Mysql给普通分页查询结果加序号实操
目录
- 一、效果展示
- 1、普通查询加序号
- 2、分页查询加序号
- 二、表结构以及数据
- 三、解释说明
一、效果展示
1、普通查询加序号
SELECT t1.NAME,( @i := @i + 1 ) AS '序号' FROM t1,( SELECT @i := 0 ) AS itable;

这种情况遇上分页时会出现每次翻页都从1开始重新计算,这种情况可以使用分页偏移量作为开始计算数,解决方案如下:
2、分页查询加序号
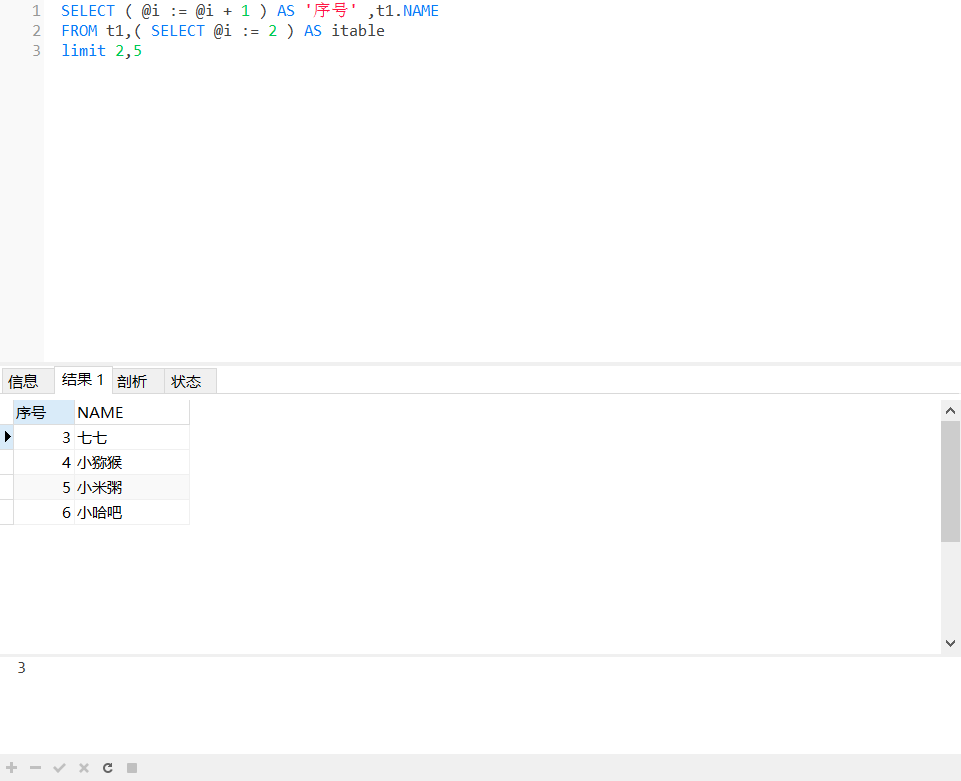
SELECT ( @i := @i + 1 ) AS '序号' ,t1.NAME FROM t1,( SELECT @i := 2 ) AS itable limit 2,5
SELECT ( @i := @i + 1 ) AS '序号' ,t1.NAME FROM t1,( SELECT @i := #{startSize} ) AS itable limit #{startSize},#{pageSize};
二、表结构以及数据
CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `jgid` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8; INSERT INTO `avlicy`.`t1`(`id`, `name`, `jgid`) VALUES (1, '二二', 2); INSERT INTO `avlicy`.`t1`(`id`, `name`, `jgid`) VALUES (2, '李四', 2); INSERT INTO `avlicy`.`t1`(`id`, `name`, `jgid`) VALUES (4, '七七', 3); INSERT INTO `avlicy`.`t1`(`id`, `name`, `jgid`) VALUES (5, '小猕猴', 1); INSERT INTO `avlicy`.`t1`(`id`, `name`, `jgid`) VALUES (6, '小米粥', 1); INSERT INTO `avlicy`.`t1`(`id`, `name`, `jgid`) VALUES (7, '小哈吧', 1);
三、解释说明
1、解释
- (@i:=@i+1) 也可以写成 @i:=@i+1 ,加括号是为了视觉上更清晰。它代表的意思是:变量i 加1 赋值给变量i,在定义好一个变量后每次查询都会给这个变量自增,每次执行查询语句获取结果后就不需要这个变量自增了
- (SELECT @i:=0) AS itable,定义用户变量i,设置初始值为0,然后将它作为派生表使用,AS定义了表的别名。
- SET @i=0 。定义用户变量i,赋初值为0,
2、相关知识点
- MySQL定义用户变量的方式:select @变量名 ,上面的SQL语句中,变量的名字是 i
- 用户变量赋值:一种是直接用"=“号,另一种是用”:="号。
3、= 和 := 的区别:
使用set命令对用户变量进行赋值时,两种方式都可以使用
即:SET @变量名=xxx 或 SET @变量名:=xxx
使用select语句对用户变量进行赋值时,只能使用":=“方式,因为在select语句中,”="号被看作是比较操作符。即:SELECT @变量名:=xxx
- ①:用户变量
- ②:派生表
- ③:AS设置别名
到此这篇关于Mysql给普通分页查询结果加序号实操的文章就介绍到这了,更多相关Mysql分页查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

jsp+mysql实现网页的分页查询
本文实例为大家分享了jsp+mysql实现网页的分页查询的具体代码,供大家参考,具体内容如下 一.实现分页查询的核心sql语句 (1)查询数据库的记录总数的sql语句: select count(*) from +(表名); (2)每次查询的记录数的sql语句: 其中:0是搜索的索引,2是每次查找的条数. select * from 表名 limit 0,2; 二.代码实现 *上篇写过这两个类 , DBconnection类:用于获取数据库连接,Author对象类.这两个类的代码点击连接查看.点
-
MySQL实现分页查询的方法
SQL分页查询: 背景 在公司的系统中有一个平台是 做配置管理的 就是所谓的 CRUD 的平台,但是点击后进去到页面第一次看到的是一次查询的页面 (点击页面自动的触发查询的功能) 后面就可以你的CRUD的操作是给运营的同事来操作的,但是一般的是我们数据量比较的少的业务是之间查询出来所有的数据,直接返回给前端的让他自己做分页的,但是有一些数据量达到上万级别的时候,不能让他们乱搞了,必须要用到给我多加入两个参数了 解决方法 非常的简单的加入两个参数 (1) 页数 (2) 每页的查询的数量 (后端
-
MySQL百万级数据分页查询优化方案
当需要从数据库查询的表有上万条记录的时候,一次性查询所有结果会变得很慢,特别是随着数据量的增加特别明显,这时需要使用分页查询.对于数据库分页查询,也有很多种方法和优化的点.下面简单说一下我知道的一些方法. 准备工作 为了对下面列举的一些优化进行测试,下面针对已有的一张表进行说明. 表名:order_history 描述:某个业务的订单历史表 主要字段:unsigned int id,tinyint(4) int type 字段情况:该表一共37个字段,不包含text等大型数组,最大为varcha
-
MySQL 分页查询的优化技巧
在有分页查询的应用中,包括 LIMIT 和 OFFSET 的查询十分常见,而且几乎每个都会有一个 ORDER BY 子句.如果使用索引排序的话将对性能优化十分有帮助,否则服务端需要做很多文件排序. 一个高频的问题是 offset 的值过大.如果查询类似 LIMIT 10000, 20,将会产生10020行,并将之前的10000行丢弃,这样的代价很高.假设所有的页使用相同的频次访问,这样的查询将平均扫描一半数据表.为了优化他们,你可以在分页视图中限制最多可访问的页数,或者让大便宜的查询更有效. 一
-
golang通过mysql语句实现分页查询
目录 1.前端接口调用 2.register访问入口 3.解析参数 4.service实现 5.mapper实现 1.前端接口调用 2.register访问入口 //查询一个用户下所有的subnet ws.Route(ws.GET("/subnets"). To(sc.ListSubnet). Doc("List subnets authorized to the login user."). Param(ws.QueryParameter(query.Parame
-
Mysql 如何实现多张无关联表查询数据并分页
Mysql 多张无关联表查询数据并分页 功能需求 在三张没有主外键关联的表中取出自己想要的数据,并且分页. 数据库表结构 水果表: 坚果表: 饮料表: 数据库随便建的,重在方法. 主要使用UNION ALL 操作符 UNION ALL 操作符用于合并两个或多个 SELECT 语句的结果集. 请注意,UNION ALL内部的 SELECT 语句必须拥有相同数量的列.列也必须拥有相似的数据类型.同时,每条 SELECT 语句中的列的顺序必须相同 ; 另外,UNION ALL结果集中的列名总是等于 U
-
Mysql给普通分页查询结果加序号实操
目录 一.效果展示 1.普通查询加序号 2.分页查询加序号 二.表结构以及数据 三.解释说明 一.效果展示 1.普通查询加序号 SELECT t1.NAME,( @i := @i + 1 ) AS '序号' FROM t1,( SELECT @i := 0 ) AS itable; 这种情况遇上分页时会出现每次翻页都从1开始重新计算,这种情况可以使用分页偏移量作为开始计算数,解决方案如下: 2.分页查询加序号 SELECT ( @i := @i + 1 ) AS '序号' ,t1.NAME FR
-
浅谈Mysql大数据分页查询解决方案
目录 1.简介 2.分页插件使用 3.sql测试与分析 3.1 limit现象分析 3.2 解决之道 4 测试时走过的坑 4.1 百万数据内容都一样 4.2 写sql时,把"77"写成了77: 4.3 一个有趣的现象 总结 1.简介 之前,面阿里的时候,有个面试官问我有没有使用过分页查询,我说有,他说分页查询是有问题的,怎么解决:后来这个问题我没有回答出来:本着学习的态度,今天来解决一下这个问题: 2.分页插件使用 1.pom文件 <dependency> <grou
-
MySQL中SQL分页查询的几种实现方法及优缺点
[SQL]SQL分页查询总结 开发过程中经常遇到分页的需求,今天在此总结一下吧. 简单说来方法有两种,一种在源上控制,一种在端上控制.源上控制把分页逻辑放在SQL层:端上控制一次性获取所有数据,把分页逻辑放在UI上(如GridView).显然,端上控制开发难度低,适于小规模数据,但数据量增大时性能和IO消耗无法接受:源上控制在性能和开发难度上较为平衡,适应大多数业务场景:除此之外,还可以根据客观情况(性能要求,源与端的资源占用等)在源和端之间加一层,应用特殊算法和技术进行处理.以下主要讨论源上,
-
使用MySQL如何实现分页查询
目录 一.分页 1. 什么是分页 2. 真分页 3. 假分页 4. 缓存层 二.MySQL实现分页 1. LIMIT用法 2. 分页公式 8种MySQL分页方法总结 方法1: 直接使用数据库提供的SQL语句 方法2: 建立主键或唯一索引, 利用索引(假设每页10条) 方法3: 基于索引再排序 方法4: 基于索引使用prepare 方法5:利用MySQL支持ORDER操作可以利用索引快速定位部分元组,避免全表扫描 方法6: 利用"子查询/连接+索引"快速定位元组的位置,然后再读取元组.
-
mysql、mssql及oracle分页查询方法详解
本文实例讲述了mysql.mssql及oracle分页查询方法.分享给大家供大家参考.具体分析如下: 分页查询在web开发中是最常见的一种技术,最近在通过查资料,有一点自己的心得 一.mysql中的分页查询 注: m=(pageNum-1)*pageSize;n= pageSize; pageNum是要查询的页码,pageSize是每次查询的数据量, 方法一: select * from table order by id limit m, n; 该语句的意思为,查询m+n条记录,去掉前m条,返
-
MySQL自动为查询数据结果加序号
目录 数据表 MySQL给查询加序号 解释说明 相关知识点 数据表 DROP TABLE IF EXISTS tb_score; CREATE TABLE tb_score( id INT(11) NOT NULL auto_increment, userid VARCHAR(20) NOT NULL COMMENT '用户id', subject VARCHAR(20) COMMENT '科目', score DOUBLE COMMENT '成绩', PRIMARY KEY(id) )ENGI
-
oracle,mysql,SqlServer三种数据库的分页查询的实例
MySql: MySQL数据库实现分页比较简单,提供了 LIMIT函数.一般只需要直接写到sql语句后面就行了.LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数.例如:select * from table WHERE - LIMIT 10; #返回前10行select * from table WHERE - LIMIT 0,10; #返回前
-
MySQL百万级数据量分页查询方法及其优化建议
数据库SQL优化是老生常谈的问题,在面对百万级数据量的分页查询,又有什么好的优化建议呢?下面将列举了一些常用的方法,供大家参考学习! 方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N 适应场景: 适用于数据量较少的情况(元组百/千级) 原因/缺点: 全表扫描,速度会很慢 且 有的数据库结果集返回不稳定(如某次返回1,2,3,另外的一次返回2,1,3). Limit限制的是从结果集的M位置处取出N条输出,其余
-
MySQL优化教程之超大分页查询
背景 基本上只要是做后台开发,都会接触到分页这个需求或者功能吧.基本上大家都是会用MySQL的LIMIT来处理,而且我现在负责的项目也是这样写的.但是一旦数据量起来了,其实LIMIT的效率会极其的低,这一篇文章就来讲一下LIMIT子句优化的. LIMIT优化 很多业务场景都需要用到分页这个功能,基本上都是用LIMIT来实现. 建表并且插入200万条数据: # 新建一张t5表 CREATE TABLE `t5` ( `id` int NOT NULL AUTO_INCREMENT, `name`