python实现Floyd算法
下面是用Python实现Floyd算法的代码,供大家参考,具体内容如下
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 13 14:56:37 2017
@author: linzr
"""
## 表示无穷大
INF_val = 9999
class Floyd_Path():
def __init__(self, node, node_map, path_map):
self.node = node
self.node_map = node_map
self.node_length = len(node_map)
self.path_map = path_map
self._init_Floyd()
def __call__(self, from_node, to_node):
self.from_node = from_node
self.to_node = to_node
return self._format_path()
def _init_Floyd(self):
for k in range(self.node_length):
for i in range(self.node_length):
for j in range(self.node_length):
tmp = self.node_map[i][k] + self.node_map[k][j]
if self.node_map[i][j] > tmp:
self.node_map[i][j] = tmp
self.path_map[i][j] = self.path_map[i][k]
print '_init_Floyd is end'
def _format_path(self):
node_list = []
temp_node = self.from_node
obj_node = self.to_node
print("the shortest path is: %d")%(self.node_map[temp_node][obj_node])
node_list.append(self.node[temp_node])
while True:
node_list.append(self.node[self.path_map[temp_node][obj_node]])
temp_node = self.path_map[temp_node][obj_node]
if temp_node == obj_node:
break;
return node_list
def set_node_map(node_map, node, node_list, path_map):
for i in range(len(node)):
## 对角线为0
node_map[i][i] = 0
for x, y, val in node_list:
node_map[node.index(x)][node.index(y)] = node_map[node.index(y)][node.index(x)] = val
path_map[node.index(x)][node.index(y)] = node.index(y)
path_map[node.index(y)][node.index(x)] = node.index(x)
if __name__ == "__main__":
node = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
node_list = [('A', 'F', 9), ('A', 'B', 10), ('A', 'G', 15), ('B', 'F', 2),
('G', 'F', 3), ('G', 'E', 12), ('G', 'C', 10), ('C', 'E', 1),
('E', 'D', 7)]
## node_map[i][j] 存储i到j的最短距离
node_map = [[INF_val for val in xrange(len(node))] for val in xrange(len(node))]
## path_map[i][j]=j 表示i到j的最短路径是经过顶点j
path_map = [[0 for val in xrange(len(node))] for val in xrange(len(node))]
## set node_map
set_node_map(node_map, node, node_list, path_map)
## select one node to obj node, e.g. A --> D(node[0] --> node[3])
from_node = node.index('A')
to_node = node.index('E')
Floydpath = Floyd_Path(node, node_map, path_map)
path = Floydpath(from_node, to_node)
print path
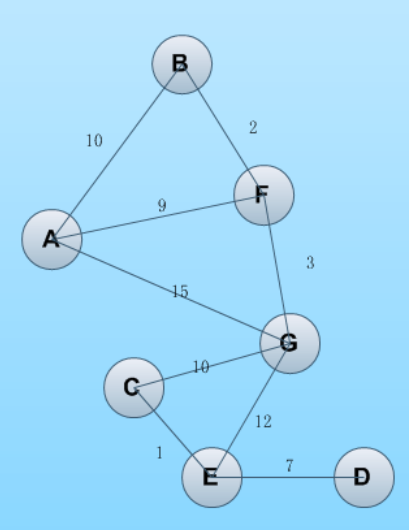
运行结果为:
the shortest path is: 23
['A', 'F', 'G', 'C', 'E']
相关推荐
-

朴素贝叶斯算法的python实现方法
本文实例讲述了朴素贝叶斯算法的python实现方法.分享给大家供大家参考.具体实现方法如下: 朴素贝叶斯算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类别问题 缺点:对输入数据的准备方式敏感 适用数据类型:标称型数据 算法思想: 比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的是这个邮件中的词的分布,那么我们还要知道:垃圾邮件中某些词的出现是多少,就可以利用贝叶斯定理得到. 朴素贝叶斯分类器中的一个假设是:每个特征同等重要 函数 loadDataSet() 创建数据集,这里的数据集
-
Python实现的Kmeans++算法实例
1.从Kmeans说起 Kmeans是一个非常基础的聚类算法,使用了迭代的思想,关于其原理这里不说了.下面说一下如何在matlab中使用kmeans算法. 创建7个二维的数据点: 复制代码 代码如下: x=[randn(3,2)*.4;randn(4,2)*.5+ones(4,1)*[4 4]]; 使用kmeans函数: 复制代码 代码如下: class = kmeans(x, 2); x是数据点,x的每一行代表一个数据:2指定要有2个中心点,也就是聚类结果要有2个簇. class将是一个具有7
-
Python算法之栈(stack)的实现
本文以实例形式展示了Python算法中栈(stack)的实现,对于学习数据结构域算法有一定的参考借鉴价值.具体内容如下: 1.栈stack通常的操作: Stack() 建立一个空的栈对象 push() 把一个元素添加到栈的最顶层 pop() 删除栈最顶层的元素,并返回这个元素 peek() 返回最顶层的元素,并不删除它 isEmpty() 判断栈是否为空 size() 返回栈中元素的个数 2.简单案例以及操作结果: Stack Operation Stack Contents Return
-
python冒泡排序算法的实现代码
1.算法描述:(1)共循环 n-1 次(2)每次循环中,如果 前面的数大于后面的数,就交换(3)设置一个标签,如果上次没有交换,就说明这个是已经好了的. 2.python冒泡排序代码 复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*- def bubble(l): flag = True for i in range(len(l)-1, 0, -1): if flag: flag = False
-
python k-近邻算法实例分享
简单说明 这个算法主要工作是测量不同特征值之间的距离,有个这个距离,就可以进行分类了. 简称kNN. 已知:训练集,以及每个训练集的标签. 接下来:和训练集中的数据对比,计算最相似的k个距离.选择相似数据中最多的那个分类.作为新数据的分类. python实例 复制代码 代码如下: # -*- coding: cp936 -*- #win系统中应用cp936编码,linux中最好还是utf-8比较好.from numpy import *#引入科学计算包import operator #经典pyt
-
python编写的最短路径算法
一心想学习算法,很少去真正静下心来去研究,前几天趁着周末去了解了最短路径的资料,用python写了一个最短路径算法.算法是基于带权无向图去寻找两个点之间的最短路径,数据存储用邻接矩阵记录.首先画出一幅无向图如下,标出各个节点之间的权值. 其中对应索引: A --> 0 B--> 1 C--> 2 D-->3 E--> 4 F--> 5 G--> 6 邻接矩阵表示无向图: 算法思想是通过Dijkstra算法结合自身想法实现的.大致思路是:从起始点开始,搜索周围的路径
-
python实现RSA加密(解密)算法
RSA是目前最有影响力的公钥加密算法,它能够抵抗到目前为止已知的绝大多数密码攻击,已被ISO推荐为公钥数据加密标准. 今天只有短的RSA钥匙才可能被强力方式解破.到2008年为止,世界上还没有任何可靠的攻击RSA算法的方式.只要其密钥的长度足够长,用RSA加密的信息实际上是不能被解破的.但在分布式计算和量子计算机理论日趋成熟的今天,RSA加密安全性受到了挑战. RSA算法基于一个十分简单的数论事实:将两个大素数相乘十分容易,但是想要对其乘积进行因式分解却极其困难,因此可以将乘积公开作为加密密钥.
-
python使用rsa加密算法模块模拟新浪微博登录
PC登录新浪微博时,在客户端用js预先对用户名.密码都进行了加密,而且在POST之前会GET一组参数,这也将作为POST_DATA的一部分.这样,就不能用通常的那种简单方法来模拟POST登录(比如人人网). 通过爬虫获取新浪微博数据,模拟登录是必不可少的. 1.在提交POST请求之前,需要GET获取四个参数(servertime,nonce,pubkey和rsakv),不是之前提到的只是获取简单的servertime,nonce,这里主要是由于js对用户名.密码加密方式改变了. 1.1 由于加密
-
用Python实现通过哈希算法检测图片重复的教程
Iconfinder 是一个图标搜索引擎,为设计师.开发者和其他创意工作者提供精美图标,目前托管超过 34 万枚图标,是全球最大的付费图标库.用户也可以在 Iconfinder 的交易板块上传出售原创作品.每个月都有成千上万的图标上传到Iconfinder,同时也伴随而来大量的盗版图.Iconfinder 工程师 Silviu Tantos 在本文中提出一个新颖巧妙的图像查重技术,以杜绝盗版. 我们将在未来几周之内推出一个检测上传图标是否重复的功能.例如,如果用户下载了一个图标然后又试图通过上传
-
数据挖掘之Apriori算法详解和Python实现代码分享
关联规则挖掘(Association rule mining)是数据挖掘中最活跃的研究方法之一,可以用来发现事情之间的联系,最早是为了发现超市交易数据库中不同的商品之间的关系.(啤酒与尿布) 基本概念 1.支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数.例如:support({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/数据记录数 = 3/5=60%. 2.自信度的定义:confidence(X-->