pytorch使用Variable实现线性回归
本文实例为大家分享了pytorch使用Variable实现线性回归的具体代码,供大家参考,具体内容如下
一、手动计算梯度实现线性回归
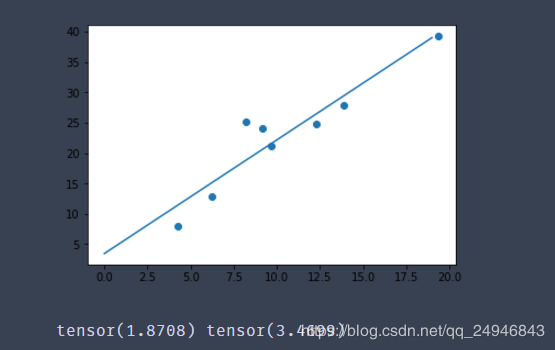
#导入相关包 import torch as t import matplotlib.pyplot as plt #构造数据 def get_fake_data(batch_size = 8): #设置随机种子数,这样每次生成的随机数都是一样的 t.manual_seed(10) #产生随机数据:y = 2*x+3,加上了一些噪声 x = t.rand(batch_size,1) * 20 #randn生成期望为0方差为1的正态分布随机数 y = x * 2 + (1 + t.randn(batch_size,1)) * 3 return x,y #查看生成数据的分布 x,y = get_fake_data() plt.scatter(x.squeeze().numpy(),y.squeeze().numpy()) #线性回归 #随机初始化参数 w = t.rand(1,1) b = t.zeros(1,1) #学习率 lr = 0.001 for i in range(10000): x,y = get_fake_data() #forward:计算loss y_pred = x.mm(w) + b.expand_as(y) #均方误差作为损失函数 loss = 0.5 * (y_pred - y)**2 loss = loss.sum() #backward:手动计算梯度 dloss = 1 dy_pred = dloss * (y_pred - y) dw = x.t().mm(dy_pred) db = dy_pred.sum() #更新参数 w.sub_(lr * dw) b.sub_(lr * db) if i%1000 == 0: #画图 plt.scatter(x.squeeze().numpy(),y.squeeze().numpy()) x1 = t.arange(0,20).float().view(-1,1) y1 = x1.mm(w) + b.expand_as(x1) plt.plot(x1.numpy(),y1.numpy()) #predicted plt.show() #plt.pause(0.5) print(w.squeeze(),b.squeeze())
显示的最后一张图如下所示:
二、自动梯度 计算梯度实现线性回归
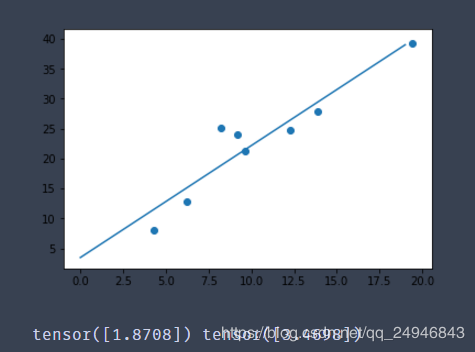
#导入相关包 import torch as t from torch.autograd import Variable as V import matplotlib.pyplot as plt #构造数据 def get_fake_data(batch_size=8): t.manual_seed(10) #设置随机数种子 x = t.rand(batch_size,1) * 20 y = 2 * x +(1 + t.randn(batch_size,1)) * 3 return x,y #查看产生的x,y的分布是什么样的 x,y = get_fake_data() plt.scatter(x.squeeze().numpy(),y.squeeze().numpy()) #线性回归 #初始化随机参数 w = V(t.rand(1,1),requires_grad=True) b = V(t.rand(1,1),requires_grad=True) lr = 0.001 for i in range(8000): x,y = get_fake_data() x,y = V(x),V(y) y_pred = x * w + b loss = 0.5 * (y_pred-y)**2 loss = loss.sum() #自动计算梯度 loss.backward() #更新参数 w.data.sub_(lr * w.grad.data) b.data.sub_(lr * b.grad.data) #梯度清零,不清零梯度会累加的 w.grad.data.zero_() b.grad.data.zero_() if i%1000==0: #predicted x = t.arange(0,20).float().view(-1,1) y = x.mm(w.data) + b.data.expand_as(x) plt.plot(x.numpy(),y.numpy()) #true data x2,y2 = get_fake_data() plt.scatter(x2.numpy(),y2.numpy()) plt.show() print(w.data[0],b.data[0])
显示的最后一张图如下所示:
用autograd实现的线性回归最大的不同点就在于利用autograd不需要手动计算梯度,可以自动微分。这一点不单是在深度在学习中,在许多机器学习的问题中都很有用。另外,需要注意的是每次反向传播之前要记得先把梯度清零,因为autograd求得的梯度是自动累加的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
PyTorch线性回归和逻辑回归实战示例
线性回归实战 使用PyTorch定义线性回归模型一般分以下几步: 1.设计网络架构 2.构建损失函数(loss)和优化器(optimizer) 3.训练(包括前馈(forward).反向传播(backward).更新模型参数(update)) #author:yuquanle #data:2018.2.5 #Study of LinearRegression use PyTorch import torch from torch.autograd import Variable # train
-
pytorch使用Variable实现线性回归
本文实例为大家分享了pytorch使用Variable实现线性回归的具体代码,供大家参考,具体内容如下 一.手动计算梯度实现线性回归 #导入相关包 import torch as t import matplotlib.pyplot as plt #构造数据 def get_fake_data(batch_size = 8): #设置随机种子数,这样每次生成的随机数都是一样的 t.manual_seed(10) #产生随机数据:y = 2*x+3,加上了一些噪声 x = t.rand(batch
-
利用Pytorch实现简单的线性回归算法
最近听了张江老师的深度学习课程,用Pytorch实现神经网络预测,之前做Titanic生存率预测的时候稍微了解过Tensorflow,听说Tensorflow能做的Pyorch都可以做,而且更方便快捷,自己尝试了一下代码的逻辑确实比较简单. Pytorch涉及的基本数据类型是tensor(张量)和Autograd(自动微分变量),对于这些概念我也是一知半解,tensor和向量,矩阵等概念都有交叉的部分,下次有时间好好补一下数学的基础知识,不过现阶段的任务主要是应用,学习掌握思维和方法即可,就不再
-
Pytorch之Variable的用法
1.简介 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Variable和tensor的区别和联系 Variable是篮子,而tensor是鸡蛋,鸡蛋应该放在篮子里才能方便拿走(定义variable时一个参数就是tensor) Variable这个篮子里除了装了tensor外还有requires_grad参数,表示是否需要对其求导,默认为False Variable这个篮子呢,自身有一些属性 比如grad,梯度vari
-
pytorch numpy list类型之间的相互转换实例
如下所示: import torch from torch.autograd import Variable import numpy as np ''' pytorch中Variable与torch.Tensor类型的相互转换 ''' # 1.torch.Tensor转换成Variablea=torch.randn((5,3)) b=Variable(a) print('a',a.type(),a.shape) print('b',type(b),b.shape) # 2.Variable转换
-
pytorch固定BN层参数的操作
背景: 基于PyTorch的模型,想固定主分支参数,只训练子分支,结果发现在不同epoch相同的测试数据经过主分支输出的结果不同. 原因: 未固定主分支BN层中的running_mean和running_var. 解决方法: 将需要固定的BN层状态设置为eval. 问题示例: 环境:torch:1.7.0 # -*- coding:utf-8 -*- import torch import torch.nn as nn import torch.nn.functional as F class
-

浅谈pytorch中为什么要用 zero_grad() 将梯度清零
pytorch中为什么要用 zero_grad() 将梯度清零 调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加. 这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度. optimizer.zero_grad() output = net(input) loss = loss_f(output, target) los
-
Pytorch反向传播中的细节-计算梯度时的默认累加操作
Pytorch反向传播计算梯度默认累加 今天学习pytorch实现简单的线性回归,发现了pytorch的反向传播时计算梯度采用的累加机制, 于是百度来一下,好多博客都说了累加机制,但是好多都没有说明这个累加机制到底会有啥影响, 所以我趁着自己练习的一个例子正好直观的看一下以及如何解决: pytorch实现线性回归 先附上试验代码来感受一下: torch.manual_seed(6) lr = 0.01 # 学习率 result = [] # 创建训练数据 x = torch.rand(20, 1
-
PyTorch搭建一维线性回归模型(二)
PyTorch基础入门二:PyTorch搭建一维线性回归模型 1)一维线性回归模型的理论基础 给定数据集,线性回归希望能够优化出一个好的函数,使得能够和尽可能接近. 如何才能学习到参数和呢?很简单,只需要确定如何衡量与之间的差别,我们一般通过损失函数(Loss Funciton)来衡量:.取平方是因为距离有正有负,我们于是将它们变为全是正的.这就是著名的均方误差.我们要做的事情就是希望能够找到和,使得: 均方差误差非常直观,也有着很好的几何意义,对应了常用的欧式距离.现在要求解这个连续函数的最小
-
pytorch实现线性回归以及多元回归
本文实例为大家分享了pytorch实现线性回归以及多元回归的具体代码,供大家参考,具体内容如下 最近在学习pytorch,现在把学习的代码放在这里,下面是github链接 直接附上github代码 # 实现一个线性回归 # 所有的层结构和损失函数都来自于 torch.nn # torch.optim 是一个实现各种优化算法的包,调用的时候必须是需要优化的参数传入,这些参数都必须是Variable x_train = np.array([[3.3],[4.4],[5.5],[6.71],[6.93