Rust编写自动化测试实例权威指南
目录
- 一. 简述
- 二. 编写测试
- 三. 测试相关的宏和函数
- 3.1. 使用assert!宏检查结果
- 3.2. 使用assert_eq!宏和assert_ne!宏判断相等性
- 3.3. 添加自定义的错误提示信息
- 3.4. 使用should_panic检查paninc
- 3.5. 使用Result<T, E>编写测试
- 四. 控制测试的运行方式
- 4.1. 并行或串行的进行测试
- 4.2. 显示函数输出
- 4.3. 只运行部分特定名称的测试
- 4.4. 通过显示指定来忽略某些测试
- 五. 测试的组织结构
- 5.1. 单元测试
- 5.2. 集成测试
一. 简述
虽然Rust的类型系统为我们提供了相当多的安全保障,但是还是不足以防止所有的错误。因此,Rust在语言层面内置了编写测试代码、执行自动化测试任务的功能。
测试是一门复杂的技术,本章覆盖关于如何编写优秀测试的每一个细节,但是会讨论Rust测试工具的运行机制。我们会向你介绍编写测试时常用的标注和宏、运行测试的默认行为和选项参数,以及如何将测试用例组织为单元测试与集成测试。
二. 编写测试
Rust语言中的测试时一个函数,它被用于验证非测试代码是否按照期望的方式运行。测试函数的函数体中一般包含3个部分:
- 准备所需的数据或状态
- 调用需要测试的代码
- 断言运行结果与我们期望的一致
接下来,我们会一起学习用于编写测试代码的相关功能,它们包含test属性、一些测试宏及should_panic属性。此时我们将建一个库项目:cargo new adder —lib
此时adder库项目自动生成一个src/lib.rs文件,此时cargo会给我们创建一个简单的测试代码模块:
pub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test] // @1
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4); // @2
}
}
我们可以看到@1这一行的#[test]标注:它将当前的函数标记为一个测试,并使该函数可以在测试运行中被识别出来。要知道,即便是在tests模块中也可能会存在普通的非测试函数,它们通常被用来执行初始化操作或一些常用指令,所以我们必须要将测试函数标注为#[test]。函数体中@2使用了assert_eq!宏断言,这是一个典型的测试用例编写方式。这时我们执行命令:cargo test
xxxxx@xxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.05s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 1 test // 正在执行一个测试
test tests::it_works ... ok // 此时函数
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s // 测试摘要,表示该集合中的所有测试均成功通过,1 passed; 0 failed则统计了通过和失败的测试总数
Doc-tests adder // 文件测试的结果
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
此时我们删除初始化的代码,我们编写下面两个测试函数:
extern crate core;
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ok_test() {
assert_eq!(2 + 2, 4);
}
#[test]
fn fail_test() {
panic!("Make this test fail");
}
}
此时我们再次执行cargo test运行测试!可预见的ok_test肯定是OK的,fail_test我们在里面写了panic!测试失败!
xxxxxx@xxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.13s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 2 tests
test tests::ok_test ... ok
test tests::fail_test ... FAILED
failures:
---- tests::fail_test stdout ----
thread 'tests::fail_test' panicked at 'Make this test fail', src/lib.rs:11:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::fail_test
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
测试信息输出非常明显,测试失败的位置提示很明确。
三. 测试相关的宏和函数
下面我们介绍一些我们在编写测试时会使用到的相关宏和方法!
3.1. 使用assert!宏检查结果
assert!宏由标准库提供,它可以确保测试中某些条件的值是true。assert!宏可以接收一个能够被计算为布尔类型的值作为参数。当这个值为true时,assert!宏什么都不做并正常通过测试。而当值时false时,assert!宏就会调用panic!宏,进而导致测试失败。使用assert!宏可以检查代码是否按照我们预期的方式运行。
#[derive(Debug)]
pub struct Rectangle {
length: u32,
width: u32,
}
impl Rectangle {
pub fn can_hold(&self, other: &Rectangle) -> bool {
self.length > other.length && self.width > other.width
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle { length: 9, width: 7 };
let smaller = Rectangle { length: 5, width: 1 };
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle { length: 9, width: 7 };
let smaller = Rectangle { length: 5, width: 1 };
assert!(smaller.can_hold(&larger)); // fasle, 断言失败
}
}
此时执行cargo test测试代码:一个成功,一个失败。
xxxxx@xxxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.12s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... FAILED
failures:
---- tests::smaller_cannot_hold_larger stdout ----
thread 'tests::smaller_cannot_hold_larger' panicked at 'assertion failed: smaller.can_hold(&larger)', src/lib.rs:29:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::smaller_cannot_hold_larger
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
3.2. 使用assert_eq!宏和assert_ne!宏判断相等性
在对功能进行测试时,我们常常需要将被测试代码的结果与我们所期望的结果相比较,并检查它们是否相等。在标准库中提供了一对可以简化编程的宏:assert_eq!和assert_ne!。这两个宏分别用于比较并断言两个参数相等或不相等。在断言失败时,它们还可以自动打印出两个参数的值,从而方便我们观察测试失败的原因;相反,使用assert!宏则只能得知==判断表达式失败的事实,而无法知晓用于比较的值。
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ok_adds_two_eq() {
// 断言结果相同测试通过
assert_eq!(4, add_two(2));
}
#[test]
fn fail_adds_two_eq() {
// 断言结果不相同触发panic
assert_eq!(5, add_two(2));
}
#[test]
fn ok_adds_two_ne() {
// 断言结果不一致测试通过
assert_ne!(5, add_two(2));
}
#[test]
fn fail_adds_two_ne() {
// 断言结果相同触发panic
assert_ne!(4, add_two(2));
}
}
执行测试代码:
yuelong@yuelongdeMBP adder % cargo test
Compiling adder v0.1.0 (/Users/yuelong/CodeHome/TestProject/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.12s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 4 tests
test tests::ok_adds_two_ne ... ok
test tests::ok_adds_two_eq ... ok
test tests::fail_adds_two_eq ... FAILED
test tests::fail_adds_two_ne ... FAILED
failures:
---- tests::fail_adds_two_eq stdout ----
thread 'tests::fail_adds_two_eq' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `4`', src/lib.rs:16:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
---- tests::fail_adds_two_ne stdout ----
thread 'tests::fail_adds_two_ne' panicked at 'assertion failed: `(left != right)`
left: `4`,
right: `4`', src/lib.rs:26:9
failures:
tests::fail_adds_two_eq
tests::fail_adds_two_ne
test result: FAILED. 2 passed; 2 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
测试顺利通过检查。
3.3. 添加自定义的错误提示信息
我们也可以添加自定义的错误提示信息,将其作为可选的参数传入assert!、assert_eq!和assert_ne!宏。实际上面任何在assert!、assert_eq!和assert_ne!的必要参数之后出现的参数都会一起被传递给format!宏。因此,你甚至可以将一个包含{}占位符的格式化字符串及相对应的填充值作为参数一起传递给这个宏。自定义的错误提示信息可以很方便地记录当前断言的含义;这样在测试失败时,我们就可以更容易的知道代码到底出了什么问题。
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_test() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{}`", result
)
}
}
当测试失败之后:
running 1 test
test tests::greeting_test ... FAILED
failures:
---- tests::greeting_test stdout ----
thread 'tests::greeting_test' panicked at 'Greeting did not contain name, value was `Hello!`', src/lib.rs:16:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_test
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
这次的测试输出中包含了实际的值,他能帮助我们观察程序真正发生的行为,并迅速定位与预期产生差异的地方。
3.4. 使用should_panic检查paninc
除了检查代码是否返回了正确的结果,确认代码能否按照预期处理错误状态同样重要。
pub struct Guess {
value: u32,
}
impl Guess {
pub fn new(value: u32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
pub fn new_plus(value: u32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn new_test() {
// 此时肯定会发生错误, 但是因为加了should_panic宏,所有测试通过
Guess::new(200);
}
#[test]
#[should_panic]
fn new_plus_test() {
// 此时不会发生错误, 但是因为加了should_panic宏,所有测试无法通过
Guess::new(200);
}
}
执行cargo test并不会失败:
running 2 tests
test tests::new_plus_test - should panic ... FAILED
test tests::new_test - should panic ... ok
failures:
---- tests::new_plus_test stdout ----
note: test did not panic as expected
failures:
tests::new_plus_test
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
使用should_panic进行的测试可能会有些模糊不清,因为他们仅仅能够说明被检查的代码会发生panic。即便函数发生panic的原因和我们预期的不同,使用should_panic进行测试也会顺利通过。为了让should_panic测试更加精确一些,我们可以在should_panic属性中添加可选参数expected。它会检查panic发生时输出的错误提示信息是否包含了指定的文字。例子:
pub struct Guess {
value: u32,
}
impl Guess {
pub fn new(value: u32) -> Guess {
if value < 1 {
panic!("Guess value must be greater than or equal to 1, got {}.", value);
} else if value > 100 {
panic!("Guess value must be less than or equal to 100, got {}.", value);
} else {
Guess { value }
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "Guess value must be less than or equal to 100")]
fn new_test() {
// 此时肯定会发生错误
Guess::new(0);
}
}
此时再次执行测试:
running 1 test
test tests::new_test - should panic ... FAILED
failures:
---- tests::new_test stdout ----
thread 'tests::new_test' panicked at 'Guess value must be greater than or equal to 1, got 0.', src/lib.rs:8:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Guess value must be greater than or equal to 1, got 0."`,
expected substring: `"Guess value must be less than or equal to 100"`
failures:
tests::new_test
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
3.5. 使用Result<T, E>编写测试
到目前为止,我们编写的测试都会在运行失败时触发panic。不过我们也可以用Result<T, E>来编写测试!例子:
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}
在函数体中,我们不再调用assert_eq!宏,而是在测试的时候通过时返回Ok(()),在失败时返回一个带有String的Err值。
不要在使用Reuslt<T, E>编写的测试上标注#[should_panic]。在测试失败时,我们应该直接返回一个Err值。
四. 控制测试的运行方式
如同cargo run会编译代码并运行生成的二进制文件一样,cargo test同样会在测试环境下编译代码,并运行生成的测试二进制文件。你可以通过指定命令行参数来改变cargo test的默认行为。
cargo test --help // 查看cargo test的可用参数 cargo test -- --help // 显示出所有可用在 -- 之后的参数
4.1. 并行或串行的进行测试
当我们尝试运行多个测试,Rust会默认使用多线程来执行它们。这样可以让测试更快地运行完毕。从来尽早得到代码是否可以正常工作的反馈。但是由于测试是同时进行的,所以开发者必须保证测试之间不会互相依赖,或者依赖到同一个共享的状态或环境上,例如当前工作目录、环境变量等。
如果你不想必行运行测试,或者希望精确的控制测试时所启动的线程数量,那么可以通过给测试二进制文件传入 —test-threads标记及期望的具体线程数量来控制这一行为。
cargo test -- --test-threads=1 // 将线程数量控制为1,这也意味着程序不会使用任何并行操作,使用单线程执行测试会比并行话费更多的时间,但是顺序执行不会再因为共享状态而出现可能的干扰情形了
4.2. 显示函数输出
默认情况下,Rust的测试库会在测试通过时捕获所有被打印至标准输出中的消息。当我们测试通过,它所打印的内容就无法显示在终端上;我们只能看到一条用于指明测试通过的消息。只有在测试失败时,我么你才能在错误提示信息的上方观察到打印至标准输出中的内容。例子:
pub fn add(x: i32, y: i32) -> i32 {
println!("x => {}, y => {}", x, y); // @1
x + y
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test() {
assert_eq!(4, add(2, 2))
}
}
我们希望在测试通过时也将值打印出来,那么可以传入—nocapture标记来禁用输出截获功能,执行下面的命令比较输出结果:
cargo test -- --nocapture // 会将@1也输出显示 cargo test // 没有输出@1
4.3. 只运行部分特定名称的测试
执行全部的测试用例有时会花费很长时间。而在编写某个特定部分的代码时,你也许只需要运行和代码相对应地那部分测试。我们可以通过cargo test中传递测试名称来指定需要运行的测试。例子:
pub fn add(x: i32, y: i32) -> i32 {
println!("x => {}, y => {}", x, y);
x + y
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test() {
assert_eq!(4, add(2, 2))
}
#[test]
fn new_test_1() {
assert_eq!(5, add(2, 2))
}
#[test]
fn test_1() {
assert_eq!(6, add(2, 2))
}
}
这时我们可以指定测试名称进行单独测试:
cargo test new_test_1
另外我们可以使用名称过滤运行多个测试:
cargo test new // 此时就会匹配到 new_test 和 new_test_1这两个测试
4.4. 通过显示指定来忽略某些测试
有时,一些特定的测试执行起来会非常耗时,所有你可能会想要在大部分的cargo test命令中忽略它们。除了手动将想要运行的测试列举出来,我们也可以使用ignore属性来标记这些耗时的测试,将这些测试排除在正常的测试运行之外。
pub fn add(x: i32, y: i32) -> i32 {
println!("x => {}, y => {}", x, y);
x + y
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test_1() {
assert_eq!(5, add(2, 2))
}
#[test]
#[ignore]
fn test_1() {
assert_eq!(6, add(2, 2))
}
}
此时我们执行cargo test时就可以很明显的看到ignored的标识:
xxxxxx@xxxxxxx adder % cargo test
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 3 tests
test tests::test_1 ... ignored
test tests::new_test ... ok
test tests::new_test_1 ... FAILED
此时我们也可以使用cargo test —- —-ignored来单独运行这些被忽略的测试。
xxxxx@xxxxxx adder % cargo test -- --ignored
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 1 test
test tests::test_1 ... FAILED
failures:
---- tests::test_1 stdout ----
五. 测试的组织结构
Rust社区主要从以下两个分类来讨论测试:单元测试(unit test)和集成测试(integration test)。单元测试小而专注,每次只单独测试一个模块或私有接口。而集成测试完全位于代码库之外,和正常从外部调用代码一样使用外部代码,只能访问公共接口,而且再一次测试中可能会联用多个模块。
5.1. 单元测试
单元测试的目的在于将一小段代码单独隔离出来,从而迅速确定这段代码的功能是否符合预期。我们一般将单元测试与需要测试的代码存放在src目录下的同一文件中。同时也约定俗称地在每个源代码文件中都新建一个tests模块来存放测试函数,并使用cfg(test)对该模块进行标注。
在tests模块上标注#[cfg(test)]可以让Rust只在执行cargo test命令时编译和运行该部分测试代码,而在执行cargo build时剔除它们。这样就可以在正常编译时不包含测试代码,从而节省编译时间和产出物所占用的空间。我们不需要对集成测试标注#[cfg(test)],因此集成测试本省就放置在独立的目录中。但是,由于本身测试是和业务代码并列放置在同一文件中,所有我们必须使用#[cfg(test)]进行标注才能将单元测试的代码排除在编译产出物之外。Rust是允许测试私有函数,例子:
// 共有函数
pub fn add(x: i32, y: i32) -> i32 { x + y }
// 私有函数
fn sub(x: i32, y: i32) -> i32 { x - y }
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_test() {
assert_eq!(4, add(2, 2))
}
#[test]
fn sub_test() {
assert_eq!(0, sub(2, 2))
}
}
5.2. 集成测试
在Rust中,集成测试是完全位于代码库之外的。集成个测试调用库的方式和其他的代码调用方式没有任何不同,这也意味着你只能调用对外公开提供的那部分接口。集成测试的目的在于验证库的不同部分能否协同起来工作。能够独立对外公开提供的那部分接口。集成测试的目的在于验证库的不同部分能否协同起来正常工作。能够独立正常工作的单元代码的集成运行时也会发生各种问题,所有集成测试的覆盖同样是非常重要的。
为了创建集成测试,我们需要首先建立一个tests目录。tests是文件夹和src文件夹并列。Cargo会自动在这个目录下寻找集成测试文件。在这个目录下创建任意多个测试文件,Cargo在编译时会将每个文件都处理为一个独立的包。
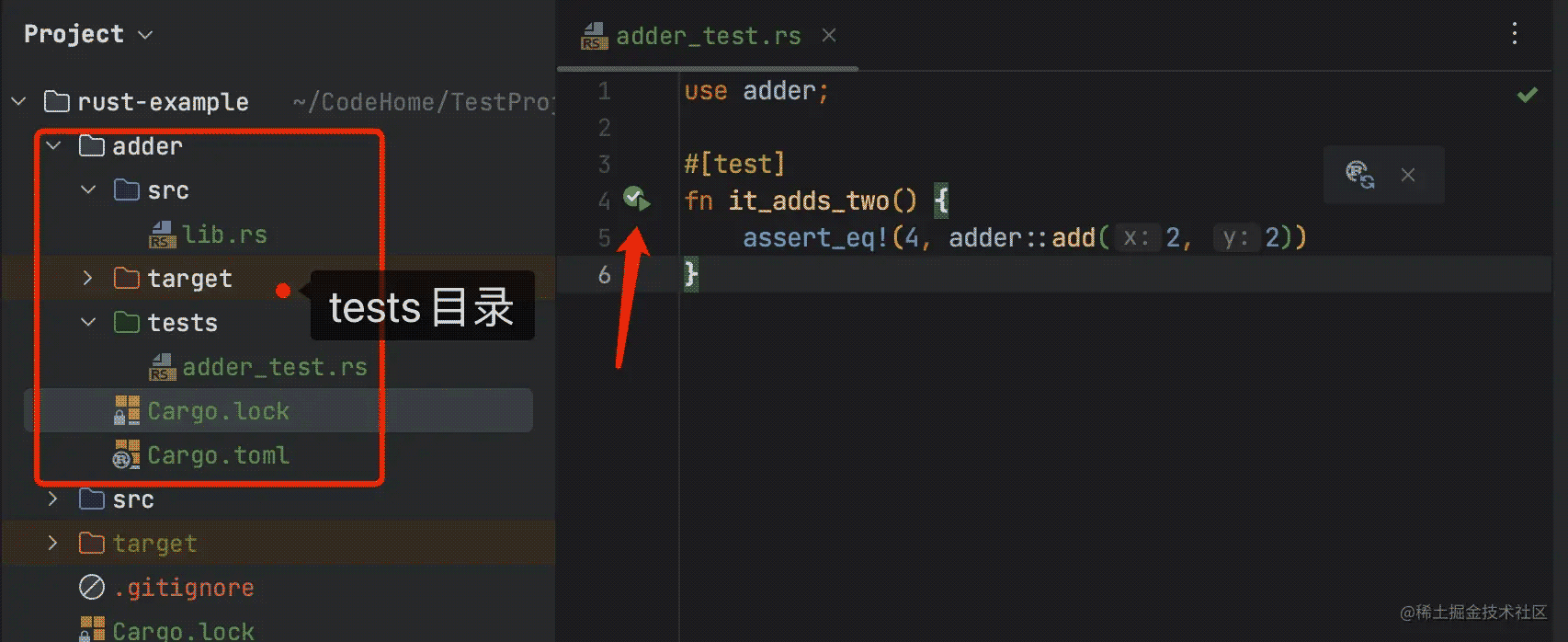
我们在执行cargo test
xxxxxx@xxxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.15s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 1 test
test tests::add_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/adder_test.rs (target/debug/deps/adder_test-4bc3058753e422c8). // 执行集成测试
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
如果此时有多个测试函数,我们可以指定函数名,单独运行特定的集成测试函数:
cargo test --test add_test
随着集成测试增加,我们可以把tests目录下的代码分离到多个文件中。将每个集成测试的文件编译成独立的包有助于隔离作用域,并使集成测试环境更加贴近于用户的使用场景。
但是在tests目录中添加模块并不是简单的添加一个文件,如图:
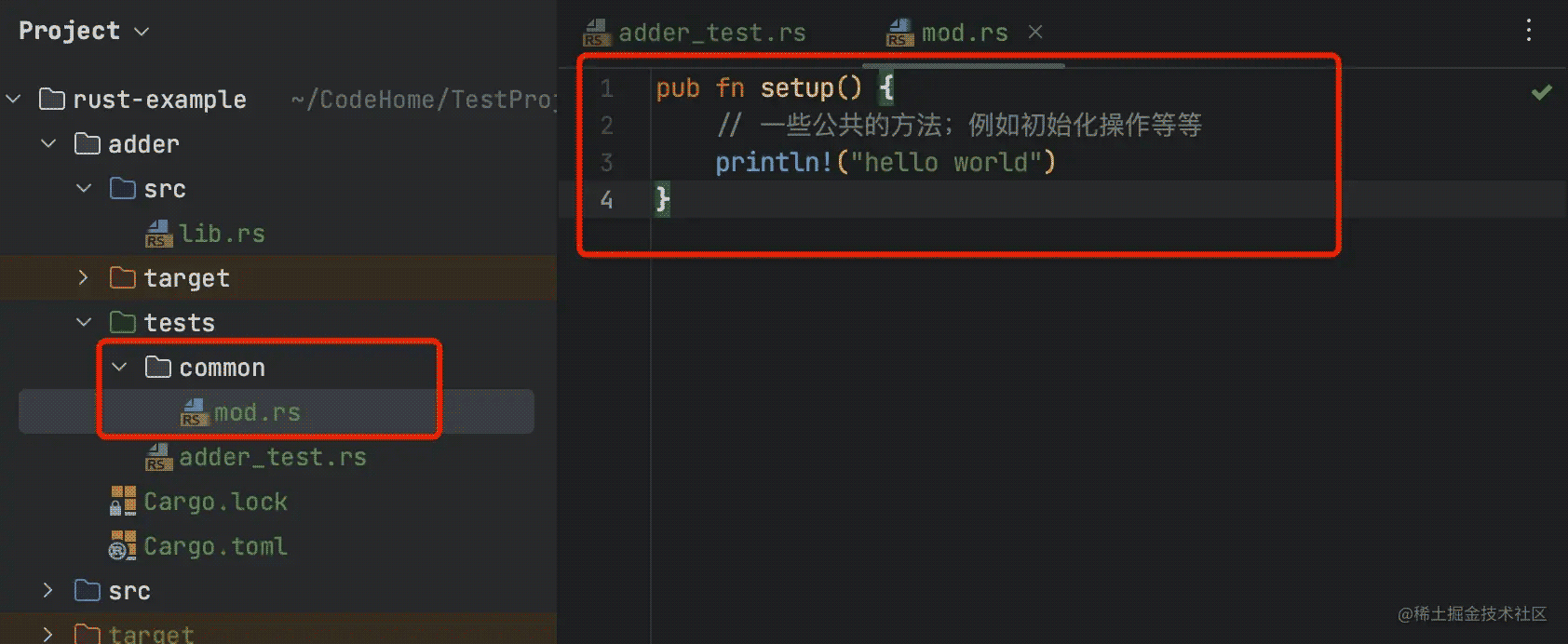
接着我们就可以在测试函数中引用了
mod common; // 引入模块
use adder;
#[test]
fn it_adds_two() {
common::setup(); // 调用
assert_eq!(4, adder::add(2, 2))
}
最后需要注意一点,如果我们的项目是一个只有src/main.rs文件而没有src/lib.rs文件的二进制包,那么我们就无法在tests目录中创建集成测试,也无法使用过use将src/main.rs中定义的函数导入作用域。只有代码包(library crate)才可以将函数暴露给其他包调用,而二进制包只被用于独立执行。
以上就是Rust编写自动化测试实例权威指南的详细内容,更多关于Rust编写自动化测试的资料请关注我们其它相关文章!
相关推荐
-
Rust Atomics and Locks 源码解读
目录 正文 load 和 store 使用 AtomicBool实现通知线程停止的案例 正文 在 Rust 中,原子性操作是指在多线程并发环境下对共享数据进行操作时,保证操作的原子性,即不会出现数据竞争等问题.Rust 提供了原子类型和原子操作来支持多线程并发编程. Rust 的原子类型包括 AtomicBool.AtomicIsize.AtomicUsize.AtomicPtr 等.这些类型的实现都使用了底层的原子操作指令,保证了它们的读写操作是原子的,不会被其他线程中断. 在 Rust 中,
-
从迷你todo 命令行入门Rust示例详解
目录 一个迷你 todo 应用 需要安装的依赖 文件目录组织 主文件 读取文件 状态处理工厂函数 Trait(特征) Create trait Get trait Delete trait Edit trait 导出 trait 为 struct 实现 trait Pending Done 导出 struct Process 输入处理 最后 一个迷你 todo 应用 该文章将使用 Rust 从零去做一个入门级别的 TODO 命令行应用 你将学会什么? 基本的命令行操作 文件读写和文件结构组织 我
-
Rust Atomics and Locks内存序Memory Ordering详解
目录 Rust内存序 重排序和优化 happens-before Relexed Ordering Release 和 Acquire Ordering SeqCst Ordering Rust内存序 Memory Ordering规定了多线程环境下对共享内存进行操作时的可见性和顺序性,防止了不正确的重排序(Reordering). 重排序和优化 重排序是指编译器或CPU在不改变程序语义的前提下,改变指令的执行顺序.在单线程环境下,重排序可能会带来性能提升,但在多线程环境下,重排序可能会破坏程序
-
Rust Atomics and Locks并发基础理解
目录 Rust 中的线程 线程作用域 所有权共享 借用和数据竞争 内部可变 rust 中的线程安全 Send 和 Sync 线程阻塞和唤醒 Rust 中的线程 在 Rust 中,线程是轻量级的执行单元,可以并行执行多个任务.Rust 中的线程由标准库提供的 std::thread 模块支持,使用线程需要在程序中引入该模块.可以使用 std::thread::spawn() 函数创建一个新线程,该函数需要传递一个闭包作为线程的执行体.闭包中的代码将在新线程中执行,从而实现了并发执行.例如: use
-
Rust 所有权机制原理深入剖析
目录 what's ownership? Scope (作用域) ownership transfer(所有权转移) move clone copy References and Borrowing(引用和借用) Mutable References(可变引用) Dangling References(悬垂引用) what's ownership? 常见的高级语言都有自己的 Garbage Collection(GC)机制来管理程序运行的内存,例如 Java.Go 等.而 Rust 引入了一种全
-
Rust语言从入门到精通系列之Iterator迭代器深入详解
目录 迭代器的基本概念 迭代器是什么? Iterator trait Animal示例 迭代器的常见用法 map方法 filter方法 enumerate方法 flat_map方法 zip方法 fold方法 结论 在Rust语言中,迭代器(Iterator)是一种极为重要的数据类型,它们用于遍历集合中的元素.Rust中的大多数集合类型都可转换为一个迭代器,使它们可以进行遍历,这包括数组.向量.哈希表等. 使用迭代器可以让代码更加简洁优雅,并且可以支持一些强大的操作,例如过滤.映射和折叠等. 在本
-
向Rust学习Go考虑简单字符串插值特性示例解析
目录 fmt.Printf 或 fmt.Sprintf 写拼装字符串业务 简单字符串插值 其他语言例子 Swift Kotlin C Rust 争论矛盾点 总结 fmt.Printf 或 fmt.Sprintf 写拼装字符串业务 在日常开发 Go 工程中,我们经常会用 fmt.Printf 或 fmt.Sprintf 去写类似的拼装字符串的业务. 如下代码: fmt.Printf("Hello Gopher %s, you are %d years old and you're favorite
-

AngularJS 2.0入门权威指南
学习 Angular 2 当越来越多的 web app 使用 Angular 1构建的时候,更快更强大的 Angular 2 将会很快成为新的标准. Angular的新约定使得它更容易去学习.更快的去开发 app.通过本教程学习更快速.更强大的 Angular 版本. Angular 一个跨移动和桌面的框架 快速开始 本指南指导你如何构建一个简单 Angular app. 可以使用typescript/ JavaScript / Dart任意一种语言来编写Angular app,本教程采用Jav
-
详解JavaScript权威指南之对象
JavaScript对象可以看作是属性的无序集合,每个属性就是一个键值对,可增可删. JavaScript中的所有事物都是对象:字符串.数字.数组.日期,等等. JavaScript对象除了可以保持自有的属性外,还可以从一个称为原型的对象继承属性.对象的方法通常是继承的属性.这种"原型式集成"是JavaScript的的核心特征. 1.创建对象 第一种:对象直接量表示法创建对象. 这是最简单的对象创建方式,对象直接量由若干key:value键值对属性组成,属性之间用逗号分隔,整个对象用花
-
使用python+poco+夜神模拟器进行自动化测试实例
网易最近出的一款自动化UI测试工具:Airtest 挺火的,还受到谷歌的推荐.我试着用了一下,感觉优缺点还是蛮明显的.对初学者来说,能用到的也就是图像识别的功能,这块做得比老牌的按键精灵弱很多.不过Airtest集合了poco框架对熟悉python的同学来说,是个进行自动化测试的利器. 我用了一段时间Airtest以后,发现其实我完全可以丢开Airtest,我需要的是poco框架提供的unity3d控件读取,Airtest在其中只起到了一个pythonIDE的作用.自动化跑py脚本时,还要打开A
-
python+flask编写接口实例详解
环境:Pycharm :其他环境:安装Anaconda 最近在做一个小型项目练手,涉及到大量的IP和相关数据处理,所以选用了Python来处理数据,但是处理完怎么给前端调用呢,今天这篇就是在Python方便地处理完数据后以接口形式把数据返回给前端. flask就是使用Python编写接口实例的关键库,先配置项目: ①(这一步可以使用Python默认解释器,但是后续安装库可能还需要配置,建议使用Anaconda)首先打开PyCharm,在file->settings->Project->p
-
React中编写CSS实例详解
目录 正文 内联样式 普通的CSS css modules css in js 样式组件 引入外部变量 默认值 引入全局样式 provider 样式继承 动态添加class 正文 目前,前端最流行的开发方式是组件化,而CSS的设计本身就不是为组件化而生的,所以在目前组件化的框架中都在需要一种合适的CSS解决方案 在组件化开发环境下的CSS,应该满足如下需求: 可以编写局部css: css具备自己的具备作用域,不会随意污染其他组件内的元素 可以编写动态的css: 可以获取当前组件的一些状态,根据状
-
利用Rust编写一个简单的字符串时钟
目录 1.简介 2.用到的知识点 2.1 取utc时间 2.2 图片变换为像素图案 2.3 字符方式显示当前时间 2.4 时间刷新 1.简介 用rust写的一个简单的练手的demo,一个字符串时钟,在终端用字符串方式显示当前时间.本质是对图片取灰度,然后每个像素按灰度门限用星号代替灰度值,就把图片变为由星号组成的字符型图案.把时间字符串的每个字符按照字母和数字图片的样式转换为字符,然后拼接字符图案就实现了字符时钟的效果. 主要用到的知识有:rust操作时间.字符串.vector,字符串和vect
-
Python + Requests + Unittest接口自动化测试实例分析
本文实例讲述了Python + Requests + Unittest接口自动化测试.分享给大家供大家参考,具体如下: 1. 介绍下python的requests模块 Python Requests快速入门 :http://cn.python-requests.org/zh_CN/latest/ 想必会Python基础的小伙伴们一看就懂了 2. Requests接口自动化测试: 2.1 如何利用这么利器进行接口测试,请看小demo: # -*- coding:utf-8 -* import re
-
Yii扩展组件编写方法实例分析
本文实例讲述了Yii扩展组件编写方法.分享给大家供大家参考.具体如下: 因为Yii本身就引入了Prado的component-based 思想做为主要思想.因此,组件在yii中是很重要的. 组件一般放在components目录里,其格式示例基本如下: <?php /** * some description about the <span style="color: rgb(34, 34, 34); font-family: Arial, sans-serif; font-size:
-
在Windows中安装Apache2和PHP4的权威指南
Apache 2和PHP是创建交互式网站的流行方案,而且成本很低.在Windows中安装Apache 2是一件轻而易举的事情,但要使PHP 4与Apache 2配合无间地运行,就需要一定的技巧. 转自:动态网制作指南 www.knowsky.com 在PHP 4.3手册的Windows安装小节,没有解释如何让PHP与Apache 2配合使用,而有关Apache 2安装的小节缺失了你需要的大量信息.在网上公布的其他安装指南中,也包含了不少错误,使一些安装人员只好不断试验和犯错.例如,有些人甚至将P
-
python自动化测试实例解析
本文实例讲述了python自动化测试的过程,分享给大家供大家参考. 具体代码如下: import unittest ######################################################################## class RomanNumeralConverter(object): """converter the Roman Number""" #-----------------------