中会有详细的理论讲解;
⑤recompute_scale_factor:如果recompute_scale_factor是True,则必须传入scale_factor并且scale_factor用于计算输出大小。计算出的输出大小将用于推断插值的新比例。请注意,当scale_factor为浮点数时,由于舍入和精度问题,它可能与重新计算的scale_factor不同。如果recompute_scale_factor是False,那么size或scale_factor将直接用于插值。
class Up(nn.Module):
def __init__(self):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return x
下采样
图中的黑色箭头,采用的是最大池化。
self.pool = nn.MaxPool2d(2, 2)
深度监督
所示,该结构下有4个分支,可以分为两种模式。
精确模式:4个分支取平均值结果
快速模式:只选择一个分支,其余被剪枝
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
网络架构代码
class NestedUNet(nn.Module):
def __init__(self, num_classes=1, input_channels=1, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = Up()
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(self.up(x1_0, x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(self.up(x2_0, x1_0))
x0_2 = self.conv0_2(self.up(x1_1, torch.cat([x0_0, x0_1], 1)))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(self.up(x3_0, x2_0))
x1_2 = self.conv1_2(self.up(x2_1, torch.cat([x1_0, x1_1], 1)))
x0_3 = self.conv0_3(self.up(x1_2, torch.cat([x0_0, x0_1, x0_2], 1)))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(self.up(x4_0, x3_0))
x2_2 = self.conv2_2(self.up(x3_1, torch.cat([x2_0, x2_1], 1)))
x1_3 = self.conv1_3(self.up(x2_2, torch.cat([x1_0, x1_1, x1_2], 1)))
x0_4 = self.conv0_4(self.up(x1_3, torch.cat([x0_0, x0_1, x0_2, x0_3], 1)))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
到此这篇关于pytorch从头开始搭建UNet++的过程详解的文章就介绍到这了,更多相关pytorch搭建UNet++内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何搭建pytorch环境的方法步骤
1.conda创建虚拟环境pytorch_gpu conda create -n pytorch_gpu python=3.6 创建虚拟环境还是相对较快的,它会自动为本环境安装一些基本的库,等待时间无需很长,成功之后界面如下所示: 2.切换到pytorch环境 使用如下命令,切换到我们刚刚创建好的pytorch虚拟环境,这样我们避免与其它python环境之间的干扰. conda activeta pytorch_gpu 切换成功之后就会看到在路径前边显示我们已经进入该虚拟环境. 3.安装几个常用
-
PyTorch在Windows环境搭建的方法步骤
一.安装Anaconda 3.5 Anaconda是一个用于科学计算的Python发行版,支持Linux.Mac和Window系统,提供了包管理与环境管理的功能,可以很方便地解决Python并存.切换,以及各种第三方包安装的问题. 二.下载和安装 个人建议推荐在清华的镜像来下载.选择合适你的版本下载,我使用的是Anaoonda3-5.1.0-Windows-x86_64.exe 可能安装速度有点慢,不太清楚是我电脑系统盘快慢的原因还是什么. 环境变量配置 将D:\ProgramData\Anac
-
使用Pytorch搭建模型的步骤
本来是只用Tenorflow的,但是因为TF有些Numpy特性并不支持,比如对数组使用列表进行切片,所以只能转战Pytorch了(pytorch是支持的).还好Pytorch比较容易上手,几乎完美复制了Numpy的特性(但还有一些特性不支持),怪不得热度上升得这么快. 1 模型定义 和TF很像,Pytorch也通过继承父类来搭建自定义模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化
-
Anaconda+vscode+pytorch环境搭建过程详解
1.安装Anaconda Anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项.在官网上下载https://www.anaconda.com/distribution/,因为服务器在国外会很慢,建议从清华镜像https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/下载. 2.安装VScode 需要在Anaconda再装VScode,因为Anaconda公司和微软公司的合作,不用在对进
-
关于pytorch中全连接神经网络搭建两种模式详解
pytorch搭建神经网络是很简单明了的,这里介绍两种自己常用的搭建模式: import torch import torch.nn as nn first: class NN(nn.Module): def __init__(self): super(NN,self).__init__() self.model=nn.Sequential( nn.Linear(30,40), nn.ReLU(), nn.Linear(40,60), nn.Tanh(), nn.Linear(60,10), n
-

pytorch从头开始搭建UNet++的过程详解
目录 Unet++代码 网络架构 Backbone 上采样 下采样 深度监督 网络架构代码 Unet是一个最近比较火的网络结构.它的理论已经有很多大佬在讨论了.本文主要从实际操作的层面,讲解pytorch从头开始搭建UNet++的过程. Unet++代码 网络架构 黑色部分是Backbone,是原先的UNet. 绿色箭头为上采样,蓝色箭头为密集跳跃连接. 绿色的模块为密集连接块,是经过左边两个部分拼接操作后组成的 Backbone 2个3x3的卷积,padding=1. class VGGBlo
-
vue-cli3.0 脚手架搭建项目的过程详解
1.安装vue-cli 3.0 npm install -g @vue/cli # or yarn global add @vue/cli 安装成功后查看版本:vue -V(大写的V) 2.命令变化 vue create --help 用法:create [options] <app-name> 创建一个由 `vue-cli-service` 提供支持的新项目 选项: -p, --preset <presetName> 忽略提示符并使用已保存的或远程的预设选项 -d
-
Java搭建RabbitMq消息中间件过程详解
这篇文章主要介绍了Java搭建RabbitMq消息中间件过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 前言 当系统中出现"生产"和"消费"的速度或稳定性等因素不一致的时候,就需要消息队列. 名词 exchange: 交换机 routingkey: 路由key queue:队列 控制台端口:15672 exchange和queue是需要绑定在一起的,然后消息发送到exchange再由exchange通过ro
-
利用nginx与ffmpeg搭建流媒体服务器过程详解
需求 本文介绍的是利用nginx和ffmpeg搭建流媒体服务器的过程.例如这种场景:公司内部需要同时观看在线直播时,如果每个人直接观看必然给出口带宽带来压力,影响正常访问外网的同事.所以可以在内网通过nginx+ffmpeg拉一路直播流,然后内网的用户访问内网的这台流媒体服务器即可.通过nginx+ffmpeg还可以实现推流.拉流.转推甚至利用FFmpeg实时切片.视频处理等,实现一套直播服务模型. 环境 系统环境:CentOS release 6.7 (Final) 步骤 安装ffmpeg 安
-
Python使用socketServer包搭建简易服务器过程详解
官方提供了socketserver包去方便我们快速的搭建一个服务器框架. server类 socketserver包提供5个Server类,这些单独使用这些Server类都只能完成同步的操作,他是一个单线程的,不能同时处理各个客户端的请求,只能按照顺序依次处理. +------------+ | BaseServer | +------------+ | v +-----------+ +------------------+ | TCPServer |------->| UnixStreamS
-
Linux服务器搭建nvidia-docker环境过程详解
docker相当于一个容器,其可以根据你所需要的运行环境构建相应的运行环境,此时各个环境之间彼此隔离,就不会存在在需要跑一个新的代码的时候破坏原来跑的代码所需要的环境,各个环境之间彼此隔离开,好像一个个容器将其隔离开一样 由于docker只针对在CPU上面跑的情况,对于需要在GPU上面运行的服务器,其提供了一个nvidia-docker sudo apt-get install -y nvidia-docker2 sudo pkill -SIGHUP docker 对于怎么在服务器子账户上面搭建
-
React全家桶环境搭建过程详解
本文介绍了React全家桶环境搭建过程详解,分享给大家,具体如下: 环境搭建 1.从零开始搭建webpack+react开发环境 2.引入Typescript 安装依赖 npm i -S @types/react @types/react-dom npm i -D typescript awesome-typescript-loader source-map-loader 新建tsconfig.json { "compilerOptions": { "outDir"
-
spring cloud alibaba Nacos 注册中心搭建过程详解
这篇文章主要介绍了spring cloud alibaba Nacos 注册中心搭建过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 nacos下载地址 什么是 Nacos? nacos主要起到俩个作用一个是注册中心,另外一个是配置中心. 下面图 是nacos的功能结构图 运行环境 JDK 1.8+: Maven 3.2.x+: 下载 你可以通过源码和发行包两种方式来获取 Nacos. nacos发行包下载地址 选择版本解压 unzip
-
Springcould多模块搭建Eureka服务器端口过程详解
这篇文章主要介绍了Springcould多模块搭建Eureka服务器端口过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1创建一个普通父maven 在pom修改为因为spring could依赖spring boot所以首先在父maven <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-star