ElasticSearch写入流程实例解析
目录
- 一、前言
- 二、lucence写
- 2.1 增删改
- 2.2. 并发模型
- 2.2.1. 基本操作
- 2.2.2 更新
- 2.2.3 删除
- 2.2.4 flush和commit
- 2.2.5 merge
- 小结
- 三、 ElasticSearch的写
- 3.1. 宏观看ElasticSearch请求
- 3.2. 详细流程
- 3.2.1 协调节点内部流程
- 3.2.2 主分片节点流程*
- 3.2.3 副本分片节点流程8
- 四、总结
一、前言
介绍我们在前面已经知道ElasticSearch底层的写入是基于lucence依进行doc写入的。ElasticSearch作为一款分布式系统,在写入数据时还需要考虑很多重要的事项,比如:可靠性、原子性、一致性、实时性、隔离性、性能等多个指标。
ElasticSearch是如何做到的呢?下面我们针对ElasticSearch的写入进行分析。
二、lucence写
2.1 增删改
ElasticSearch拿到一个doc后调用lucence的api进行写入的。
public long addDocument(); public long updateDocuments(); public long deleteDocuments();
如上面的代码所示,我们使用lucence的上面的接口就可以完成文档的增删改操作。在lucence中有一个核心的类IndexWriter负责数据写入和索引相关的工作。
//1. 初始化indexwriter对象
IndexWriter writer = new IndexWriter(new Directory(Paths.get("/index")), new IndexWriterConfig());
//2. 创建文档
Document doc = new Document();
doc.add(new StringField("empName", "王某某", Field.Store.YES));
doc.add(new TextField("content", "操作了某菜单", Field.Store.YES));
//3. 添加文档
writer.addDocument(doc);
//4. 提交
writer.commit();
以上代码演示了最基础的lucence的写入操作,主要涉及到几个关键点: 初始化: Directory是负责持久化的,他的具体实现有很多,有本地文件系统、数据库、分布式文件系统等待,ElasticSearch默认的实现是本地文件系统。 Document: Document就是es中的文档,FiledType定义了很多索引类型。这里列举几个常见的类型:
- stored: 字段原始内容存储
- indexOptions:(NONE/DOCS/DOCS_AND_FREQS/DOCS_AND_FREQS_AND_POSITIONS/DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS),倒排索引的选项,存储词频、位置信息等。
- docValuesType: 正排索引,建立一个docid到field的的一个列存储。
- 一些其它的类型
IndexWriter:IndexWriter在doc进行commit后,才会被持久化并且是可搜索的。IndexWriterConfig:IndexWriterConfig负责了一些整体的配置参数,并提供了方便使用者进行功能定制的参数:
- Similarity: 这个是搜索的核心参数,实现了这个接口就能够进行自定义算分。lucence默认实现了前面文章提到的TF-IDF、BM25算法。
- MergePolicy: 合并的策略。我们知道ElasticSearch会进行合并,从而减少段的数量。
- IndexerThreadPool: 线程池的管理。
- FlushPolicy: flush的策略。
- Analyzer: 定制分词器。
- IndexDeletionPolicy: 提交管理。
PS:在ElasticSearch中,为了支持分布式的功能,新增了一些系统默认字段:
- _uid,主键,在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值。
- _version,版本字段,version来保证对文档的变更正确的执行,更新文档时有用。
- _source,原始信息,如果后面维护不需要reindex索引可以关闭该字段,从而节省空间
- _routiong,路由字段。
- 其它的字段
2.2. 并发模型
上面我们知道indexwriter负责了ElasticSearch索引增删改查。那它具体是如何管理的呢?

2.2.1. 基本操作
关键点:
- DocumentsWriter处理写请求,并分配具体的线程DocumentsWriterPerThread
- DocumentsWriterPerThread具有独立内存空间,对文档进行处理DocumentsWriter触发一些flush的操作。
- DocumentsWriterPerThread中的内存In-memory buffer会被flush成独立的segement文件。
- 对于这种设计,多线程的写入,针对纯新增文档的场景,所有数据都不会有冲突,非常适合隔离的数据写入方式
2.2.2 更新
Lucene的update和数据库的update不太一样,Lucene的更新是查询后删除再新增。
- 分配一个操作线程
- 在线程里执行删除
- 在线程里执行新增
2.2.3 删除

上面已经说了,在update中会删除,普通的也会删除,lucence维护了一个全局的删除表,每个线程也会维护一个删除表,他们双向同步数据
- update的删除会先在内部记录删除的数据,然后同步到全局表中。
- delete的删除会作用在Global级别,后异步同步到线程中。
- Lucene Segment内部,数据实际上其实并不会被真正删除,Segment内部会维持一个文件记录,哪些是docid是删除的,在merge时,相应的doc文档会被真正的删除。
2.2.4 flush和commit
每一个WriterPerThread线程会根据flush策略将文档形成segment文件,此时segment的文件还是不可见的,需要indexWriter进行commit后才能被搜索。 这里需要注意:ElasticSearch的refresh对应于lucene的flush,ElasticSearch的flush对应于lucene的commit,ElasticSearch在refresh时通过其它方式使得segment变得可读。
2.2.5 merge
merge是对segment文件合并的动作,这样可以提升查询的效率并且可以真正的删除的文档。
小结
在这里我们稍微总结一下,一个ElasticSearch索引的一个分片对应一个完整的lucene索引, 而一个lucene索引对应多个segment。我们在构建同一个lucene索引的时候, 可能有多个线程在并发构建同一个lucene索引, 这个时候每个线程会对应一个DocumentsWriterPerThread, 而每个 DocumentsWriterPerThread会对应一个index buffer. 在执行了flush以后, 一个 DocumentsWriterPerThread会生成一个segment。
三、 ElasticSearch的写
3.1. 宏观看ElasticSearch请求
在前面的文章已经讨论了写入的流程ElasticSearch
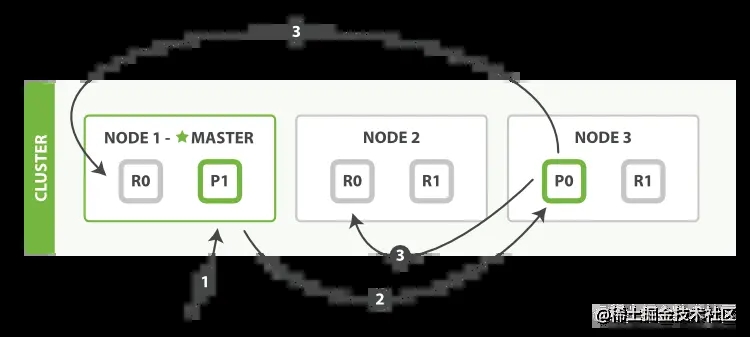
图片来自官网 当写入文档的时候,根据routing规则,会将文档发送至特定的Shard中建立lucence。
- 介绍在Primary Shard上执行成功后,再从Primary Shard上将请求同时发送给多个Replica Shardgit
- 请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功,返回结果给客户端
注意上面的写入延时=主分片延时+max(Replicas Write),即写入性能如果有副本分片在,就至少是写入两个分片的延时延时之和。
3.2. 详细流程
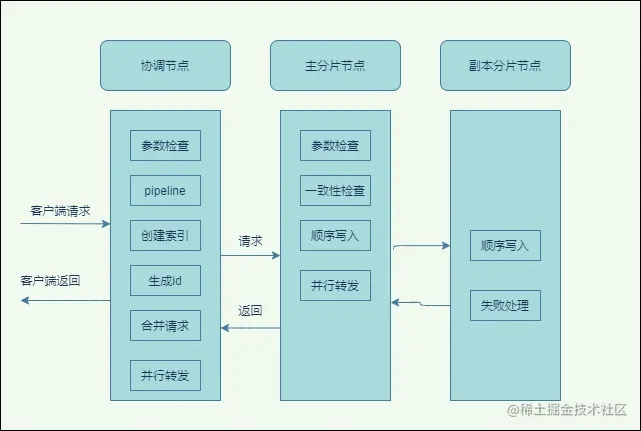
3.2.1 协调节点内部流程
如上图所示:
- 协调节点会对请求检查放在第一位,如果如果有问题就直接拒绝。主要有长度校验、必传参数、类型、版本、id等等。
- pipeline,用户可以自定义设置处理器,比如可以对字段切割或者新增字段,还支持一些脚本语言,可以查看官方文档编写。
- 如果允许自动创建索引(默认是允许的),会先创建索引,创建索引会发送到主节点上,必须等待master成功响应后,才会进入下一流程。
- 请求预处理,比如是否会自动生成id、路由,获取到整个集群的信息了,并检查集群状态,比如集群master不存在,都会被拒绝。
- 构建sharding请求,比如这一批有5个文档, 如果都是属于同一个分片的,那么就会合并到一个请求里,会根据路由算法将文档分类放到一个map里 Map> requestsByShard = new HashMap<>();路由算法默认是文档id%分片数。
- 转发请求,有了分片会根据前面的集群状态来确定具体的ElasticSearch节点ip,然后并行去请求它们。
3.2.2 主分片节点流程*
写入(index)

该部分是elasticsarch的核心写入流程,在前面的文章也介绍了,请求到该节点会最终调用lucence的方法,建立lucence索引。其中主要的关键点:
- ElasticSearch节点接收index请求,存入index buffer,同步存入磁盘translog后返回索引结果
- Refresh定时将lucence数据生成segment,存入到操作系统缓存,此时没有fsync,清空lucence,此时就可以被ElasticSearch查询了,如果index buffer占满时,也会触发refresh,默认为jvm的10%。
- Flush定时将缓存中的segments写入到磁盘,删除translog。如果translog满时(512m),也会触发flush。
- 如果数据很多,segment的也很多,同时也可能由删除的文档,ElasticSearch会定期将它们合并。
update

- 读取同id的完整Doc, 记录版本为version1。
- 将version1的doc和update请求的Doc合并成一个Doc,更新内存中的VersionMap。获取到完整Doc后。进入后续的操作。
- 后面的操作会加锁。
- 第二次从versionMap中读取该doc的的最大版本号version2,这里基本都会从versionMap中获取到。
- 检查版本是否冲突,判断版本是否一致(冲突),如果发生冲突,则回到第一步,重新执行查询doc合并操作。如果不冲突,则执行最新的添加doc请求。
- 介绍在add Doc时,首先将Version + 1得到V3,再将Doc加入到Lucene中去,Lucene中会先删同id下的已存在doc id,然后再增加新Doc。写入Lucene成功后,将当前V3更新到versionMap中。
- 释放锁,更新流程就结束了。
介绍其实就是乐观锁的机制,每次更新一次版本号加 1 ,不像关系式数据库有事物,你在更新数据,可能别人也在更新的话,就把你的给覆盖了。你要更新的时候,先查询出来,记住版本号,在更新的时候最新的版本号和你查询的时候不一样,说明别人先更新了。你应该读取最新的数据之后再更新。写成功后,会转发写副本分片,等待响应,并最后返回数据给协调节点。具体的流程:
- 校验,校验写的分片是否存在、索引的状态是否正常等等。
- 是否需要延迟执行,如果是则会放入到队列里等待。
- 校验活跃的分片数是否存在,不足则拒绝写入。
public boolean enoughShardsActive(final int activeShardCount) {
if (this.value < 0) {
throw new IllegalStateException("not enough information to resolve to shard count");
}
if (activeShardCount < 0) {
throw new IllegalArgumentException("activeShardCount cannot be negative");
}
return this.value <= activeShardCount;
}
为什么会要校验这个活跃的分片数呢?
- ElasticSearch的索引层有个一waitforactiveshards参数代表写入的时候必须的分片数,默认是1。如果一个索引是每个分片3个副本的话,那么一共有4个分片,请求时至少需要校验存活的分片数至少为1,相当于提前校验了。如果对数据的可靠性要求很高,就可以调高这个值,必须要达到这个数量才会写入。
- 调用lucence写入doc.
- 写入translog日志。
- 写入副本分片,循环处理副本请求,会传递一些信息。在这里需要注意,它们是异步发送到副本分片上的,并且需要全部等待响应结果,直至超时。
- 接着上一步,如果有副本分片失败的情况,会把这个失败的分片发送给master,master会更新集群状态,这个副本分片会从可分配列表中移除。
发送请求至副本
@Override
public void tryAction(ActionListener<ReplicaResponse> listener) {
replicasProxy.performOn(shard, replicaRequest, primaryTerm, globalCheckpoint, maxSeqNoOfUpdatesOrDeletes, listener);
}
等待结果
privatevoid decPendingAndFinishIfNeeded() {
assert pendingActions.get() > 0 : "pending action count goes below 0 for request [" + request + "]";
if (pendingActions.decrementAndGet() == 0) {
finish();
}
}
在以前的版本中,其实是异步请求副本分片的,后来觉得丢失数据的风险很大,就改成同步发送了,即Primary等Replica返回后再返回给客户端。如果副本有写入失败的,ElasticSearch会进行一些重试,但最终并不强求一定要在多少个节点写入成功。在返回的结果中,会包含数据在多少个shard中写入成功了,多少个失败了,如果有副本上传失败,会将失败的副本上报至Master。
PS:ElasticSearch的数据副本模型和kafka副本很相似,都是采用的是ISR机制。即:ES里面有一个:in-sync copies概念,主分片会在索引的时候会同步数据至in-sync copies里面所有的节点,然后再返回ACK给client。而in-sync copies里面的节点是动态变化的,如果出现极端情况,在in-sync copies列表中只有主分片一个的话,这里很容易出现SPOF问题,这个是在ElasticSearch中是如何解决的呢?
就是依靠上面我们分析的wait_for_active_shards参数来防止SPOF,如果配置index的wait_for_active_shards=3就会提前校验必须要有三个活跃的分片才会进行同步,否则拒绝请求。对于可靠性要求高的索引可以提升这个值。
PS:为什么是先写lucence再写入translog呢,这是因为写入lucence写入时会有数据检查,有可能会写入失败,这个是发生在内存之中的,如果先写入磁盘的translog的话,还需要回退日志,比较麻烦
3.2.3 副本分片节点流程8
这个过程和主分片节点的流程基本一样,有些校验可能略微不同,最终都会写入lucence索引。
四、总结
本文介绍了ElasticSearch的写入流程和一些比较详细的机制,最后我们总结下开头我们提出的问题,一个分布式系统需要满足很多特性,大部分特性都能够在ElasticSearch中得到满足。
- 可靠性:lucence只是个工具,ElasticSearch中通过自己设计的副本来保证了节点的容错,通过translog日志保证宕机后能够恢复。通过这两套机制提供了可靠性保障。
- 一致性:ElasticSearch实现的是最终一致性,副本和主分片在同一时刻读取的数据可能不一致。比如副本的refresh频率和主分片的频率可能不一样。
- 高性能:ElasticSearch通过多种手段来提升性能,具体包括:
- lucence自身独立线程维护各自的Segment,多线程需要竞争的资源更少,性能更好。
- update等操作使用versionMap缓存,减少io.
- refresh至操作系统缓存。
- 原子性、隔离性:使用版本的乐观锁机制保证的。
- 实时性:ElasticSearch设计的是近实时的,如果同步进行refresh、flush将大幅降低性能,所以是”攒一部分数据“再刷入磁盘,不过实时写入的tranlog日志还是可以实时通过id查到的。
以上就是ElasticSearch写入流程实例解析的详细内容,更多关于ElasticSearch写入流程的资料请关注我们其它相关文章!
相关推荐
-
Elasticsearch写入瓶颈导致skywalking大盘空白
目录 前言 问题定位 THREAD-B,找出当前阻塞其他线程的线程 解决方案 临时方案,SKYWALKING参数调优 最终方案-优化ES的写入性能 结语 前言 继上次skywalking出故障<解析Arthas协助排查线上skywalking不可用问题>不到一个月,线上skywalking又出毛病了.又是大盘空白,trace列表最近的数据都查询不出来,但是时间稍久的数据就能查询出来,如一天前的数据有,一个小时前的数据就没有,这个只是表象,最终查明症结是ES的服务写入瓶颈,导致写入写入数据的线程
-
elasticsearch索引index之put mapping的设置分析
目录 mapping的设置过程 put mapping updateTask响应 总结 mapping的设置过程 mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设置,也可以在后期设置. 后期设置可以是修改mapping(无法对已有的field属性进行修改,一般来说只是增加新的field)或者对没有mapping的索引设置mapping. put mapping操作必须是master节点来完成,因为它涉及到集群mate
-
elasticsearch索引创建create index集群matedata更新
目录 创建索引更新集群index matedata 首先创建index的create方法 从indice中获取对应的IndexService 总结 创建索引更新集群index matedata 创建索引需要创建索引并且更新集群index matedata,这一过程在MetaDataCreateIndexService的createIndex方法中完成.这里会提交一个高优先级,AckedClusterStateUpdateTask类型的task.索引创建需要即时得到反馈,异常这个task需要返回,
-
Python如何把Spark数据写入ElasticSearch
这里以将Apache的日志写入到ElasticSearch为例,来演示一下如何使用Python将Spark数据导入到ES中. 实际工作中,由于数据与使用框架或技术的复杂性,数据的写入变得比较复杂,在这里我们简单演示一下. 如果使用Scala或Java的话,Spark提供自带了支持写入ES的支持库,但Python不支持.所以首先你需要去这里下载依赖的ES官方开发的依赖包包. 下载完成后,放在本地目录,以下面命令方式启动pyspark: pyspark --jars elasticsearch-ha
-

RediSearch加RedisJSON大于Elasticsearch的搜索存储引擎
目录 RedisMod简介 安装 RediSearch 对比Elasticsearch 索引能力 查询能力 总结 RedisMod简介 Redis是开发中非常常用的内存数据存储中间件,之前基本上用它来做内存存储使用.最近发现Redis推出了很多增强模块,例如通过RedisJSON可以支持原生JSON对象的存储,使用RediSearch可以作为搜索引擎使用,并且支持中文搜索!今天给大家带来RediSearch+RedisJSON作为搜索引擎的使用实践,希望对大家有所帮助! SpringBoot实战
-
python elasticsearch从创建索引到写入数据的全过程
python elasticsearch从创建索引到写入数据 创建索引 from elasticsearch import Elasticsearch es = Elasticsearch('192.168.1.1:9200') mappings = { "mappings": { "type_doc_test": { #type_doc_test为doc_type "properties": { "id": { "
-
ElasticSearch写入流程实例解析
目录 一.前言 二.lucence写 2.1 增删改 2.2. 并发模型 2.2.1. 基本操作 2.2.2 更新 2.2.3 删除 2.2.4 flush和commit 2.2.5 merge 小结 三. ElasticSearch的写 3.1. 宏观看ElasticSearch请求 3.2. 详细流程 3.2.1 协调节点内部流程 3.2.2 主分片节点流程* 3.2.3 副本分片节点流程8 四.总结 一.前言 介绍我们在前面已经知道ElasticSearch底层的写入是基于lucence依
-
MyBatis执行Sql的流程实例解析
这篇文章主要介绍了MyBatis执行Sql的流程实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本博客着重介绍MyBatis执行Sql的流程,关于在执行过程中缓存.动态SQl生成等细节不在本博客中体现,相应内容后面再单独写博客分析吧. 还是以之前的查询作为列子: public class UserDaoTest { private SqlSessionFactory sqlSessionFactory; @Before public v
-
Python之reload流程实例代码解析
本文研究的主要是Python之reload流程的相关内容,具体如下. 在Python中,reload() 用于重新载入之前载入的模块. reload() 函数语法: reload(module) Python中 import 只执行一次,后续的 import 仅仅在 sys.modules 中查找是否存在对应的模块对象,而对于源文件进行修改后想要立即重新导入该文件而不想整体重新执行程序时, reload 就在该处派上用途了.在实际中,测试代码修改结果,或者对于不能停止的服务需要动态改变运行行为
-
Eureka源码阅读解析Server服务端启动流程实例
目录 环境 1.spring cloud整合eureka server demo 1.1 新建spring boot项目 pom.xml文件添加 配置文件 1.2 启动类 1.3 启动 2. spring cloud自动装配eureka server源码解析 2.1 @EnableEurekaServer注解 2.2 EurekaServerAutoConfiguration 2.2.1 查找starter 自动装配类的技巧 2.2.2 EurekaServerAutoConfiguration
-
React源码state计算流程和优先级实例解析
目录 setState执行之后会发生什么 根据组件实例获取其 Fiber 节点 创建update对象 将Update对象关联到Fiber节点的updateQueue属性 发起调度 processUpdateQueue做了什么 变量解释 构造本轮更新的 updateQueue 更新 workInProgress 节点 总结 update对象丢失问题 为什么会丢失 如何解决 state计算的连续性 问题现象 如何解决 setState执行之后会发生什么 setState 执行之后,会执行一个叫 en
-
Java多线程之volatile关键字及内存屏障实例解析
前面一篇文章在介绍Java内存模型的三大特性(原子性.可见性.有序性)时,在可见性和有序性中都提到了volatile关键字,那这篇文章就来介绍volatile关键字的内存语义以及实现其特性的内存屏障. volatile是JVM提供的一种最轻量级的同步机制,因为Java内存模型为volatile定义特殊的访问规则,使其可以实现Java内存模型中的两大特性:可见性和有序性.正因为volatile关键字具有这两大特性,所以我们可以使用volatile关键字解决多线程中的某些同步问题. volatile
-
RocketMQ重试机制及消息幂代码实例解析
这篇文章主要介绍了RocketMQ重试机制及消息幂代码实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.重试机制 1.由于MQ经常处于复杂的分布式系统中,考虑网络波动,服务宕机,程序异常因素,很有可能出现消息发送或者消费失败的问题.因此,消息的重试就是所有MQ中间件必须考虑到的一个关键点.如果没有消息重试,就可能产生消息丢失的问题,可能对系统产生很大的影响.所以,秉承宁可多发消息,也不可丢失消息的原则,大部分MQ都对消息重试提供了很好
-
iOS实现第三方微信登录方式实例解析(最新最全)
项目地址 : https://github.com/zhonggaorong/weixinLoginDemo 最新版本的微信登录实现步骤实现: 1.在进行微信OAuth2.0授权登录接入之前,在微信开放平台注册开发者帐号,并拥有一个已审核通过的移动应用,并获得相应的AppID和AppSecret,申请微信登录且通过审核后,可开始接入流程. 地址: 点击打开链接 2. 下载最新的SDK 地址: 点击打开链接 SDK内容如下: 结构解析: 从上到下依次说明: 1. 静态库,直接拖入工程. 2. re
-
Bootstrap Tree View简单而优雅的树结构组件实例解析
A simple and elegant solution to displaying hierarchical tree structures (i.e. a Tree View) while leveraging the best that Twitter Bootstrap has to offer. 这是Bootstrap Tree View在git上的简介. 注意simple.elegant,简单而优雅,我喜欢这两个词. 那么今天的实例是通过Bootstrap Tree View来制作
-
Python用imghdr模块识别图片格式实例解析
imghdr模块 功能描述:imghdr模块用于识别图片的格式.它通过检测文件的前几个字节,从而判断图片的格式. 唯一一个API imghdr.what(file, h=None) 第一个参数file可以是用rb模式打开的file对象或者表示路径的字符串和PathLike对象.h参数是一段字节串.函数返回表示图片格式的字符串. >>> import imghdr >>> imghdr.what('test.jpg') 'jpeg' 具体的返回值和描述如下: 返回值 描述