python 接口_从协议到抽象基类详解
抽象基类的常见用途:实现接口时作为超类使用。然后,说明抽象基类如何检查具体子类是否符合接口定义,以及如何使用注册机制声明一个类实现了某个接口,而不进行子类化操作。最后,说明如何让抽象基类自动“识别”任何符合接口的类——不进行子类化或注册。
Python文化中的接口和协议
接口在动态类型语言中是怎么运作的呢?首先,基本的事实是,Python语言没有 interface 关键字,而且除了抽象基类,每个类都有接口:类实现或继承的公开属性(方法或数据属性),包括特殊方法,如__getitem__ 或 __add__。
按照定义,受保护的属性和私有属性不在接口中:即便“受保护的”属性也只是采用命名约定实现的(单个前导下划线);私有属性可以轻松地访问,原因也是如此。不要违背这些约定。
另一方面,不要觉得把公开数据属性放入对象的接口中不妥,因为如果需要,总能实现读值方法和设值方法,把数据属性变成特性,使用obj.attr 句法的客户代码不会受到影响。 Vector2d 类就是这么做的,Vector2d 类的第一版,x 和 y 是公开属性。
vector2d_v0.py:x 和 y 是公开数据属性
class Vector2d: def __init__(self, x, y): self.x = x self.y = y def __iter__(self): return (n for n in (self.x, self.y))
我们把 x 和 y 变成了只读特性。这是一项重大重构,但是 Vector2d 的接口基本没变:用户仍能读取my_vector.x 和 my_vector.y。
class Vector2d: def __init__(self, x, y): self.__x = x self.__y = y @property def x(self): return self.__x @property def y(self): return self.__y def __iter__(self): return (i for i in (self.x, self.y))
Python喜欢序列
Python 数据模型的哲学是尽量支持基本协议。对序列来说,即便是最简单的实现,Python 也会力求做到最好。
下图展示了定义为抽象基类的 Sequence 正式接口。

Sequence 抽象基类和 collections.abc 中相关抽象类的UML 类图,箭头由子类指向超类,以斜体显示的是抽象方法
现在,看看下面🌰中的 Foo 类。它没有继承 abc.Sequence,而且只实现了序列协议的一个方法: __getitem__ (没有实现 __len__ 方法)。
>>> class Foo: ... def __getitem__(self, pos): ... return range(0, 30, 10)[pos] ... >>> f = Foo() >>> f[1] >>> for i in f: print(i) ... >>> 20 in f True >>> 15 in f False
虽然没有 __iter__ 方法,但是 Foo 实例是可迭代的对象,因为发现有__getitem__ 方法时,Python 会调用它,传入从 0 开始的整数索引,尝试迭代对象(这是一种后备机制)。尽管没有实现 __contains__ 方法,但是 Python 足够智能,能迭代 Foo 实例,因此也能使用 in 运算符:Python 会做全面检查,看看有没有指定的元素。
综上,鉴于序列协议的重要性,如果没有 __iter__ 和 __contains__方法,Python 会调用 __getitem__ 方法,设法让迭代和 in 运算符可用。
下面的FrenchDeck 类也没有继承 abc.Sequence,但是实现了序列协议的两个方法:__getitem__ 和 __len__。
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Cards(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, pos):
return self._cards[pos]
使用猴子补丁在运行时实现协议
FrenchDeck 类有个重大缺陷:无法洗牌。如果 FrenchDeck 实例的行为像序列,那么它就不需要 shuffle 方法,因为已经有 random.shuffle 函数可用,文档中说它的作用是“就地打乱序x”(https://docs.python.org/3/library/random.html#random.shuffle)。
标准库中的 random.shuffle 函数用法如下:
>>> from random import shuffle >>> my_list = list(range(1, 11)) >>> shuffle(my_list) >>> my_list [5, 7, 9, 2, 10, 1, 8, 6, 4, 3]
然而,如果尝试打乱 FrenchDeck 实例,会出现异常,如下面的 🌰 所示。
Traceback (most recent call last): File "/Users/demon/PycharmProjects/FluentPython/接口:从协议到抽象基类/FrenchDeck.py", line 37, in <module> shuffle(deck) File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/random.py", line 274, in shuffle x[i], x[j] = x[j], x[i] TypeError: 'FrenchDeck' object does not support item assignment
错误消息相当明确,“'FrenchDeck' object does not support itemassignment”('FrenchDeck' 对象不支持为元素赋值)。这个问题的原因是,shuffle 函数要调换集合中元素的位置,而 FrenchDeck 只实现了不可变的序列协议。可变的序列还必须提供 __setitem__ 方法。
解决办法为FrenchDeck 打猴子补丁,把它变成可变的,让random.shuffle 函数能处理
from collections import namedtuple
from random import shuffle
Cards = namedtuple('Cards', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Cards(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self): #获取长度的len
return len(self._cards)
def __getitem__(self, position): #能够支持切片取值的处理
return self._cards[position]
deck = FrenchDeck() #实例化
def set_card(deck, position, card): #猴子不定,其实就是启动调用内部__setitem__设置值得外部函数
deck._cards[position] = card
FrenchDeck.__setitem__ = set_card #把猴子补丁传递给内部的魔术方法
shuffle(deck) #打乱洗牌的序列
print(deck[:5]) #获取前五个卡牌的值
以上代码的执行结果为:
[Cards(rank='K', suit='diamonds'), Cards(rank='4', suit='spades'), Cards(rank='A', suit='clubs'), Cards(rank='K', suit='spades'), Cards(rank='6', suit='clubs')]
这里的关键是,set_card 函数要知道 deck 对象有一个名为 _cards 的属性,而且 _cards 的值必须是可变序列。然后,我们把 set_card 函数赋值给特殊方法 __setitem__,从而把它依附到 FrenchDeck 类上。这种技术叫猴子补丁:在运行时修改类或模块,而不改动源码。猴子补丁很强大,但是打补丁的代码与要打补丁的程序耦合十分紧密,而且往往要处理隐藏和没有文档的部分。
定义抽象基类的子类
在下面的🌰 中,我们明确把 FrenchDeck2 声明为collections.MutableSequence 的子类。
frenchdeck2.py:FrenchDeck2,collections.MutableSequence的子类
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck2(collections.MutableSequence):
ranks = [str(i) for i in range(1, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self): #支持查看长度
return len(self._cards)
def __getitem__(self, position): #支持切片
return self._cards[position]
def __setitem__(self, position, value): #支持洗牌
self._cards[position] = value
def __delitem__(self, position): #但是继承MutableSequence的类必须实现 __delitem__ 方法,这是MutableSequence 类的一个抽象方法。
del self._cards[position]
def insert(self, position, value): #此外,还要实现insert方法,这是MutableSequence类的第三个抽象方法
self._cards.insert(position, value)
Sequence 和 MutableSequence 抽象基类的方法不全是抽象的。
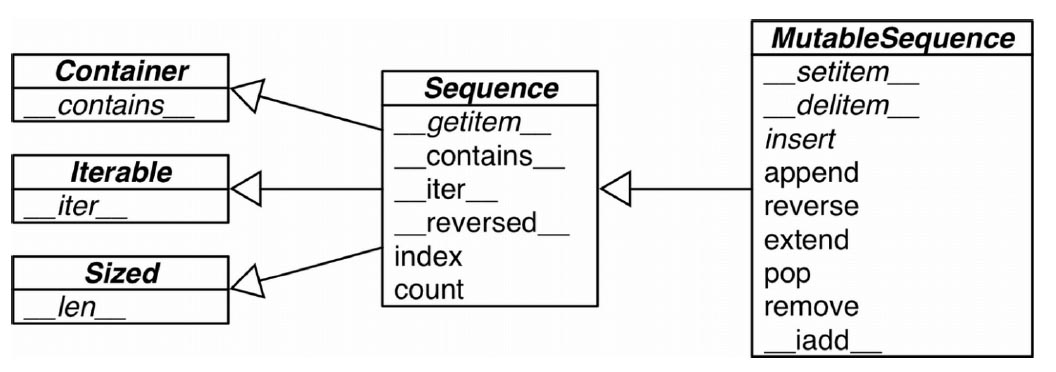
MutableSequence 抽象基类和 collections.abc 中它的超类的 UML 类图(箭头由子类指向祖先;以斜体显示的名称是抽象类和抽象方法)
FrenchDeck2 从 Sequence 继承了几个拿来即用的具体方法__contains__、__iter__、__reversed__、index 和count。FrenchDeck2 从MutableSequence 继承了append、extend、pop、remove 和__iadd__。
标准库中的抽象基类
从 Python 2.6 开始,标准库提供了抽象基类。大多数抽象基类在collections.abc 模块中定义,不过其他地方也有。例如,numbers和 io 包中有一些抽象基类。但是,collections.abc 中的抽象基类最常用。我们来看看这个模块中有哪些抽象基类。
collections.abc模块中的抽象基类

collections.abc 模块中各个抽象基类的 UML 类图
Iterable、Container 和 Sized
各个集合应该继承这三个抽象基类,或者至少实现兼容的协议。Iterable 通过 __iter__ 方法支持迭代,Container 通过__contains__ 方法支持 in 运算符,Sized 通过 __len__ 方法支持len() 函数。
Sequence、Mapping 和 Set
这三个是主要的不可变集合类型,而且各自都有可变的子类
MappingView
在 Python 3 中,映射方法 .items()、.keys() 和 .values() 返回的对象分别是 ItemsView、KeysView 和 ValuesView 的实例。前两个类还从 Set 类继承了丰富的接口。
Callable 和 Hashable
这两个抽象基类与集合没有太大的关系,只不过因为collections.abc 是标准库中定义抽象基类的第一个模块,而它们又太重要了,因此才把它们放到 collections.abc 模块中。我从未见过Callable 或 Hashable 的子类。这两个抽象基类的主要作用是为内置函数 isinstance 提供支持,以一种安全的方式判断对象能不能调用或散列。
Iterator
注意它是 Iterable 的子类。继 collections.abc 之后,标准库中最有用的抽象基类包是numbers
抽象基类的数字塔
numbers 包(https://docs.python.org/3/library/numbers.html)定义的是“数字塔”(即各个抽象基类的层次结构是线性的),其中 Number 是位于最顶端的超类,随后是 Complex 子类,依次往下,最底端是 Integral类:
Number
Complex
Real
Rational
Integral
因此,如果想检查一个数是不是整数,可以使用 isinstance(x,numbers.Integral),这样代码就能接受 int、bool(int 的子类),或者外部库使用 numbers 抽象基类注册的其他类型。为了满足检查的需要,你或者你的 API 的用户始终可以把兼容的类型注册为numbers.Integral 的虚拟子类。
与之类似,如果一个值可能是浮点数类型,可以使用 isinstance(x,numbers.Real) 检查。这样代码就能接受bool、int、float、fractions.Fraction,或者外部库(如NumPy,它做了相应的注册)提供的非复数类型。
定义并使用一个抽象基类
为了证明有必要定义抽象基类,我们要在框架中找到使用它的场景。想象一下这个场景:你要在网站或移动应用中显示随机广告,但是在整个广告清单轮转一遍之前,不重复显示广告。假设我们在构建一个广告管理框架,名为 ADAM。它的职责之一是,支持用户提供随机挑选的无重复类。 为了让 ADAM 的用户明确理解“随机挑选的无重复”组件是什么意思,我们将定义一个抽象基类。
受到“栈”和“队列”(以物体的排放方式说明抽象接口)启发,我将使用现实世界中的物品命名这个抽象基类:宾果机和彩票机是随机从有限的集合中挑选物品的机器,选出的物品没有重复,直到选完为止。
我们把这个抽象基类命名为 Tombola,这是宾果机和打乱数字的滚动容器的意大利名。
Tombola 抽象基类有四个方法,其中两个是抽象方法。
.load(...):把元素放入容器。
.pick():从容器中随机拿出一个元素,返回选中的元素
另外两个是具体方法。
.loaded():如果容器中至少有一个元素,返回 True。
.inspect():返回一个有序元组,由容器中的现有元素构成,不会修改容器的内容(内部的顺序不保留)。
展示了 Tombola 抽象基类和三个具体实现。
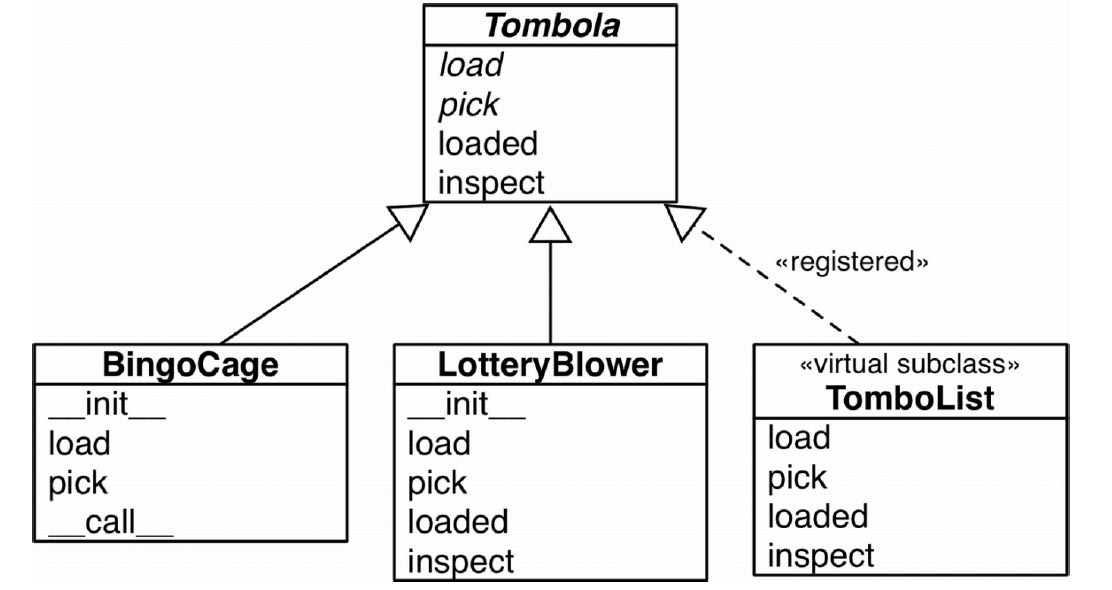
一个抽象基类和三个子类的 UML 类图。根据 UML 的约定,Tombola 抽象基类和它的抽象方法使用斜体。虚线箭头用于表示接口实现,这里它表示 TomboList 是 Tombola 的虚拟子类,因为TomboList 是注册的
import abc class Tombola(abc.ABC): #自己定义的抽象基类要继承abc.ABC @abc.abstractmethod def load(self, iterable): #抽象方法使用@abstractmethod装饰器标记,而且定义体中通常只有文档字符串 """从可迭代对象中添加元素""" @abc.abstractmethod def pick(self): #根据文档字符串,如果没有元素可选,应该抛出LookupError """随机删除元素,然后返回 如果实例为空,这个方法应该抛出'LookupError' """ def loaded(self): #抽象基类可以包含具体方法 """如果至少有一个元素,返回`True`,否则返回`False`。""" return bool(self.inspect()) def inspect(self): """返回一个有序元组,由当前元素构成。""" items = [] while True: try: items.append(self.pick()) except LookupError: break self.load(items) #使用 .load(...)把所有元素放回去 return tuple(sorted(items)) #返回排序好的items攻loaded调用
选择使用 LookupError 异常的原因是,在 Python 的异常层次关系中,它与 IndexError 和 KeyError 有关,这两个是具体实现 Tombola的数据结构最有可能抛出的异常。据此,实现代码可能会抛出LookupError、IndexError 或 KeyError 异常。
异常类的部分层次结构
BaseException ├── SystemExit ├── KeyboardInterrupt ├── GeneratorExit └── Exception ├── StopIteration ├── ArithmeticError │ ├── FloatingPointError │ ├── OverflowError │ └── ZeroDivisionError ├── AssertionError ├── AttributeError ├── BufferError ├── EOFError ├── ImportError ├── LookupError #我们在 Tombola.inspect 方法中处理的是 LookupError 异常 │ ├── IndexError #IndexError 是 LookupError 的子类,尝试从序列中获取索引超过最后位置的元素时抛出 │ └── KeyError #使用不存在的键从映射中获取元素时,抛出 KeyError 异常 ├── MemoryError ... etc.
我们自己定义的 Tombola 抽象基类完成了。为了一睹抽象基类对接口所做的检查,下面我们尝试使用一个有缺陷的实现来糊弄 Tombola,如下面的 🌰 所示
不符合 Tombola 要求的子类无法蒙混过关
>>> from tombola import Tombola >>> class Fake(Tombola): # 把Fake声明为Tombole的子类,继承抽象类 ... def pick(self): ... return 13 ... >>> Fake # 创建Fake类,目前木有毛线问题~ <class '__main__.Fake'> >>> f = Fake() # 报错了,Python认为Fake类是抽象类,因为没有实现load方法 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: Can't instantiate abstract class Fake with abstract methods load
抽象基类句法详解
声明抽象基类最简单的方式是继承 abc.ABC 或其他抽象基类。
然而,abc.ABC 是 Python 3.4 新增的类,因此如果你使用的是旧版Python,那么无法继承现有的抽象基类。此时,必须在 class 语句中使用 metaclass= 关键字,把值设为 abc.ABCMeta(不是 abc.ABC)。在下面的🌰 ,可以写成:
class Tombola(metaclass=abc.ABCMeta): # ...
metaclass= 关键字参数是 Python 3 引入的。在 Python 2 中必须使用__metaclass__ 类属性:
class Tombola(object): # 这是Python 2!!! __metaclass__ = abc.ABCMeta # ...
除了 @abstractmethod 之外,abc 模块还定义了@abstractclassmethod、@abstractstaticmethod 和@abstractproperty 三个装饰器。然而,后三个装饰器从 Python 3.3起废弃了,因为装饰器可以在 @abstractmethod 上堆叠,那三个就显得多余了。例如,声明抽象类方法的推荐方式是:
class MyABC(abc.ABC): @classmethod @abc.abstractmethod def an_abstract_classmethod(cls, ...): pass
定义Tombola抽象基类的子类
定义好 Tombola 抽象基类之后,我们要开发两个具体子类,满足Tombola 规定的接口。
下面的🌰 中的 BingoCage 类,使用了更好的随机发生器。 BingoCage 实现了所需的抽象方法 load 和 pick,从 Tombola 中继承了 loaded 方法,覆盖了 inspect 方法,还增加了__call__ 方法。
import random
import abc
class Tombola(abc.ABC): #自己定义的抽象基类要继承abc.ABC
@abc.abstractmethod
def load(self, iterable): #抽象方法使用@abstractmethod装饰器标记,而且定义体中通常只有文档字符串
"""从可迭代对象中添加元素"""
@abc.abstractmethod
def pick(self): #根据文档字符串,如果没有元素可选,应该抛出LookupError
"""随机删除元素,然后返回
如果实例为空,这个方法应该抛出'LookupError'
"""
def loaded(self): #抽象基类可以包含具体方法
"""如果至少有一个元素,返回`True`,否则返回`False`。"""
return bool(self.inspect())
def inspect(self):
"""返回一个有序元组,由当前元素构成。"""
items = []
while True:
try:
items.append(self.pick())
except LookupError:
break
self.load(items) #使用 .load(...)把所有元素放回去
return tuple(sorted(items)) #返回排序好的items攻loaded调用
#下面的代码应该单端放到一个py文件中,为了省事,就不在单独放到一个模块里面导入了~
class BigoCage(Tombola): #明确指定BingoCage类扩展Tombola类
def __init__(self, items):
self._randomizer = random.SystemRandom() #假设我们将在线上游戏中使用这个。random.SystemRandom使用os.urandom(...) 函数实现randomAPI
self._items = []
self.load(items) #委托.load(...)方法实现初始加载
def load(self, items):
self._items.extend(items) #如果通过load方法传递一个可迭代的对象进来,可以扩展到以后的self._items的列表中
self._randomizer.shuffle(self._items) #没有使用random.shuffle而是使用了SystemRandom中的shuffle方法
def pick(self):
try:
return self._items.pop()
except IndexError:
raise LookupError('pick from empty BingoCage')
def __call__(self):
self.pick()
b = BigoCage(range(10))
print(b.pick())
下面是 Tombola 接口的另一种实现,虽然与之前不同,但完全有效。LotteryBlower 打乱“数字球”后没有取出最后一个,而是取出一个随机位置上的球。
lotto.py:LotteryBlower 是 Tombola 的具体子类,覆盖了继承的 inspect 和 loaded 方法
import random
from tombola import Tombola
class LotteryBlower(Tombola):
def __init__(self, iterable):
self._balls = list(iterable) #创建一个副本
def load(self, iterbale):
self._balls.extend(iterbale) #把一个可迭代的对象添加到列表中
def pick(self):
try:
position = random.randrange(len(self._balls)) #获取一个随机数
except ValueError:
raise LookupError('pick from empty LotteryBlower')
return self._balls.pop(position) #删除列表中通过列表长度获取的随机数位置的索引值
def loaded(self):
return bool(self._balls)
def inspect(self):
return tuple(sorted(self._balls))
以上这篇python 接口_从协议到抽象基类详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python抽象基类用法实例分析
本文实例讲述了python抽象基类用法.分享给大家供大家参考.具体如下: 定义抽象类,需要使用abc模块,该模块定义了一个元类(ABCMeata),和装饰器 @abstractmethod, @abstractproperty 如果要实例化继承了Foo 的子类,子类必须实现了Foo所有的抽象方法(跟java一样),否则实例化报错. 抽象类不能直接实例化 #!coding=utf-8 from abc import ABCMeta, abstractmethod, abstractproperty
-

使用python实现接口的方法
接口基础知识: 简单说下接口测试,现在常用的2种接口就是http api和rpc协议的接口,今天主要说:http api接口是走http协议通过路径来区分调用的方法,请求报文格式都是key-value形式,返回报文一般是json串: 接口协议:http.webservice.rpc等. 请求方式:get.post方式 请求参数格式: a. get请求都是通过url?param=xxx¶m1=xxx b. post请求的请求参数常用类型有:application/json.applicat
-
Python抽象类的新写法
记得之前learn python一书里面,因为当时没有官方支持,只能通过hack的方式实现抽象方法,具体如下 最简单的写法 class MyCls(): def foo(self): print('method no implement') 运行的例子 >>> a = MyCls() >>> a.foo() method no implement >>> 这样虽然可以用,但是提示不明显,还是容易误用,当然,还有更好的方法 较为可以接受的写法 class
-
在Python中定义和使用抽象类的方法
像java一样python也可以定义一个抽象类. 在讲抽象类之前,先说下抽象方法的实现. 抽象方法是基类中定义的方法,但却没有任何实现.在java中,可以把方法申明成一个接口.而在python中实现一个抽象方法的简单的方法是: class Sheep(object): def get_size(self): raise NotImplementedError 任何从Sheep继承下来的子类必须实现get_size方法.否则就会产生一个错误.但这种实现方法有个缺点.定义的子类只有调用那个方法时才会
-
python 接口_从协议到抽象基类详解
抽象基类的常见用途:实现接口时作为超类使用.然后,说明抽象基类如何检查具体子类是否符合接口定义,以及如何使用注册机制声明一个类实现了某个接口,而不进行子类化操作.最后,说明如何让抽象基类自动"识别"任何符合接口的类--不进行子类化或注册. Python文化中的接口和协议 接口在动态类型语言中是怎么运作的呢?首先,基本的事实是,Python语言没有 interface 关键字,而且除了抽象基类,每个类都有接口:类实现或继承的公开属性(方法或数据属性),包括特殊方法,如__getitem_
-
C/C++中虚基类详解及其作用介绍
目录 概述 多重继承的问题 虚基类 初始化 例子 总结 概述 虚基类 (virtual base class) 是用关键字 virtual 声明继承的父类. 多重继承的问题 N 类: class N { public: int a; void display(){ cout << "A::a=" << a <<endl; } }; A 类: class A : public N { public: int a1; }; B 类: class B :
-
Python抽象基类的定义与使用方法
目录 1.定义抽象基类的子类 2.标准库中的抽象基类 3.定义抽象基类 4.再看白鹅类型 前言: 我们写Python基本不需要自己创建抽象基类,而是通过鸭子类型来解决大部分问题.<流畅的Python>作者使用了15年Python,但只在项目中创建过一个抽象基类.我们更多时候是创建现有抽象基类的子类,或者使用现有的抽象基类注册.本文的意义在于,了解抽象基类的定义与使用,可以帮助我们理解抽象基类是如何实现的,为我们以后学习后端语言(比如Java.Golang)打下基础.毕竟抽象基类是编程语言通用设
-
Python 数值区间处理_对interval 库的快速入门详解
使用 Python 进行数据处理的时候,常常会遇到判断一个数是否在一个区间内的操作.我们可以使用 if else 进行判断,但是,既然使用了 Python,那我们当然是想找一下有没有现成的轮子可以用.事实上,我们可以是用 interval 这一个库来完成我们需要的操作. 区间判断基础 最基础的区间判断操作就是先创建一个区间几个,然后使用 in 来判断一个数是否存在于区间之内.代码如下: from interval import Interval zoom_2_5 = Interval(2, 5)
-
python接口自动化如何封装获取常量的类
这篇文章主要介绍了python接口自动化如何封装获取常量的类,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景: 一.执行case的过程: 首先需要,我们能够通过excel获取单元格的内容.获取内容时,首先需要知道获取的数据是哪一行的,这行数据中需要拿那些参数,比如case 名称.请求url.请求方式.header.依赖id.依赖数据所属字段.请求数据.预期结果: 然后需要,判断字段.数据的合法性,将合法case组合成接口请求: 最后需要,执
-
基于Python的接口自动化unittest测试框架和ddt数据驱动详解
引言 在编写接口自动化用例时,我们一般针对一个接口建立一个.py文件,一条接口测试用例封装为一个函数(方法),但是在批量执行的过程中,如果其中一条出错,后面的用例就无法执行,还有在运行大量的接口测试用例时测试数据如何管理和加载.针对测试用例加载以及执行控制,python语言提供了unittest单元测试框架,将测试用例编写在unittest框架下,使用该框架可以单个或者批量加载互不影响的用例执行及更灵活的执行控制,对于更好的进行测试数据的管理和加载,这里我们引入数据驱动的模块:ddt,测试数据和
-
C++抽象基类讲解
公众号:Coder梁(ID:Coder_LT) 这一篇文章来聊聊抽象基类(abstract base class简称ABC). 我们之前说过,在我们实现继承的时候,需要保证派生类和基类之间是一种is-a的关系.在大多数时刻,这样的关系是没有问题的,然而在一些特殊的情况可能会遇到问题. 比如说,假设我们要实现所有的图形.在图形当中,圆是一种特殊的椭圆.但椭圆包含的属性更多,椭圆除了有中心点之外,还有半长轴.半短轴,以及方向角,而圆只需要圆心和半径即可. 也就是说虽然圆是椭圆,但圆包含的属性却更少
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常
-
python 函数中的内置函数及用法详解
今天来介绍一下Python解释器包含的一系列的内置函数,下面表格按字母顺序列出了内置函数: 下面就一一介绍一下内置函数的用法: 1.abs() 返回一个数值的绝对值,可以是整数或浮点数等. print(abs(-18)) print(abs(0.15)) result: 18 0.15 2.all(iterable) 如果iterable的所有元素不为0.''.False或者iterable为空,all(iterable)返回True,否则返回False. print(all(['a','b',