详解pandas如何去掉、过滤数据集中的某些值或者某些行?
摘要在进行数据分析与清理中,我们可能常常需要在数据集中去掉某些异常值。具体来说,看看下面的例子。
0.导入我们需要使用的包
import pandas as pd
pandas是很常用的数据分析,数据处理的包。anaconda已经有这个包了,纯净版python的可以自行pip安装。
1.去掉某些具体值
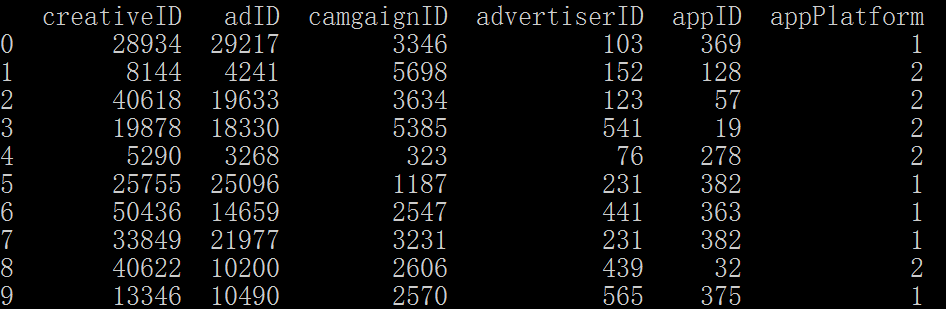
数据集df中,对于属性appPlatform(最后一列),我们想删除掉取值为2的那些样本。如何做?非常简单。
import pandas as pd
df[(True-df['appPlatform'].isin([2]))]

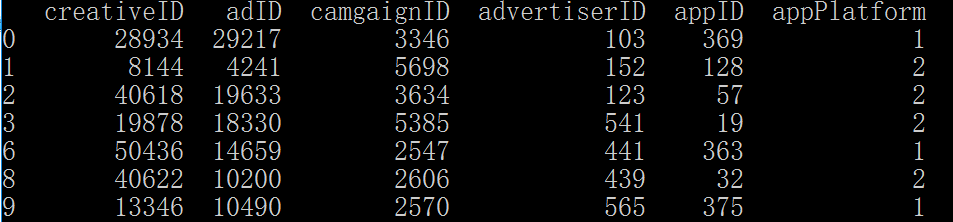
当然,有时候我们需要去掉不止一个值,这个时候只需要在isin([])的列表中添加。更具体来说,例如,对于appID这个属性,我们想去掉appID=278和appID=382的样本。
df[(True-df['appID'].isin([278,382]))]
另外,我们有时候并不只是考虑某一列,还需要考虑另外若干列的情况。例如,我们需要过滤掉appPlatform=2而且appID=278和appID=382的样本呢?非常简单。
df[(True-df['appID'].isin([278,382]))&(True-df['appPlatform'].isin([2]))]
其实,在这里我们看到,就是由两部分组成的,第一部分就是appID中等于278和382的,另外一部分就是appPlatform中等于2的。两者取逻辑关系 与(&)

2.过滤掉某个范围的值
上面我们是了解了如何取掉某个具体值,下面,我们要看看如何过滤掉某个范围的值。对于数据集df,我们想过滤掉creativeID(第一列)中ID值大于10000的样本。
df[df['creativeID']<=10000]

另外,如果要考虑多列的话,其实和上面一样,将两种情况做逻辑与(&)就可以,不过值得注意的是,每个条件要用括号()括起来。
以上所述是小编给大家介绍的pandas如何去掉、过滤数据集中的某些值或者某些行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
pandas DataFrame 删除重复的行的实现方法
1. 建立一个DataFrame C=pd.DataFrame({'a':['dog']*3+['fish']*3+['dog'],'b':[10,10,12,12,14,14,10]}) 2. 判断是否有重复项 用duplicated( )函数判断 C.duplicated() 3. 有重复项,则可以用drop_duplicates()移除重复项 C.drop_duplicates() 4. Duplicated( )和drop_duplicates( )方法是以默认的方式判断全部的列(上面
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-

pandas删除指定行详解
在处理pandas的DataFrame中,如果想像excel那样筛选,只要其中的某一行或者几行,可以使用isin()方法来实现,只需要将需要的行值以列表方式传入即可,还可传入字典,进行指定筛选. pandas.DataFrame中删除包涵特定字符串所在的行:https://www.jb51.net/article/159052.htm 以上所述是小编给大家介绍的pandas删除指定行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支
-
pandas 数据归一化以及行删除例程的方法
如下所示: #coding:utf8 import pandas as pd import numpy as np from pandas import Series,DataFrame # 如果有id列,则需先删除id列再进行对应操作,最后再补上 # 统计的时候不需要用到id列,删除的时候需要考虑 # delete row def row_del(df, num_percent, label_len = 0): #print list(df.count(axis=1)) col_num = l
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
-
详解pandas.DataFrame中删除包涵特定字符串所在的行
你在使用pandas处理DataFrame中是否遇到过如下这类问题?我们需要删除某一列所有元素中含有固定字符元素所在的行,比如下面的例子: 以上所述是小编给大家介绍的pandas.DataFrame中删除包涵特定字符串所在的行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
pandas.DataFrame删除/选取含有特定数值的行或列实例
1.删除/选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]]) df1=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC')) print(df1) df2=df1.copy() #删除/选取某列含有特定数值的行 #df1=df1[df1['A'].isin([1])] #df1[df1['A'].
-
详解pandas如何去掉、过滤数据集中的某些值或者某些行?
摘要在进行数据分析与清理中,我们可能常常需要在数据集中去掉某些异常值.具体来说,看看下面的例子. 0.导入我们需要使用的包 import pandas as pd pandas是很常用的数据分析,数据处理的包.anaconda已经有这个包了,纯净版python的可以自行pip安装. 1.去掉某些具体值 数据集df中,对于属性appPlatform(最后一列),我们想删除掉取值为2的那些样本.如何做?非常简单. import pandas as pd df[(True-df['appPlatfor
-
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
详解Pandas如何高效对比处理DataFrame的两列数据
目录 楔子 combine_first combine update 楔子 我们在用 pandas 处理数据的时候,经常会遇到用其中一列数据替换另一列数据的场景.比如 A 列和 B 列,对 A 列中不为空的数据不作处理,对 A 列中为空的数据使用 B 列对应索引的数据进行替换.这一类的需求估计很多人都遇到,当然还有其它更复杂的. 解决这类需求的办法有很多,这里我们来推荐几个. combine_first 这个方法是专门用来针对空值处理的,我们来看一下用法. import pandas as pd
-
详解Pandas 处理缺失值指令大全
前言 运用pandas 库对所得到的数据进行数据清洗,复习一下相关的知识. 1 数据清洗 1.1 处理缺失数据 对于数值型数据,分为缺失值(NAN)和非缺失值,对于缺失值的检测,可以通过Python中pandas库的Series类对象的isnull方法进行检测. import pandas as pd import numpy as np string_data = pd.Series(['Benzema', 'Messi', np.nan, 'Ronaldo']) string_data.is
-
详解Pandas中GroupBy对象的使用
目录 使用 Groupby 三个步骤 将原始对象拆分为组 按组应用函数 Aggregation Transformation Filtration 整合结果 总结 今天,我们将探讨如何在 Python 的 Pandas 库中创建 GroupBy 对象以及该对象的工作原理.我们将详细了解分组过程的每个步骤,可以将哪些方法应用于 GroupBy 对象上,以及我们可以从中提取哪些有用信息 不要再观望了,一起学起来吧 使用 Groupby 三个步骤 首先我们要知道,任何 groupby 过程都涉及以下
-
详解pandas中iloc, loc和ix的区别和联系
Pandas库十分强大,但是对于切片操作iloc, loc和ix,很多人对此十分迷惑,因此本篇博客利用例子来说明这3者之一的区别和联系,尤其是iloc和loc. 对于ix,由于其操作有些复杂,我在另外一篇博客专门详细介绍ix. 首先,介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列).这里的关键是:标签.标签的理解就是name名字. iloc get
-
详解pandas.DataFrame.plot() 画图函数
首先看官网的DataFrame.plot( )函数 DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None,figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False,
-
详解pandas赋值失败问题解决
一.pandas对整列赋值 这个比较正常,一般直接赋值就可以: x = pd.DataFrame({'A': ['1', '2', '3', None, None], 'B': ['4', '5', '6', '7', None]}) x['A'] = ['10', '11', '12', '13', '14'] 二.pandas对非整列赋值 1.用单个值赋值 x = pd.DataFrame({'A': ['1', '2', '3', None, None], 'B': ['4', '5',
-
详解pandas映射与数据转换
在 pandas 中提供了利用映射关系来实现某些操作的函数,具体如下: replace() 函数:替换元素: map() 函数:新建一列: rename() 函数:替换索引. 一.replace() 用映射替换元素 在数据处理时,经常会遇到需要将数据结构中原来的元素根据实际需求替换成新元素的情况.要想用新元素替换原来元素,就需要定义一组映射关系.在映射关系中,将旧元素作为键,新元素作为值. 例如,创建字典 fruits 用于指明水果标识和水果名称的映射关系. fruits={101:'orang
-
详解pandas apply 并行处理的几种方法
1. pandarallel (pip install ) 对于一个带有Pandas DataFrame df的简单用例和一个应用func的函数,只需用parallel_apply替换经典的apply. from pandarallel import pandarallel # Initialization pandarallel.initialize() # Standard pandas apply df.apply(func) # Parallel apply df.parallel_ap