Java数据结构之图(动力节点Java学院整理)
1,摘要:
本文章主要讲解学习如何使用JAVA语言以邻接表的方式实现了数据结构---图(Graph)。从数据的表示方法来说,有二种表示图的方式:一种是邻接矩阵,其实是一个二维数组;一种是邻接表,其实是一个顶点表,每个顶点又拥有一个边列表。下图是图的邻接表表示。
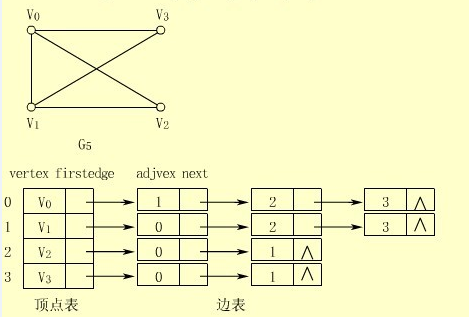
从图中可以看出,图的实现需要能够表示顶点表,能够表示边表。邻接表指是的哪部分呢?每个顶点都有一个邻接表,一个指定顶点的邻接表中,起始顶点表示边的起点,其他顶点表示边的终点。这样,就可以用邻接表来实现边的表示了。如顶点V0的邻接表如下:

与V0关联的边有三条,因为V0的邻接表中有三个顶点(不考虑V0)。
2,具体分析
先来分析边表:
在图中如何来表示一条边?很简单,就是:起始顶点指向结束顶点、就是顶点对<startVertex, endVertex>。在这里,为了考虑边带有权值的情况,单独设计一个类Edge.java,作为Vertex.java的内部类,Edge.java如下:
protected class Edge implements java.io.Serializable {
private VertexInterface<T> vertex;// 终点
private double weight;//权值
Edge类中只有两个属性,vertex 用来表示顶点,该顶点是边的终点。weight 表示边的权值。若不考虑带权的情况,就不需要weight属性,那么可以直接定义一个顶点列表 来存放 终点 就可以表示边了。这是因为:这些属性是定义在Vertex.java中,而Vertex本身就表示顶点,如果在Vertex内部定义一个List存放终点,那么该List再加上Vertex所表示的顶点本身,就可以表示与起点邻接的各个点了(称之为这个 起点的邻接表)。这样的边的特点是:边的所有的起始点都相同。
但是为了表示带权的边,因此,新增加weight属性,并用类Edge来封装,这样不管是带权的边还是不带权的边都可以用同一个Edge类来表示。不带权的边将weight赋值为0即可。
再分析顶点表:
定义接口VertexInterface<T>表示顶点的接口,所有的顶点都需要实现这个接口,该接口中定义了顶点的基本操作,如:判断顶点是否有邻接点,将顶点与另一个顶点连接起来...。其次,顶点表中的每个顶点有两个域,一个是标识域:V0,V1,V2,V3 。一个是指针域,指针域指向一个"单链表"。综上,设计一个类Vertex.java 用来表示顶点,其数据域如下:
class Vertex<T> implements VertexInterface<T>, java.io.Serializable {
private T label;//标识标点,可以用不同类型来标识顶点如String,Integer....
private List<Edge> edgeList;//到该顶点邻接点的边,实际以java.util.LinkedList存储
private boolean visited;//标识顶点是否已访问
private VertexInterface<T> previousVertex;//该顶点的前驱顶点
private double cost;//顶点的权值,与边的权值要区别开来
现在一一解释Vertex类中定义的各个属性:
label : 用来标识顶点,如图中的 V0,V1,V2,V3,在实际代码中,V0...V3 以字符串的形式表示,就可以用来标识不同的顶点了。
因此,需要在Vertex类中添加获得顶点标识的方法---getLabel()
public T getLabel() {
return label;
}
edgeList : 存放与该顶点关联的边。从上面Edge.java中可以看到,Edge的实质是“顶点”,因为,Edge类除去wight属性,就只剩表示顶点的vertex属性了。借助edgeList,当给定一个顶点时,就可以访问该顶点的所有邻接点。因此,Vertex.java中就需要实现根据edgeList中存放的边来遍历 某条边的终点(也即相应顶点的各个邻接点) 的迭代器了。
public Iterator<VertexInterface<T>> getNeighborInterator() {
return new NeighborIterator();
}
迭代器的实现如下:
/**Task: 遍历该顶点邻接点的迭代器--为 getNeighborInterator()方法 提供迭代器
* 由于顶点的邻接点以边的形式存储在java.util.List中,因此借助List的迭代器来实现
* 由于顶点的邻接点由Edge类封装起来了--见Edge.java的定义的第一个属性
* 因此,首先获得遍历Edge对象的迭代器,再根据获得的Edge对象解析出邻接点对象
*/
private class NeighborIterator implements Iterator<VertexInterface<T>>{
Iterator<Edge> edgesIterator;
private NeighborIterator() {
edgesIterator = edgeList.iterator();//获得遍历edgesList 的迭代器
}
@Override
public boolean hasNext() {
return edgesIterator.hasNext();
}
@Override
public VertexInterface<T> next() {
VertexInterface<T> nextNeighbor = null;
if(edgesIterator.hasNext()){
Edge edgeToNextNeighbor = edgesIterator.next();//LinkedList中存储的是Edge
nextNeighbor = edgeToNextNeighbor.getEndVertex();//从Edge对象中取出顶点
}
else
throw new NoSuchElementException();
return nextNeighbor;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
visited : 之所以给每个顶点设置一个用来标记它是否被访问的属性,是因为:实现一个数据结构,是要用它去完成某些功能的,如遍历、查找…… 而在图的遍历过程中,就需要标记某个顶点是否被访问了,因此:设置该属性以便实现这些功能。那么,也就需要定义获取顶点是否被访问的isVisited()方法了。
public boolean isVisited() {
return visited;
}
previousVertex 属性 ,在求图中某两个顶点之间的最短路径时,在从起始顶点遍历过程中,需要记录下遍历到某个顶点时的前驱顶点, previousVertex 属性就派上用场了。因此,需要有判断和获取顶点的前驱顶点的方法:
public boolean hasPredecessor() {//判断顶点是否有前驱顶点
return this.previousVertex != null;
}
public VertexInterface<T> getPredecessor() {//获得前驱顶点
return this.previousVertex;
}
cost 属性:用来表示顶点的权值。注意,顶点的权值与边的权值是不同的。比如求无权图(默认是边不带权值)的最短路径时,如何求出顶点A到顶点B的最短的路径?由定义,该最短路径其实就是A走到B经历的最少边数目。因此,就可以用 cost 属性来记录A到B之间的距离是多少了。比如说,A 先走到 C 再走到B;初始时,A的 cost = 0,由于 A 是 C 的前驱,A到B需要经历C,C 的 cost 就是 c.previousVertex.cost + 1,直至 B,就可以求出 A 到 B 的最短路径了。详细算法及实现将会在第二篇博客中给出。
因此,针对 cost 属性,Vertex.java需要实现的方法如下:
public void setCost(double newCost) {
cost = newCost;
}
public double getCost() {
return cost;
}
3,总结:
从上可以看出,设计一个数据结构时,该数据结构需要包含哪些属性不是随意的,而是先确定该数据结构需要完成哪些功能(如,图的DFS、BFS、拓扑排序、最短路径),这些功能的实现需要借助哪些属性(如,求最短路径需要记录每个顶点的前驱顶点,就需要 previousVertex)。然后,去定义这些属性以及关于该属性的基本操作。设计一个合适的数据结构,当借助该数据结构来实现算法时,可以有效地降低算法的实现难度和复杂度!
Vertex.java的完整代码如下:
package graph;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.NoSuchElementException;
class Vertex<T> implements VertexInterface<T>, java.io.Serializable {
private T label;//标识标点,可以用不同类型来标识顶点如String,Integer....
private List<Edge> edgeList;//到该顶点邻接点的边,实际以java.util.LinkedList存储
private boolean visited;//标识顶点是否已访问
private VertexInterface<T> previousVertex;//该顶点的前驱顶点
private double cost;//顶点的权值,与边的权值要区别开来
public Vertex(T vertexLabel){
label = vertexLabel;
edgeList = new LinkedList<Edge>();//是Vertex的属性,说明每个顶点都有一个edgeList用来存储所有与该顶点关系的边
visited = false;
previousVertex = null;
cost = 0;
}
/**
*Task: 这里用了一个单独的类来表示边,主要是考虑到带权值的边
*可以看出,Edge类封装了一个顶点和一个double类型变量
*若不需要考虑权值,可以不需要单独创建一个Edge类来表示边,只需要一个保存顶点的列表即可
* @author hapjin
*/
protected class Edge implements java.io.Serializable {
private VertexInterface<T> vertex;// 终点
private double weight;//权值
//Vertex 类本身就代表顶点对象,因此在这里只需提供 endVertex,就可以表示一条边了
protected Edge(VertexInterface<T> endVertex, double edgeWeight){
vertex = endVertex;
weight = edgeWeight;
}
protected VertexInterface<T> getEndVertex(){
return vertex;
}
protected double getWeight(){
return weight;
}
}
/**Task: 遍历该顶点邻接点的迭代器--为 getNeighborInterator()方法 提供迭代器
* 由于顶点的邻接点以边的形式存储在java.util.List中,因此借助List的迭代器来实现
* 由于顶点的邻接点由Edge类封装起来了--见Edge.java的定义的第一个属性
* 因此,首先获得遍历Edge对象的迭代器,再根据获得的Edge对象解析出邻接点对象
*/
private class NeighborIterator implements Iterator<VertexInterface<T>>{
Iterator<Edge> edgesIterator;
private NeighborIterator() {
edgesIterator = edgeList.iterator();//获得遍历edgesList 的迭代器
}
@Override
public boolean hasNext() {
return edgesIterator.hasNext();
}
@Override
public VertexInterface<T> next() {
VertexInterface<T> nextNeighbor = null;
if(edgesIterator.hasNext()){
Edge edgeToNextNeighbor = edgesIterator.next();//LinkedList中存储的是Edge
nextNeighbor = edgeToNextNeighbor.getEndVertex();//从Edge对象中取出顶点
}
else
throw new NoSuchElementException();
return nextNeighbor;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
/**Task: 生成一个遍历该顶点所有邻接边的权值的迭代器
* 权值是Edge类的属性,因此先获得一个遍历Edge对象的迭代器,取得Edge对象,再获得权值
* @author hapjin
*
* @param <Double> 权值的类型
*/
private class WeightIterator implements Iterator{//这里不知道为什么,用泛型报编译错误???
private Iterator<Edge> edgesIterator;
private WeightIterator(){
edgesIterator = edgeList.iterator();
}
@Override
public boolean hasNext() {
return edgesIterator.hasNext();
}
@Override
public Object next() {
Double result;
if(edgesIterator.hasNext()){
Edge edge = edgesIterator.next();
result = edge.getWeight();
}
else throw new NoSuchElementException();
return (Object)result;//从迭代器中取得结果时,需要强制转换成Double
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
@Override
public T getLabel() {
return label;
}
@Override
public void visit() {
this.visited = true;
}
@Override
public void unVisit() {
this.visited = false;
}
@Override
public boolean isVisited() {
return visited;
}
@Override
public boolean connect(VertexInterface<T> endVertex, double edgeWeight) {
// 将"边"(边的实质是顶点)插入顶点的邻接表
boolean result = false;
if(!this.equals(endVertex)){//顶点互不相同
Iterator<VertexInterface<T>> neighbors = this.getNeighborInterator();
boolean duplicateEdge = false;
while(!duplicateEdge && neighbors.hasNext()){//保证不添加重复的边
VertexInterface<T> nextNeighbor = neighbors.next();
if(endVertex.equals(nextNeighbor)){
duplicateEdge = true;
break;
}
}//end while
if(!duplicateEdge){
edgeList.add(new Edge(endVertex, edgeWeight));//添加一条新边
result = true;
}//end if
}//end if
return result;
}
@Override
public boolean connect(VertexInterface<T> endVertex) {
return connect(endVertex, 0);
}
@Override
public Iterator<VertexInterface<T>> getNeighborInterator() {
return new NeighborIterator();
}
@Override
public Iterator getWeightIterator() {
return new WeightIterator();
}
@Override
public boolean hasNeighbor() {
return !(edgeList.isEmpty());//邻接点实质是存储是List中
}
@Override
public VertexInterface<T> getUnvisitedNeighbor() {
VertexInterface<T> result = null;
Iterator<VertexInterface<T>> neighbors = getNeighborInterator();
while(neighbors.hasNext() && result == null){//获得该顶点的第一个未被访问的邻接点
VertexInterface<T> nextNeighbor = neighbors.next();
if(!nextNeighbor.isVisited())
result = nextNeighbor;
}
return result;
}
@Override
public void setPredecessor(VertexInterface<T> predecessor) {
this.previousVertex = predecessor;
}
@Override
public VertexInterface<T> getPredecessor() {
return this.previousVertex;
}
@Override
public boolean hasPredecessor() {
return this.previousVertex != null;
}
@Override
public void setCost(double newCost) {
cost = newCost;
}
@Override
public double getCost() {
return cost;
}
//判断两个顶点是否相同
public boolean equals(Object other){
boolean result;
if((other == null) || (getClass() != other.getClass()))
result = false;
else
{
Vertex<T> otherVertex = (Vertex<T>)other;
result = label.equals(otherVertex.label);//节点是否相同最终还是由标识 节点类型的类的equals() 决定
}
return result;
}
}
以上所述是小编给大家介绍的Java数据结构之图(动力节点Java学院整理),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Java常见基本数据结构概览
Java数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等等的学科.在Java数据结构中最常用的类型无外乎以下几种: Map接口 请注意,Map没有继承Collection接口,Map提供key到value的映射.一个Map中不能包含相同的key,每个key只能映射一个value. Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射. List接口 List是有序的Collection,用户能
-
java数据结构与算法之快速排序详解
本文实例讲述了java数据结构与算法之快速排序.分享给大家供大家参考,具体如下: 交换类排序的另一个方法,即快速排序. 快速排序:改变了冒泡排序中一次交换仅能消除一个逆序的局限性,是冒泡排序的一种改进:实现了一次交换可消除多个逆序.通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 步骤: 1.从数列中挑出一个元素,称为 "基准"(piv
-
浅析Java 数据结构常用接口与类
Java工具包提供了强大的数据结构.在Java中的数据结构主要包括以下几种接口和类: 枚举(Enumeration) 位集合(BitSet) 向量(Vector) 栈(Stack) 字典(Dictionary) 哈希表(Hashtable) 属性(Properties) 以上这些类是传统遗留的,在Java2中引入了一种新的框架-集合框架(Collection),我们后面再讨论. 枚举(Enumeration) 枚举(Enumeration)接口虽然它本身不属于数据结构,但它在其他数据结构的范畴里
-
java数据结构与算法之插入排序详解
本文实例讲述了java数据结构与算法之插入排序.分享给大家供大家参考,具体如下: 复习之余,就将数据结构中关于排序的这块知识点整理了一下,写下来是想与更多的人分享,最关键的是做一备份,为方便以后查阅. 排序 1.概念: 有n个记录的序列{R1,R2,.......,Rn}(此处注意:1,2,n 是下表序列,以下是相同的作用),其相应关键字的序列是{K1,K2,.........,Kn}.通过排序,要求找出当前下标序列1,2,......,n的一种排列p1,p2,........pn,使得相应关键
-
java数据结构与算法之希尔排序详解
本文实例讲述了java数据结构与算法之希尔排序.分享给大家供大家参考,具体如下: 这里要介绍的是希尔排序(缩小增量排序法). 希尔排序:通过比较相距一定间隔的元素来工作:各趟比较所用的距离(增量)随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止.是插入排序的一种,是针对直接插入排序算法的改进. 算法思想:先将要排序的序列按某个增量d分成若干个子序列,对每个子序列中全部元素分别进行直接插入排序,然后再用一个较小的增量对它进行分组,在每组中再进行排序.当增量减到1时,整个要排序的数被分成一
-
java数据结构排序算法之归并排序详解
本文实例讲述了java数据结构排序算法之归并排序.分享给大家供大家参考,具体如下: 在前面说的那几种排序都是将一组记录按关键字大小排成一个有序的序列,而归并排序的思想是:基于合并,将两个或两个以上有序表合并成一个新的有序表 归并排序算法:假设初始序列含有n个记录,首先将这n个记录看成n个有序的子序列,每个子序列长度为1,然后两两归并,得到n/2个长度为2(n为奇数的时候,最后一个序列的长度为1)的有序子序列.在此基础上,再对长度为2的有序子序列进行亮亮归并,得到若干个长度为4的有序子序列.如此重
-

Java数据结构之散列表(动力节点Java学院整理)
基本概念 散列表(Hash table,也叫哈希表),是根据关键字(key value)而直接进行访问的数据结构. 说的具体点就是它通过吧key值映射到表中的一个位置来访问记录,从而加快查找的速度. 实现key值映射的函数就叫做散列函数 存放记录的数组就就叫做散列表 实现散列表的过程通常就称为散列(hashing),也就是常说的hash 散列 这里的散列的概念不仅限于数据结构了,在计算机科学领域中,散列-哈希是一种对信息的处理方法,通过某种特定的函数/算法(散列函数/hash()方法)将要检索的
-
Java数据结构之图(动力节点Java学院整理)
1,摘要: 本文章主要讲解学习如何使用JAVA语言以邻接表的方式实现了数据结构---图(Graph).从数据的表示方法来说,有二种表示图的方式:一种是邻接矩阵,其实是一个二维数组:一种是邻接表,其实是一个顶点表,每个顶点又拥有一个边列表.下图是图的邻接表表示. 从图中可以看出,图的实现需要能够表示顶点表,能够表示边表.邻接表指是的哪部分呢?每个顶点都有一个邻接表,一个指定顶点的邻接表中,起始顶点表示边的起点,其他顶点表示边的终点.这样,就可以用邻接表来实现边的表示了.如顶点V0的邻接表如下: 与
-
Java数据结构之队列(动力节点Java学院整理)
队列的定义: 队列(Queue)是只允许在一端进行插入,而在另一端进行删除的运算受限的线性表. (1)允许删除的一端称为队头(Front). (2)允许插入的一端称为队尾(Rear). (3)当队列中没有元素时称为空队列. (4)队列亦称作先进先出(First In First Out)的线性表,简称为FIFO表. 队列的修改是依先进先出的原则进行的.新来的成员总是加入队尾,每次离开的成员总是队列头上的(不允许中途离队). 队列的存储结构及实现 队列的顺序存储结构 (1) 顺序队列的定义: 队列
-
Java数据结构之链表(动力节点之Java学院整理)
单链表: insertFirst:在表头插入一个新的链接点,时间复杂度为O(1) deleteFirst:删除表头的链接点,时间复杂度为O(1) find:查找包含指定关键字的链接点,由于需要遍历查找,平均需要查找N/2次,即O(N) remove:删除包含指定关键字的链接点,由于需要遍历查找,平均需要查找N/2次,即O(N) public class LinkedList { private class Data{ private Object obj; private Data next =
-
Java数据结构之数组(动力节点之Java学院整理)
数组的用处是什么呢?--当你需要将30个数进行大小排列的时候,用数组这样的数据结构存储是个很好的选择,当你是一个班的班主任的时候,每次要记录那些学生的缺勤次数的时候,数组也是很有用.数组可以进行插入,删除,查找等. 1)创建和内存分配 Java中有两种数据类型,基本类型和对象类型,也有人称为引用类型,Java中把数组当成对象,创建数组时使用new操作符. int array[] = new int[10]; 既然是对象,那么array便是数组的一个引用,根据Java编程思想(一) -- 一切都是
-
Java初学者问题图解(动力节点Java学院整理)
1. String对象不可改变的特性 下图显示了如下代码运行的过程: String s = "abcd"; s = s.concat("ef"); 图1 2. equals()与hashCode()方法协作约定 HashCode(哈希编码,散列码)是设计了用来提高性能的. equals()与hashCode()方法之间的关系可以概括为: 1.如果两个对象相等(equal),那么必须拥有相同的哈希码(hash code) 2.即使两个对象有相同的哈希值(hash co
-
Java Iterator迭代器_动力节点Java学院整理
迭代器是一种模式,它可以使得对于序列类型的数据结构的遍历行为与被遍历的对象分离,即我们无需关心该序列的底层结构是什么样子的.只要拿到这个对象,使用迭代器就可以遍历这个对象的内部. 1.Iterator Java提供一个专门的迭代器<<interface>>Iterator,我们可以对某个序列实现该interface,来提供标准的Java迭代器.Iterator接口实现后的功能是"使用"一个迭代器. 文档定义: Package java.util; publici
-
Java线程之join_动力节点Java学院整理
join()介绍 join() 定义在Thread.java中. join() 的作用:让"主线程"等待"子线程"结束之后才能继续运行.这句话可能有点晦涩,我们还是通过例子去理解: // 主线程 public class Father extends Thread { public void run() { Son s = new Son(); s.start(); s.join(); ... } } // 子线程 public class Son extends
-
Java List简介_动力节点Java学院整理
Java中可变数组的原理就是不断的创建新的数组,将原数组加到新的数组中,下文对Java List用法做了详解. List:元素是有序的(怎么存的就怎么取出来,顺序不会乱),元素可以重复(角标1上有个3,角标2上也可以有个3)因为该集合体系有索引 ArrayList:底层的数据结构使用的是数组结构(数组长度是可变的百分之五十延长)(特点是查询很快,但增删较慢)线程不同步 LinkedList:底层的数据结构是链表结构(特点是查询较慢,增删较快) Vector:底层是数组数据结构 线
-
十大常见Java String问题_动力节点Java学院整理
本文介绍Java中关于String最常见的10个问题: 1. 字符串比较,使用 "==" 还是 equals() ? 简单来说, "==" 判断两个引用的是不是同一个内存地址(同一个物理对象). 而 equals 判断两个字符串的值是否相等. 除非你想判断两个string引用是否同一个对象,否则应该总是使用 equals()方法. 如果你了解 字符串的驻留 ( String Interning ) 则会更好地理解这个问题 2. 对于敏感信息,为何使用char[]要比
-
Java二进制操作(动力节点Java学院整理)
移位 位运算中大多数操作都是向左移位和向右移位.在Java中,这对应着<<和>>这两个操作符,示例如下: /* 00000001 << 1 = 00000010 */ 1 << 1 == 2 /* 00000001 << 3 = 00001000 */ 1 << 3 == 8 /* 11111111 11111111 11111111 11110000 >> 4 = 11111111 11111111 11111111 1