Kafka使用入门教程第1/2页
介绍
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。这个独特的设计是什么样的呢?
首先让我们看几个基本的消息系统术语:
•Kafka将消息以topic为单位进行归纳。
•将向Kafka topic发布消息的程序成为producers.
•将预订topics并消费消息的程序成为consumer.
•Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
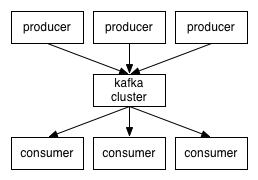
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
Topics 和Logs
先来看一下Kafka提供的一个抽象概念:topic.
一个topic是对一组消息的归纳。对每个topic,Kafka 对它的日志进行了分区,如下图所示:
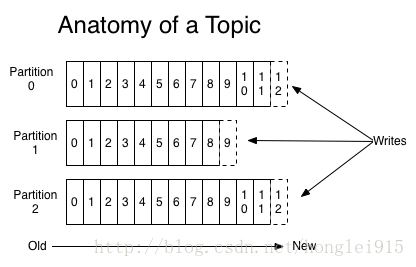
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。
实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset.这个offset有consumer来维护:一般情况下随着consumer不断的读取消息,这offset的值不断增加,但其实consumer可以以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。
以上特点的结合,使Kafka consumers非常的轻量级:它们可以在不对集群和其他consumer造成影响的情况下读取消息。你可以使用命令行来"tail"消息而不会对其他正在消费消息的consumer造成影响。
将日志分区可以达到以下目的:首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。
分布式
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”,leader负责处理消息的读和写,followers则去复制leader.如果leader down了,followers中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就会据有较好的负载均衡。
Producers
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。
Consumers
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。
更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。
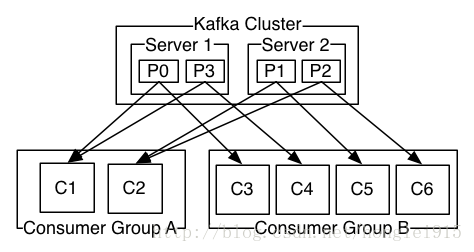
由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumerB组有4个
相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
接下来一步一步搭建Kafka运行环境。
Step 1: 下载Kafka点击下载最新的版本并解压.
> tar -xzf kafka_2.9.2-0.8.1.1.tgz > cd kafka_2.9.2-0.8.1.1
Step 2: 启动服务
Kafka用到了Zookeeper,所有首先启动Zookper,下面简单的启用一个单实例的Zookkeeper服务。可以在命令的结尾加个&符号,这样就可以启动后离开控制台。
> bin/zookeeper-server-start.sh config/zookeeper.properties &[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)...
现在启动Kafka:
> bin/kafka-server-start.sh config/server.properties[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)...
Step 3: 创建 topic
创建一个叫做“test”的topic,它只有一个分区,一个副本。
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
可以通过list命令查看创建的topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181test
除了手动创建topic,还可以配置broker让它自动创建topic.Step 4:发送消息.
Kafka 使用一个简单的命令行producer,从文件中或者从标准输入中读取消息并发送到服务端。默认的每条命令将发送一条消息。
运行producer并在控制台中输一些消息,这些消息将被发送到服务端:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is a messageThis is another message
ctrl+c可以退出发送。
Step 5: 启动consumerKafka also has a command line consumer that will dump out messages to standard output.
Kafka也有一个命令行consumer可以读取消息并输出到标准输出:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginningThis is a messageThis is another message
你在一个终端中运行consumer命令行,另一个终端中运行producer命令行,就可以在一个终端输入消息,另一个终端读取消息。
这两个命令都有自己的可选参数,可以在运行的时候不加任何参数可以看到帮助信息。
Step 6: 搭建一个多个broker的集群
刚才只是启动了单个broker,现在启动有3个broker组成的集群,这些broker节点也都是在本机上的:
首先为每个节点编写配置文件:
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
在拷贝出的新文件中添加以下参数:
config/server-1.properties: broker.id=1 port=9093 log.dir=/tmp/kafka-logs-1 config/server-2.properties: broker.id=2 port=9094 log.dir=/tmp/kafka-logs-2
broker.id在集群中唯一的标注一个节点,因为在同一个机器上,所以必须制定不同的端口和日志文件,避免数据被覆盖。
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
刚才已经启动可Zookeeper和一个节点,现在启动另外两个节点:
> bin/kafka-server-start.sh config/server-1.properties &...> bin/kafka-server-start.sh config/server-2.properties &...
创建一个拥有3个副本的topic:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
现在我们搭建了一个集群,怎么知道每个节点的信息呢?运行“"describe topics”命令就可以了:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topicTopic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
leader:负责处理消息的读和写,leader是从所有节点中随机选择的.replicas:列出了所有的副本节点,不管节点是否在服务中.isr:是正在服务中的节点.
在我们的例子中,节点1是作为leader运行。
向topic发送消息:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic...my test message 1my test message 2^C
消费这些消息:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic...my test message 1my test message 2^C
测试一下容错能力.Broker 1作为leader运行,现在我们kill掉它:
> ps | grep server-1.properties7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java...> kill -9 7564
另外一个节点被选做了leader,node 1 不再出现在 in-sync 副本列表中:
> bin/kafka-topics.sh --describe --zookeeper localhost:218192 --topic my-replicated-topicTopic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
虽然最初负责续写消息的leader down掉了,但之前的消息还是可以消费的:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic...my test message 1my test message 2^C
看来Kafka的容错机制还是不错的。
上篇文章中我们搭建了kafka的服务器,并可以使用Kafka的命令行工具创建topic,发送和接收消息。
下面我们来搭建kafka的开发环境。
添加依赖
搭建开发环境需要引入kafka的jar包,一种方式是将Kafka安装包中lib下的jar包加入到项目的classpath中,这种比较简单了。不过我们使用另一种更加流行的方式:使用maven管理jar包依赖。
创建好maven项目后,在pom.xml中添加以下依赖:
代码如下:
<dependency>
<groupId> org.apache.kafka</groupId >
<artifactId> kafka_2.10</artifactId >
<version> 0.8.0</ version>
</dependency>
添加依赖后你会发现有两个jar包的依赖找不到。没关系我都帮你想好了,点击这里下载这两个jar包,解压后你有两种选择,第一种是使用mvn的install命令将jar包安装到本地仓库,另一种是直接将解压后的文件夹拷贝到mvn本地仓库的com文件夹下,比如我的本地仓库是d:\mvn,完成后我的目录结构是这样的:
配置程序
首先是一个充当配置文件作用的接口,配置了Kafka的各种连接参数:
package com.sohu.kafkademon;
public interface KafkaProperties
{
final static String zkConnect = "10.22.10.139:2181";
final static String groupId = "group1";
final static String topic = "topic1";
final static String kafkaServerURL = "10.22.10.139";
final static int kafkaServerPort = 9092;
final static int kafkaProducerBufferSize = 64 * 1024;
final static int connectionTimeOut = 20000;
final static int reconnectInterval = 10000;
final static String topic2 = "topic2";
final static String topic3 = "topic3";
final static String clientId = "SimpleConsumerDemoClient";
}
producer
package com.sohu.kafkademon;
import java.util.Properties;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaProducer extends Thread
{
private final kafka.javaapi.producer.Producer<Integer, String> producer;
private final String topic;
private final Properties props = new Properties();
public KafkaProducer(String topic)
{
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "10.22.10.139:9092");
producer = new kafka.javaapi.producer.Producer<Integer, String>(new ProducerConfig(props));
this.topic = topic;
}
@Override
public void run() {
int messageNo = 1;
while (true)
{
String messageStr = new String("Message_" + messageNo);
System.out.println("Send:" + messageStr);
producer.send(new KeyedMessage<Integer, String>(topic, messageStr));
messageNo++;
try {
sleep(3000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
consumer
package com.sohu.kafkademon;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaConsumer extends Thread
{
private final ConsumerConnector consumer;
private final String topic;
public KafkaConsumer(String topic)
{
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig()
{
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
System.out.println("receive:" + new String(it.next().message()));
try {
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行下面这个程序,就可以进行简单的发送接收消息了:简单的发送接收
package com.sohu.kafkademon;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaConsumerProducerDemo
{
public static void main(String[] args)
{
KafkaProducer producerThread = new KafkaProducer(KafkaProperties.topic);
producerThread.start();
KafkaConsumer consumerThread = new KafkaConsumer(KafkaProperties.topic);
consumerThread.start();
}
}
高级别的consumer
下面是比较负载的发送接收的程序:
package com.sohu.kafkademon;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaConsumer extends Thread
{
private final ConsumerConnector consumer;
private final String topic;
public KafkaConsumer(String topic)
{
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig()
{
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
System.out.println("receive:" + new String(it.next().message()));
try {
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
不要畏惧文件系统!
Kafka大量依赖文件系统去存储和缓存消息。对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能。实际上硬盘的快慢完全取决于使用它的方式。设计良好的硬盘架构可以和内存一样快。
在6块7200转的SATA RAID-5磁盘阵列的线性写速度差不多是600MB/s,但是随即写的速度却是100k/s,差了差不多6000倍。现代的操作系统都对次做了大量的优化,使用了 read-ahead 和 write-behind的技巧,读取的时候成块的预读取数据,写的时候将各种微小琐碎的逻辑写入组织合并成一次较大的物理写入。对此的深入讨论可以查看这里,它们发现线性的访问磁盘,很多时候比随机的内存访问快得多。
为了提高性能,现代操作系统往往使用内存作为磁盘的缓存,现代操作系统乐于把所有空闲内存用作磁盘缓存,虽然这可能在缓存回收和重新分配时牺牲一些性能。所有的磁盘读写操作都会经过这个缓存,这不太可能被绕开除非直接使用I/O。所以虽然每个程序都在自己的线程里只缓存了一份数据,但在操作系统的缓存里还有一份,这等于存了两份数据。
另外再来讨论一下JVM,以下两个事实是众所周知的:
•Java对象占用空间是非常大的,差不多是要存储的数据的两倍甚至更高。
•随着堆中数据量的增加,垃圾回收回变的越来越困难。
基于以上分析,如果把数据缓存在内存里,因为需要存储两份,不得不使用两倍的内存空间,Kafka基于JVM,又不得不将空间再次加倍,再加上要避免GC带来的性能影响,在一个32G内存的机器上,不得不使用到28-30G的内存空间。并且当系统重启的时候,又必须要将数据刷到内存中( 10GB 内存差不多要用10分钟),就算使用冷刷新(不是一次性刷进内存,而是在使用数据的时候没有就刷到内存)也会导致最初的时候新能非常慢。但是使用文件系统,即使系统重启了,也不需要刷新数据。使用文件系统也简化了维护数据一致性的逻辑。
所以与传统的将数据缓存在内存中然后刷到硬盘的设计不同,Kafka直接将数据写到了文件系统的日志中。
当前1/2页 12下一页阅读全文
相关推荐
-
spring boot整合spring-kafka实现发送接收消息实例代码
前言 由于我们的新项目使用的是spring-boot,而又要同步新项目中建的数据到老的系统当中.原来已经有一部分的同步代码,使用的是kafka. 其实只是做数据的同步,我觉得选MQ没必要使用kafka.首先数据量不大,其实搞kafka又要搞集群,ZK.只是用做一些简单数据同步的话,有点大材小用. 没办法,咱只是个打工的,领导让搞就搞吧.刚开始的时候发现有一个spring-integration-kafka,描述中说是基于spring-kafka做了一次重写.但是我看了官方文档.实在是搞的有点头大
-

Kafka使用入门教程第1/2页
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topic为单位进行归纳. •将向Kafka topic发布消息的程序成为producers. •将预订topics并消费消息的程序成为consumer. •Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker. producers通过网络将消息发送到Kafka集群,集群
-
非常漂亮的Div+CSS布局入门教程第1/5页
在网页制作中,有许多的术语,例如:CSS.HTML.DHTML.XHTML等等.在下面的文章中我们将会用到一些有关于HTML的基本知识,而在你学习这篇入门教程之前,请确定你已经具有了一定的HTML基础.下面我们就开始一步一步使用DIV+CSS进行网页布局设计吧. 所有的设计第一步就是构思,构思好了,一般来说还需要用PhotoShop或FireWorks(以下简称PS或FW)等图片处理软件将需要制作的界面布局简单的构画出来,以下是我构思好的界面布局图. 下面,我们需要根据构思图来规划一下页面的布局
-
jsp Hibernate入门教程第1/3页
例如: 复制代码 代码如下: HibernateTest.java import onlyfun.caterpillar.*; import net.sf.hibernate.*; import net.sf.hibernate.cfg.*; import java.util.*; public class HibernateTest { public static void main(String[] args) throws HibernateException { SessionFacto
-
PHP类(Class)入门教程第1/2页
以我的观点来说说PHP中的Class,用于表达的语言都是非正式的语言,也不能确定是否正确. 建立一个类很简单. 复制代码 代码如下: <?php class my_class{} ?> 类到底干什么呢?很多人都说是什么黑匣子,我在这里称它为一个独立的整体.我们只知道类名,而不知道里面有什么东西.那么,该如何使用这个类呢? 首先:要知道它里面是否定义了公共的变量--专业术语上称它为"属性". 其次:要知道它里面定义了什么函数--专业术语中称它为"方法".
-
ABP(现代ASP.NET样板开发框架)系列之二、ABP入门教程详解
ABP是"ASP.NET Boilerplate Project (ASP.NET样板项目)"的简称. ASP.NET Boilerplate是一个用最佳实践和流行技术开发现代WEB应用程序的新起点,它旨在成为一个通用的WEB应用程序框架和项目模板. ABP的官方网站:http://www.aspnetboilerplate.com ABP在Github上的开源项目:https://github.com/aspnetboilerplate ABP 的由来 "DRY--避免重复
-
HTML 30分钟入门教程
运行下面的代码就可以了 HTML 30分钟入门教程 h1 {text-align:center} p {text-indent:2em; line-height:140%; margin:auto 10px} span {margin:3px} .code { border:solid 1px gray; background-color:#eee} .name { font-weight:bold } dl {margin-left:20px} dt {font-weight:bold} .t
-
Dom入门教程图解 推荐
那么Dom是如何读取和管理Html文件的呢?首先你必须要了解html的源码结构.看图 如果你有学过或写过Html,那么你会对上图一目了然.我想要说明的就是Html的源码结构是有层次的,而且标签与杯签之间还存在着父子,或相邻的关系.上图不难看出HTML这个标签是最顶级的.最上层的.也可以理解成html文件的根.其次是Head与Body标签.这两个标签是相邻的.也可以理解成兄弟关系.但他们都属于html的子标签或称为子元素.然后Body标签内包含了Table,Div,Div.这三个标签你可以理解为B
-
一篇不错的Python入门教程
原文 http://www.hetland.org/python/instant-hacking.php Instant Hacking[译文] 译者: 肯定来过 这是一篇简短的关于python程序设计语言的入门教程,原文在这里,翻着词典翻译了来! 这是一份对编程艺术的简短介绍,其中的例子是用python写成的.(如果你已经知道了该如何编程,但是想简单了解一下python,你可以查阅我的另一篇文章Instant Python.)这篇文章已经被翻译为意大利.波兰.日本.塞尔维亚以及巴西葡萄亚语等许
-
flash+php+mysql打造简单留言本教程第1/3页
(主要参考了火山的帖子:★FLASH与ASP通信入门教程--做真正属于自己的留言本!).网上没有比较好的php留言本相关教程,我下载的N多源文件都看得云里雾里,而且好多都将代码写在MC上.又或许可能有好的教程我没搜到,但无论如何,我现在要在这里班门弄斧一番了. flash+php+mysql简单留言本教程 目的: 用flash+php+mysql制作一个简单的留言本. 配置环境: 最开始肯定是先配置相应的环境了.我下载的是配置环境套件包,傻瓜式的方法,简易安装,比较适合我.下载地址:http:/
-
Vue.js快速入门教程
像AngularJS这种前端框架可以让我们非常方便地开发出强大的单页应用,然而有时候Angular这种大型框架对于我们的项目来说过于庞大,很多功能不一定会用到.这时候我们就需要评估一下使用它的必要性了.如果我们仅仅需要在一个简单的网页里添加屈指可数的几个功能,那么用Angular就太麻烦了,必要的安装.配置.编写路由和设计控制器等等工作显得过于繁琐. 这时候我们需要一个更加轻量级的解决方案.Vue.js就是一个不错的选择.Vue.js是一个专注于视图模型(ViewModal)的框架.视图模型是U