Python中正则表达式小结
注意:本文基于Python2.4完成;如果看到不明白的词汇请记得百度谷歌或维基,whatever。
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程:

正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:
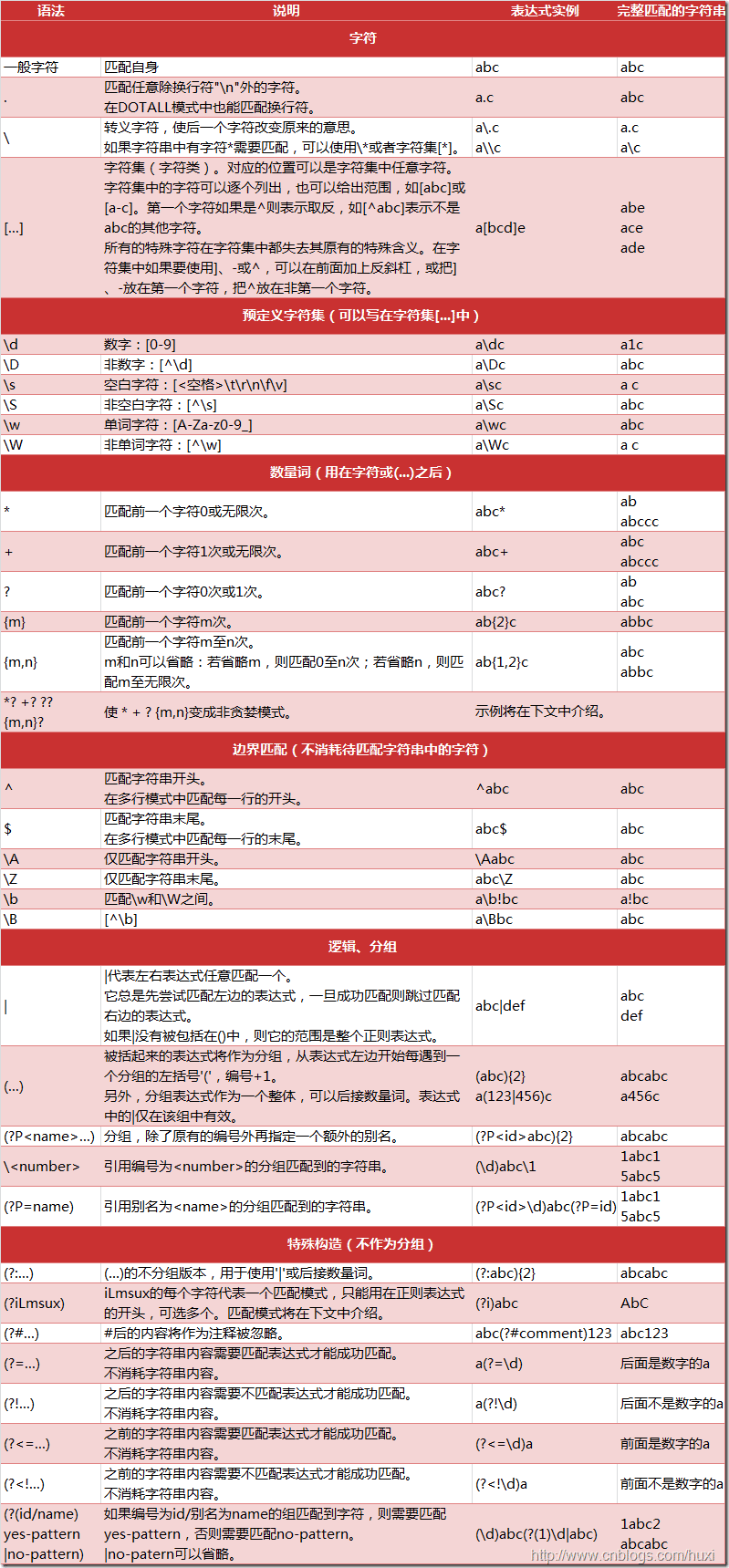
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!')
if match:
# 使用Match获得分组信息
print match.group()
### 输出 ###
# hello
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图) S(DOTALL): 点任意匹配模式,改变'.'的行为 L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定 U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性 X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
a = re.compile(r"""\d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X) b = re.compile(r"\d+\.\d*")
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
m = re.match(r'hello', 'hello world!') print m.group()
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
string: 匹配时使用的文本。 re: 匹配时使用的Pattern对象。 pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。 endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。 lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。 lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 span([group]):
返回(start(group), end(group))。 expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
import re
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
print "m.string:", m.string
print "m.re:", m.re
print "m.pos:", m.pos
print "m.endpos:", m.endpos
print "m.lastindex:", m.lastindex
print "m.lastgroup:", m.lastgroup
print "m.group(1,2):", m.group(1, 2)
print "m.groups():", m.groups()
print "m.groupdict():", m.groupdict()
print "m.start(2):", m.start(2)
print "m.end(2):", m.end(2)
print "m.span(2):", m.span(2)
print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')
### output ###
# m.string: hello world!
# m.re: <_sre.SRE_Pattern object at 0x016E1A38>
# m.pos: 0
# m.endpos: 12
# m.lastindex: 3
# m.lastgroup: sign
# m.group(1,2): ('hello', 'world')
# m.groups(): ('hello', 'world', '!')
# m.groupdict(): {'sign': '!'}
# m.start(2): 6
# m.end(2): 11
# m.span(2): (6, 11)
# m.expand(r'\2 \1\3'): world hello!
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。 flags: 编译时用的匹配模式。数字形式。 groups: 表达式中分组的数量。 groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
import re
p = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)
print "p.pattern:", p.pattern
print "p.flags:", p.flags
print "p.groups:", p.groups
print "p.groupindex:", p.groupindex
### output ###
# p.pattern: (\w+) (\w+)(?P<sign>.*)
# p.flags: 16
# p.groups: 3
# p.groupindex: {'sign': 3}
实例方法[ | re模块方法]:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。 search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'world')
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = pattern.search('hello world!')
if match:
# 使用Match获得分组信息
print match.group()
### 输出 ###
# world
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'\d+')
print p.split('one1two2three3four4')
### output ###
# ['one', 'two', 'three', 'four', '']
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
import re
p = re.compile(r'\d+')
print p.findall('one1two2three3four4')
### output ###
# ['1', '2', '3', '4']
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
import re
p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print m.group(),
### output ###
# 1 2 3 4
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
import re p = re.compile(r'(\w+) (\w+)') s = 'i say, hello world!' print p.sub(r'\2 \1', s) def func(m): return m.group(1).title() + ' ' + m.group(2).title() print p.sub(func, s) ### output ### # say i, world hello! # I Say, Hello World!
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print p.subn(r'\2 \1', s)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print p.subn(func, s)
### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
相关推荐
-
Python中staticmethod和classmethod的作用与区别
一般来说,要使用某个类的方法,需要先实例化一个对象再调用方法. 而使用@staticmethod或@classmethod,就可以不需要实例化,直接类名.方法名()来调用. 这有利于组织代码,把某些应该属于某个类的函数给放到那个类里去,同时有利于命名空间的整洁. 既然@staticmethod和@classmethod都可以直接类名.方法名()来调用,那他们有什么区别呢 从它们的使用上来看 @staticmethod不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样. @clas
-
python如何发布自已pip项目的方法步骤
前言 因为自已平时会把一个常用到逻辑写成一个工具python脚本,像关于时间字符串处理,像关于路径和文件夹遍历什么的工具.每一次新建一个项目的时候都要把这些工具程序复制到每个项目中,换一个电脑后还要从github生新下载后再复制到项目中,实在太麻烦.最后想想,还是建一个自已的pip项目会比较好. 环境准备 要用 pip 发布 python 程序,首先当然是要安装 Python 和 pip 这两个软件了,以 Ubuntu 16.04 为例: $ sudo apt update $ sudo apt
-

不知道这5种下划线的含义,你就不算真的会Python!
什么是 Python? Python 之父 Guido van Rossum 说:Python是一种高级程序语言,其核心设计哲学是代码可读性和语法,能够让程序员用很少的代码来表达自己的想法. 对于我来说,学习 Python 的首要原因是,Python 是一种可以优雅编程的语言.它能够简单自然地写出代码和实现我的想法. 另一个原因是我们可以将 Python 用在很多地方:人工智能.数据科学.Web 开发和机器学习等都可以使用 Python 来开发. 国庆期间后台有小伙伴留言问我:"Python变量
-
10 行 Python 代码教你自动发送短信(不想回复工作邮件妙招)
最近工作上有个需求,当爬虫程序遇到异常的时候,需要通知相应的人员进行修复.如果是国外可能是通过邮件的方式来通知,但国内除了万年不变的 qq 邮箱,大部分人都不会去再申请其他的账号,qq 邮箱也是闲的蛋疼的时候才会瞄一眼.你还记得上次看邮箱的内容是什么时候吗? 所以在国内最好的通知方式是通过手机短信,今天就教大家利用 python 10 行代码实现短信发送. Twilio 短信代理服务已经有非常多成熟的方案,比如国内的阿里云.这次我介绍的是国外的一个代理商「Twilio」,使用邮箱注册即送 15
-
对Python中的@classmethod用法详解
在Python面向对象编程中的类构建中,有时候会遇到@classmethod的用法. 总感觉有这种特殊性说明的用法都是高级用法,在我这个层级的水平中一般是用不到的. 不过还是好奇去查了一下. 大致可以理解为:使用了@classmethod修饰的方法是类专属的,而且是可以通过类名进行调用的.为了能够展示其与一般方法的差异,写一段简单的代码如下: class DemoClass: @classmethod def classPrint(self): print("class method"
-
基于python中staticmethod和classmethod的区别(详解)
例子 class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A(
-
Python中几种属性访问的区别与用法详解
起步 在Python中,对于一个对象的属性访问,我们一般采用的是点(.)属性运算符进行操作.例如,有一个类实例对象foo,它有一个name属性,那便可以使用foo.name对此属性进行访问.一般而言,点(.)属性运算符比较直观,也是我们经常碰到的一种属性访问方式. python的提供一系列和属性访问有关的特殊方法: __get__ , __getattr__ , __getattribute__ , __getitem__ .本文阐述它们的区别和用法. 属性的访问机制 一般情况下,属性访问的默认
-
python的staticmethod与classmethod实现实例代码
本文源于一时好奇,想要弄清出python的staticmethod()这一builtin方法的实现,查了一些资料(主要是python官方手册了)汇集于此 python在类中,有三种调用method的方法:普通method,staticmethod和classmethod 前两个应该都好理解,classmethod就是在调用这个函数的时候,会把调用对象的class object对象隐式地传进去.咦?这个class object不是一个类型?No,在python里面,class object不像静态
-
Python 变量类型详解
变量存储在内存中的值.这就意味着在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中. 因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符. 变量赋值 Python 中的变量赋值不需要类型声明. 每个变量在内存中创建,都包括变量的标识,名称和数据这些信息. 每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建. 等号(=)用来给变量赋值. 等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值. 例
-
Python中正则表达式小结
注意:本文基于Python2.4完成:如果看到不明白的词汇请记得百度谷歌或维基,whatever. 1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大.得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同:但不用担心,不被支持的语法通常是不常用的部分.如果已经在其他语言里使用过正
-
Python中正则表达式match()、search()函数及match()和search()的区别详解
match()和search()都是python中的正则匹配函数,那这两个函数有何区别呢? match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none 例如: #! /usr/bin/env python # -*- coding=utf-8 -*- import re text = 'pythontab' m = re.ma
-
Python中正则表达式的详细教程
1.了解正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了. 正则表达式的大致匹配过程是: 1.依次拿出表达式和文本中的字符比较, 2.如果每
-
Python中正则表达式的巧妙使用一文包你必掌握正则
前言 正则表达式就是从字符串中发现规律,并通过"抽象"的符号表达出来.打个比方,对于2,5,10,17,26,37这样的数字序列,如何计算第7个值,肯定要先找该序列的规律,然后用n2+1这个表达式来描述其规律,进而得到第7个值为50.对于需要匹配的字符串来说,同样把发现规律作为第一步,本文主要使用正则表达式完成字符串的查询匹配.替换匹配和分割匹配. 常用的正则符号 在进入字符串的匹配之前,先来了解一下都有哪些常用的正则符号,见下表所示: 如果读者能够比较熟练地掌握上表中的内容,相信在字
-
python中正则表达式 re.findall 用法
Python 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数. 本文主要给大家介绍
-
Python中正则表达式对单个字符,多个字符和匹配边界等使用
Regular Expression,正则表达式,又称正规表示式.正规表示法.正则表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),是计算机科学的一个概念.正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配.在很多文本编辑器里,正则表达式通常被用来检索.替换那些匹配某个模式的文本. Python 自1.5版本起增加了re 模块.re 模块使 Python 语言拥有全部的正则表达式功能. 1.
-
python中正则表达式findall的用法实例
正则口径:知道前后取中间,如果最后$结束 python中则这表达式的方法通常由re.match re.search re.findall re.findall匹配的时候,会把结果放到list返回,如果没有匹配到返回空list不会报错 import re s1=re.compile('\d+') # 匹配数字 r1=s1.findall('sahduasu27bhsagd7236vbcsahg923') print(r1) s2=re.compile('\d+') r2=re.findall(s2
-
Python中正则表达式详解
基础篇 正则表达式在python中运用的非常多,因为他可以进行任意的匹配,可以匹配我们想要提取的信息.当我们接触正则的时候你就会知道正则的强大.正则有一个库re 在一些工程中我们会经常调用正则的库来做与匹配相关的问题. 字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在.比如判断一个字符串是否是合法的Email地址,虽然可以编程提取 @ 前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用. 正则表达式是一种用来匹配字符串的强有力的武器.它的设计思
-
python中正则表达式的使用详解
从学习Python至今,发现很多时候是将Python作为一种工具.特别在文本处理方面,使用起来更是游刃有余. 说到文本处理,那么正则表达式必然是一个绝好的工具,它能将一些繁杂的字符搜索或者替换以非常简洁的方式完成. 我们在处理文本的时候,或是查询抓取,或是替换. 一.查找 如果你想自己实现这样的功能模块,输入某一个ip地址,得到这个ip地址所在地区的详细信息. 然后你发现http://ip138.com 可以查出很详细的数据 但是人家没有提供api供外部调用,但是我们可以通过代码模拟查询然后对结
-
python中正则表达式的使用方法
本文主要关于python的正则表达式的符号与方法. findall: 找寻所有匹配,返回所有组合的列表 search: 找寻第一个匹配并返回 sub: 替换符合规律的内容,并返回替换后的内容 .:匹配除了换行符以外的任意字符 a = 'xy123' b = re.findall('x...',a) print(b) # ['xy12'] *:匹配前一个字符0次或者无限次 a = 'xyxy123' b = re.findall('x*',a) print(b) # ['x', '', 'x',