Python爬虫利用cookie实现模拟登陆实例详解
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
举个例子,某些网站是需要登录后才能得到你想要的信息的,不登陆只能是游客模式,那么我们可以利用Urllib2库保存我们以前登录过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登录抓取目标网页做出准备。
我之前的帖子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要利用到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块,他能与urllib2相互结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续连接请求时重新发送,这样就可以实现我们所需要的模拟登录功能。
这里特别说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中竟然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)
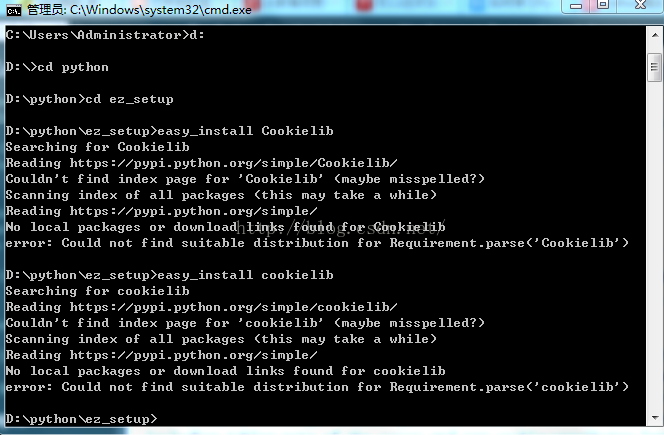
之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各种瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下面也会讲到。urllib2.urlopen()函数不支持验证、cookie或者其它HTTP高级功能。要支持这些功能,必须使用build_opener()(可以用于让python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1 name=BIDUPSID value=73BD718962A6EA0DAD4CB9578A08FDD0 name=H_PS_PSSID value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398 name=PSTM value=1478834132 name=BDSVRTM value=0 name=BD_HOME value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习如何保存cookie。在这里我们使用它的子类MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将上面的例子简单变形就可以得到本例,使用了CookieJar的子类MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你就能明白:

CookieJar是没有保存save属性的~
save()这个方法中:ignore_discard的意思是即使cookies将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行之后,cookies将被保存到cookie.txt文件中,我们查看一下内容:

这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问
<pre style="background-color: rgb(255, 255, 255); font-family: 宋体; font-size: 9pt;"><pre name="code" class="python">#coding=utf-8
import urllib2
import cookielib
import urllib
#第一步先给出账户密码网址准备模拟登录
postdata = urllib.urlencode({
'stuid': '1605122162',
'pwd': 'xxxxxxxxx'#密码这里就不泄漏啦,嘿嘿嘿
})
loginUrl = 'http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp'# 登录教务系统的URL,成绩查询网址
# 第二步模拟登陆并保存登录的cookie
filename = 'cookie.txt' #创建文本保存cookie
mycookie = cookielib.MozillaCookieJar(filename) # 声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(mycookie)) #定义这个opener,对象是cookie
result = opener.open(loginUrl, postdata)
mycookie.save(ignore_discard=True, ignore_expires=True)# 保存cookie到cookie.txt中
# 第三步利用cookie请求访问另一个网址,教务系统总址
gradeUrl = 'http://ids.xidian.edu.cn/authserver/login?service' #只要是帐号密码一样的网址就可以, 请求访问成绩查询网址
result = opener.open(gradeUrl)
print result.read()</pre><br>
<pre></pre>
<pre></pre>
<p></p>
<pre></pre>
<pre></pre>
创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
<p></p>
<p><br>
</p>
<p>核心思想:创建opener,包含了cookie的内容。之后在利用opener时,就会自动使用原先保存的cookie.<br>
<br>
</p>
</pre>
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-
python模拟登陆阿里妈妈生成商品推广链接
淘宝官方有获取商品推广链接的API,但该API属于增值API 普通开发者没有调用权限 需要申请开通 备注:登陆采用的是阿里妈妈账号登陆非淘宝账号登陆 复制代码 代码如下: #coding:utf-8__author__ = 'liukoo'import urllib,urllib2,cookielib,refrom hashlib import md5class alimama: def __init__(self): self.header = {'User-Agent':
-

Python模拟登陆淘宝并统计淘宝消费情况的代码实例分享
支付宝十年账单上的数字有点吓人,但它统计的项目太多,只是想看看到底单纯在淘宝上支出了多少,于是写了段脚本,统计任意时间段淘宝订单的消费情况,看那结果其实在淘宝上我还是相当节约的说. 脚本的主要工作是模拟了浏览器登录,解析"已买到的宝贝"页面以获得指定的订单及宝贝信息. 使用方法见代码或执行命令加参数-h,另外需要BeautifulSoup4支持,BeautifulSoup的官方项目列表页:https://www.crummy.com/software/BeautifulSoup/bs4
-
python模拟登陆Tom邮箱示例分享
复制代码 代码如下: def loginTom(username, password): url1 = ''' http://login.mail.tom.com/cgi/login ''' values = { 'type' : '0', 'user' : '%s' % username, 'in_username' : '%s@tom.com' % username, 'pass' : '%s' % password, 'style' : '21', 'verifycookie'
-
Python模拟登陆实现代码
下面分享一个使用Python进行网站模拟登陆的小例子. 原理 使用Cookie技术,绕开网站登录验证.要使用到cookielib库.流程: 创建一个保存Cookie的容器,可选的有CookieJar,FileCookieJar,MozillaCookieJar,LWPCookieJar.其相互之间的关系是CookieJar --派生-->FileCookieJar --派生-–>MozillaCookieJar和LWPCookieJar. 然后创建一个处理Cookie的处理器handler.通
-
Python 模拟登陆的两种实现方法
Python 模拟登陆的两种实现方法 有时候我们的抓取项目时需要登陆到某个网站上,才能看见某些内容的,所以模拟登陆功能就必不可少了,散仙这次写的文章,主要有2个例子,一个是普通写法写的,另外一个是基于面向对象写的. 模拟登陆的重点,在于找到表单真实的提交地址,然后携带cookie,post数据即可,只要登陆成功,我们就可以访问其他任意网页,从而获取网页内容. 方式一: import urllib.request import urllib.parse import http.cookiejar
-
分享一个常用的Python模拟登陆类
代码非常简单,而且注释也很详细,这里就不多废话了 tools.py # -*- coding:utf8 -*- ''' # ============================================================================= # FileName: tools.py # Desc: 模拟浏览器 # Author: cosven # Email: yinshaowen241@gmail.com # HomePage: www.cosven.co
-
Python使用Srapy框架爬虫模拟登陆并抓取知乎内容
一.Cookie原理 HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括: Cookie名字(Name)Cookie的值(Value) Cookie的过期时间(Expires/Max-Age) Cookie作用路径(Path) Cookie所在域名(Domain),使用Cookie进行安全连接(Secure) 前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大
-
Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的文章,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了一下python模拟登陆,网上关于这部分的资料很多,很多demo都是登陆知乎的,原因是知乎的登陆比较简单,只需要post几个参数,保存cookie.而且还没有进行加密,很适合用来做教学.我也是是新手,一点点的摸索终于成功登陆上了知乎.就通过这篇文章分享一下学习这部分的心得,希望对那些和我一样的初学者
-
Python爬虫利用cookie实现模拟登陆实例详解
Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 举个例子,某些网站是需要登录后才能得到你想要的信息的,不登陆只能是游客模式,那么我们可以利用Urllib2库保存我们以前登录过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取.理解cookie主要是为我们快捷模拟登录抓取目标网页做出准备. 我之前的帖子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有ur
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
-
基于python 二维数组及画图的实例详解
1.二维数组取值 注:不管是二维数组,还是一维数组,数组里的数据类型要一模一样,即若是数值型,全为数值型 #二维数组 import numpy as np list1=[[1.73,1.68,1.71,1.89,1.78], [54.4,59.2,63.6,88.4,68.7]] list3=[1.73,1.68,1.71,1.89,1.78] list4=[54.4,59.2,63.6,88.4,68.7] list5=np.array([1.73,1.68,1.71,1.89,1.78])
-
对python判断是否回文数的实例详解
设n是一任意自然数.若将n的各位数字反向排列所得自然数n1与n相等,则称n为一回文数.例如,若n=1234321,则称n为一回文数:但若n=1234567,则n不是回文数. 上面的解释就是说回文数和逆序后的结果是相等的.这就是判断一个数值是否是回文数的标准. 代码也是根据这个思路来实现的. # -*- coding: utf-8 -*- """ Created on Sun Aug 5 09:01:38 2018 @author: FanXiaoLei ""
-
对python requests发送json格式数据的实例详解
requests是常用的请求库,不管是写爬虫脚本,还是测试接口返回数据等.都是很简单常用的工具. 这里就记录一下如何用requests发送json格式的数据,因为一般我们post参数,都是直接post,没管post的数据的类型,它默认有一个类型的,貌似是 application/x-www-form-urlencoded. 但是,我们写程序的时候,最常用的接口post数据的格式是json格式.当我们需要post json格式数据的时候,怎么办呢,只需要添加修改两处小地方即可. 详见如下代码: i
-
Python 异步协程函数原理及实例详解
这篇文章主要介绍了Python 异步协程函数原理及实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一. asyncio 1.python3.4开始引入标准库之中,内置对异步io的支持 2.asyncio本身是一个消息循环 3.步骤: (1)创建消息循环 (2)把协程导入 (3)关闭 4.举例: import threading # 引入异步io包 import asyncio # 使用协程 @ asyncio.coroutine def
-
Python元组拆包和具名元组解析实例详解
前言 在Python中元组是一个相较于其他语言比较特别的一个内置序列类型.有些python入门教程把元组成为"不可变的列表",这种说法是不完备的,其并没有完整的概括元组的特点.除了用作不可变的列表,它还可以用于没有字段名的数据记录.下面的内容就围绕元组作为数据记录属性展开,并介绍带字段名的具名元组函数namedtuple,列表属性不再本文中叙述. 元组对于数据的记录 元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置,正是这个位置信息给数据赋予了意义. 下面的一段代码就演
-
python里使用正则表达式的组嵌套实例详解
python里使用正则表达式的组嵌套实例详解 由于组本身是一个完整的正则表达式,所以可以将组嵌套在其他组中,以构建更复杂的表达式.下面的例子,就是进行组嵌套的例子: #python 3.6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re def test_patterns(text, patterns): """Given source text and a list of pa
-
微信小程序 利用css实现遮罩效果实例详解
微信小程序 利用css实现遮罩效果实例详解 实现效果图: 如图所示,使用css实现小程序的遮罩效果,代码如下 js文件代码: //index.js //获取应用实例 var app = getApp() Page({ data: { flag: false }, a: function(){ this.setData({flag: false}) }, b: function(){ this.setData({flag: true}) } }) wxss文件代码: .b1{position:fi