面试官问订单ID是如何生成的?难道不是MySQL自增主键
一个美女面试官坐到我的对面,发光logo的MacBook也挡不住她那圆润可爱的脸庞。
程序媛本就稀有,美女面试官更是难寻。
这么温柔可爱的面试官,应该不会为难我吧。嗯,应该是的,毕竟我这么帅气,面试可能就是走个过场。美女面试官是不是单身?毕竟程序员都不善交流,因为我也是单身,难道我的姻缘就在此注定。孩子的名字我都想好了。一冰!好名字。
面试官: 小伙子,你低着头笑什么呐。开始面试了,你知道订单ID是怎么生成的吗?
啥?订单ID怎么生成?美女怎么不按套路出牌!HashMap实现原理,我已经倒背如流,你不问。瞎问什么订单ID。
我: 还能咋生成?用数据库主键自增呗。
面试官: 这样不行啊。数据库主键顺序自增,每天有多少订单量被竞争对手看的一清二楚,商业机密都暴露了。
况且单机MySQL只能支持几百量级的并发,我们公司每天千万订单量,hold不住啊。
我: 嗯,那就用用数据库集群,自增ID起始值按机器编号,步长等于机器数量。
比如有两台机器,第一台机器生成的ID是1、3、5、7,第二台机器生成的ID是2、4、6、8。性能不行就加机器,这并发量der一下就上去了。
面试官: 小伙子,你想得倒是挺好。你有没有想过实现百万级的并发,大概就需要2000台机器,你这还只是用来生成订单ID,公司再有钱也经不起这么造。
我: 既然MySQL的并发量不行,我们是不是可以提前从MySQL获取一批自增ID,加载到本地内存中,然后从内存中并发取,这并发性能岂不是杠杠滴。
面试官: 你还挺上道,这种叫号段模式。并发量是上去了,但是自增ID还是不能作为订单ID的。
我: 用Java自带UUID怎么样?
import java.util.UUID;
/**
* @author yideng
* @apiNote UUID示例
*/
public class UUIDTest {
public static void main(String[] args) {
String orderId = UUID.randomUUID().toString().replace("-", "");
System.out.println(orderId);
}
}
输出结果:
58e93ecab9c64295b15f7f4661edcbc1
面试官: 也不行。32位字符串会占用更大的空间,无序的字符串作数据库主键,每次插入数据库的时候,MySQL为了维护B+树结构,需要频繁调整节点顺序,影响性能。况且字符串太长,也没有任何业务含义,pass。
小伙子,你可能是没参与过电商系统,我先跟说一下生成订单ID要满足哪些条件:
全局唯一:如果订单ID重复了,肯定要完蛋。
高性能:要做到高并发、低延迟。生成订单ID都成为瓶颈了,那还得了。
高可用:至少要做到4个9,别动不动就宕机了。
易用性:如果为了满足上述要求,搞了几百台服务器,复杂且难以维护,也不行。
数值且有序递增:数值占用的空间更小,有序递增能保证插入MySQL的时候更高性能。
嵌入业务含义:如果订单ID里面能嵌入业务含义,就能通过订单ID知道是哪个业务线生成的,便于排查问题。
我擦,生成一个小小的订单ID,搞出这么多规则,还能玩下去吗?难道今天的面试要跪,怎么可能。一灯的文章我一直订阅,这个还能难得住我,陪美女程序员玩玩还当真了。
我: 我听说圈内有一种流传已久的分布式、高性能、高可用的订单ID生成算法—雪花算法,完全能满足你的上述要求。雪花算法生成ID是Long类型,长度64位。
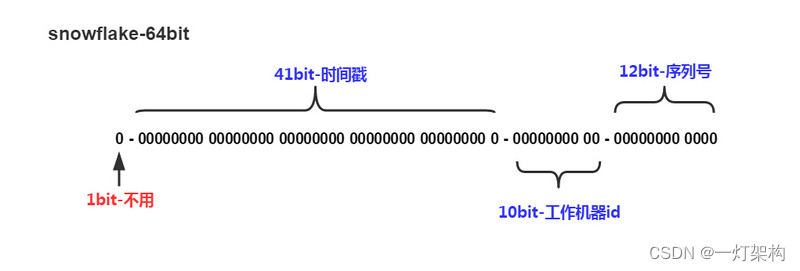
第 1 位: 符号位,暂时不用。
第 2~42 位: 共41位,时间戳,单位是毫秒,可以支撑大约69年
第 43~52 位: 共10位,机器ID,最多可容纳1024台机器
第 53~64 位: 共12位,序列号,是自增值,表示同一毫秒内产生的ID,单台机器每毫秒最多可生成4096个订单ID
代码实现:
/**
* @author 一灯架构
* @apiNote 雪花算法
**/
public class SnowFlake {
/**
* 起始时间戳,从2021-12-01开始生成
*/
private final static long START_STAMP = 1638288000000L;
/**
* 序列号占用的位数 12
*/
private final static long SEQUENCE_BIT = 12;
/**
* 机器标识占用的位数
*/
private final static long MACHINE_BIT = 10;
/**
* 机器数量最大值
*/
private final static long MAX_MACHINE_NUM = ~(-1L << MACHINE_BIT);
/**
* 序列号最大值
*/
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long TIMESTAMP_LEFT = SEQUENCE_BIT + MACHINE_BIT;
/**
* 机器标识
*/
private long machineId;
/**
* 序列号
*/
private long sequence = 0L;
/**
* 上一次时间戳
*/
private long lastStamp = -1L;
/**
* 构造方法
* @param machineId 机器ID
*/
public SnowFlake(long machineId) {
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new RuntimeException("机器超过最大数量");
}
this.machineId = machineId;
}
/**
* 产生下一个ID
*/
public synchronized long nextId() {
long currStamp = getNewStamp();
if (currStamp < lastStamp) {
throw new RuntimeException("时钟后移,拒绝生成ID!");
}
if (currStamp == lastStamp) {
// 相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
// 同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStamp = getNextMill();
}
} else {
// 不同毫秒内,序列号置为0
sequence = 0L;
}
lastStamp = currStamp;
return (currStamp - START_STAMP) << TIMESTAMP_LEFT // 时间戳部分
| machineId << MACHINE_LEFT // 机器标识部分
| sequence; // 序列号部分
}
private long getNextMill() {
long mill = getNewStamp();
while (mill <= lastStamp) {
mill = getNewStamp();
}
return mill;
}
private long getNewStamp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
// 订单ID生成测试,机器ID指定第0台
SnowFlake snowFlake = new SnowFlake(0);
System.out.println(snowFlake.nextId());
}
}
输出结果:
6836348333850624
接入非常简单,不需要搭建服务集群,。代码逻辑非常简单,,同一毫秒内,订单ID的序列号自增。同步锁只作用于本机,机器之间互不影响,每毫秒可以生成四百万个订单ID,非常强悍。
生成规则不是固定的,可以根据自身的业务需求调整。如果你不需要那么大的并发量,可以把机器标识位拆出一部分,当作业务标识位,标识是哪个业务线生成的订单ID。
面试官: 小伙子,有点东西,深藏不漏啊。再问个更难的问题,你觉得雪花算法还有改进的空间吗?
你真是打破砂锅问到底,不把我问趴下不结束。幸亏来之前我瞥了一眼一灯的文章。
我: 有的,雪花算法严重依赖系统时钟。如果时钟回拨,就会生成重复ID。
面试官: 有什么解决办法吗?
我: 有问题就会有答案。比如美团的Leaf(美团自研一种分布式ID生成系统),为了解决时钟回拨,引入了zookeeper,原理也很简单,就是比较当前系统时间跟生成节点的时间。
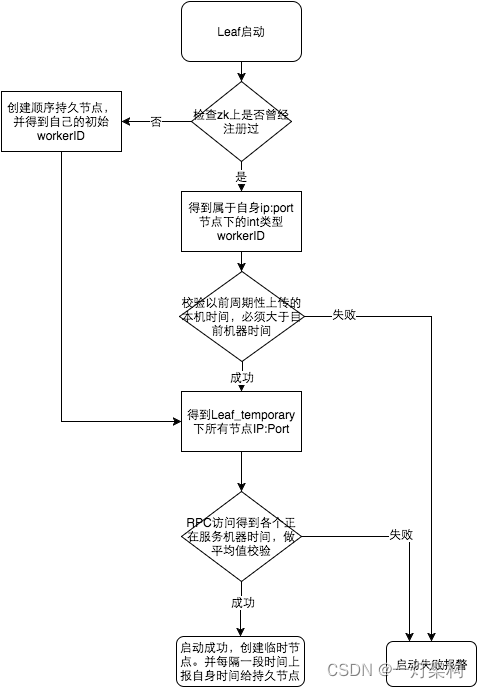
有的对并发要求更高的系统,比如双十一秒杀,每毫秒4百万并发还不能满足要求,就可以使用雪花算法和号段模式相结合,比如百度的UidGenerator、滴滴的TinyId。想想也是,号段模式的预先生成ID肯定是高性能分布式订单ID的最终解决方案。
面试官: 小伙子,我看你简历上写着已经离职了。明天就来上班吧,薪资double,就这样了。
总结
到此这篇关于面试官问订单ID是如何生成的文章就介绍到这了,更多相关MySQL自增主键生成订单ID内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL的自增ID(主键) 用完了的解决方法
在 MySQL 中用很多类型的自增 ID,每个自增 ID 都设置了初始值.一般情况下初始值都是从 0 开始,然后按照一定的步长增加(一般是自增 1).一般情况下,我们都是用int(11)来作为数据表的自增 ID,在 MySQL 中只要定义了这个数的字节长度,那么就会有上限. MySQL的自增ID(主键) 用完了,怎么办? 如果用 int unsigned (int,4个字节 ), 我们可以算下最大当前声明的自增ID最大是多少,由于这里定义的是 int unsigned,所以最大可以达到2的32幂
-

详解MySQL自增主键的实现
目录 一.自增值保存在哪儿? 二.自增值修改机制 三.自增值的修改时机 四.自增锁的优化 五.自增主键用完了 一.自增值保存在哪儿? 不同的引擎对于自增值的保存策略不同 1.MyISAM引擎的自增值保存在数据文件中 2.InnoDB引擎的自增值,在MySQL5.7及之前的版本,自增值保存在内存里,并没有持久化.每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将max(id)+步长作为这个表当前的自增值 select max(ai_col) from table_name
-
MySQL中的主键自增机制详情
目录 主键自增 自增主键保存在哪里 自增值修改机制 自增值的修改时机 如何修改自增主键值 主键自增 MySQL 提供了主键自增机制 AUTO_INCREMENT. 对主键使用, 保证了主键的唯一性. 注意:自增长必须与主键字段配合使用. 默认的主键的起始值为 1, 每次增量为 1, 也可以手动指定其自增起始值 auto_increment_offset 和自增步长 auto_increment_increment. -- 设置主键自增 CREATE TABLE USER( id INT UNSI
-
浅谈MySQL中的自增主键用完了怎么办
在面试中,大家应该经历过如下场景 面试官:"用过mysql吧,你们是用自增主键还是UUID?" 你:"用的是自增主键" 面试官:"为什么是自增主键?" 你:"因为采用自增主键,数据在物理结构上是顺序存储,性能最好,blabla-" 面试官:"那自增主键达到最大值了,用完了怎么办?" 你:"what,没复习啊!!" (然后,你就可以回去等通知了!) 这个问题是一个粉丝给我提的,我觉得
-
深入谈谈MySQL中的自增主键
MySQL的主键可以是自增的,那么如果在断电重启后新增的值还会延续断电前的自增值吗?自增值默认为1,那么可不可以改变呢?下面就说一下 MySQL的自增值. 特点 保存策略 1.如果存储引擎是 MyISAM,那么这个自增值是存储在数据文件中的: 2.如果是 InnoDB引擎,1)在 5.6之前是存储在内存中,没有持久化,在重启后会去找最大的键值,举个例子,如果一个表当前数据行里最大 id是10,AUTO_INCREMENT=11.这时候,我们删除 id=10 的行,AUTO_INCREMENT 还
-
Mysql更新自增主键id遇到的问题
目录 为什么要更新自增id 问题 如何解决 本是一个自己知道的问题,还是差点踩坑(差点忘了,还好上线前整理上线点时想起来了),特此记录下来 为什么要更新自增id 我是因为历史业务上的坑,导致必须更新一批id,且为了避免冲突需要将id扩大多少倍进行更新,因为我这个表的数据数量不高,属于高读低写的情况,所以就简单的扩大了1000 问题 MySQL中如果我们把自增主键更新为更大的值(例如现在自增id最大值是1000,你更新id=49这个记录到id=1049),MySQL并不会把表的自增值修改为更新后的
-
面试官问订单ID是如何生成的?难道不是MySQL自增主键
一个美女面试官坐到我的对面,发光logo的MacBook也挡不住她那圆润可爱的脸庞. 程序媛本就稀有,美女面试官更是难寻. 这么温柔可爱的面试官,应该不会为难我吧.嗯,应该是的,毕竟我这么帅气,面试可能就是走个过场.美女面试官是不是单身?毕竟程序员都不善交流,因为我也是单身,难道我的姻缘就在此注定.孩子的名字我都想好了.一冰!好名字. 面试官: 小伙子,你低着头笑什么呐.开始面试了,你知道订单ID是怎么生成的吗? 啥?订单ID怎么生成?美女怎么不按套路出牌!HashMap实现原理,我已经倒背如流
-
Mysql自增主键id不是以此逐级递增的处理
Mysql自增主键id不是以此逐级递增 一.介绍 在mysql数据库添加数据时使用ON DUPLICATE KEY UPDATE进行数据更新时可能会出现id不是逐级以此递增的,而是间断递增. 如id从10下次添加可能就是15或者其他的数字,两个数字之间间隔是ON DUPLICATE KEY UPDATE执行的次数,也就是说ON DUPLICATE KEY UPDATE在执行更新的时候把该表主键进行自增加一. 如图所示 二.问题介绍 在对于同一个表进行新增和修改时我用了两个mapper接口方法,也
-
面试官问如何启动Java 线程
目录 一.线程启动分析 二.线程启动过程 1. Thread start UML 图 2. Java 层面 Thread 启动 2.1 start() 方法 2.2 start0() 本地方法 3. JVM 创建线程 3.1 JVM_StartThread 3.2 JavaThread 3.3 os::create_thread 3.4 java_start 4. JVM 启动线程 4.1 Thread::start 4.2 os::start_thread(thread) 4.3 pd_sta
-
面试官问如何启动Java 线程
目录 一.线程启动分析 二.线程启动过程 1. Thread start UML 图 2. Java 层面 Thread 启动 2.1 start() 方法 2.2 start0() 本地方法 3. JVM 创建线程 3.1 JVM_StartThread 3.2 JavaThread 3.3 os::create_thread 3.4 java_start 4. JVM 启动线程 4.1 Thread::start 4.2 os::start_thread(thread) 4.3 pd_sta
-
当面试官问我ArrayList和LinkedList哪个更占空间时,我是这么答的(面试官必问)
前言 今天介绍一下Java的两个集合类,ArrayList和LinkedList,这两个集合的知识点几乎可以说面试必问的. 对于这两个集合类,相信大家都不陌生,ArrayList可以说是日常开发中用的最多的工具类了,也是面试中几乎必问的,LinkedList可能用的少点,但大多数的面试也会有所涉及,尤其是关于这两者的比较可以说是家常便饭,所以,无论从使用上还是在面试的准备上,对于这两个类的知识点我们都要有足够的了解. ArrayList ArrayList是List接口的一个实现类,底层是基于数
-
当面试官问mysql中char与varchar的区别
目录 char与varchar的区别 char与varchar的区别 以上就是当面试官问mysql中char与varchar的区别的详细内容,更多关于char与varchar的区别的资料请关注我们其它相关文章!
-
详解mybatis插入数据后返回自增主键ID的问题
1.场景介绍: 开发过程中我们经常性的会用到许多的中间表,用于数据之间的对应和关联.这个时候我们关联最多的就是ID,我们在一张表中插入数据后级联增加到关联表中.我们熟知的mybatis在插入数据后返回的是插入成功的条数,那么这个时候我们想要得到相应的这条新增数据的ID,该怎么办呢? 2.插入数据返回自增主键ID方法(一) 在映射器中配置获取记录主键值xml映射: 在xml中定义useGeneratedKeys为true,返回主键id的值,keyProperty和keyColumn分别代表数据库
-
面试官问我Mysql的存储引擎了解多少
目录 一.MySQL体系结构 二.存储引擎简介 三.存储引擎的使用 四.存储引擎特点 1.InnoDB 2.MyISAM 3.MEMORY 五.存储引擎选择 总结 文章部分来源于黑马Mysql视频教程当中! 一.MySQL体系结构 如下图,Mysql总共分为了四层: 连接层: 最上层是一些客户端和链接服务,主要完成一些类似于连接处理.授权认证.及相关的安全方案.服务器也会为安全接入的每个客户端验证它所具有的操作权限. 服务层: 第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查
-
Mybatis批量插入返回插入成功后的主键id操作
我们都知道Mybatis在插入单条数据的时候有两种方式返回自增主键: 1.对于支持生成自增主键的数据库:增加 useGenerateKeys和keyProperty ,<insert>标签属性. 2.不支持生成自增主键的数据库:使用<selectKey>. 但是怎么对批量插入数据返回自增主键的解决方式网上看到的还是比较少,至少百度的结果比较少. Mybatis官网资料提供如下: First, if your database supports auto-generated key