利用Pyhton中的requests包进行网页访问测试的方法
为了测试一组网页是否能够访问,采取python中的requests包进行批量的访问测试,并输出访问结果。
一、requests包的安装
打开命令行(win+r输入cmd启动);
打开pythion安装目录下的Python\Python36-32\Scripts,将其中的pip文件拖动到命令行中;
在之后输入install requests命令;
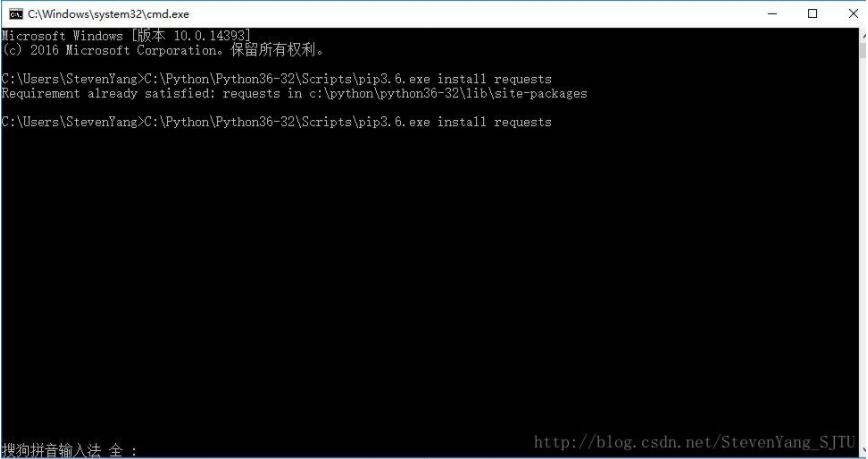
二、访问方法
import requests
fin = open('urls.txt', 'r')
fout = open('result.txt', 'w')
urllist = fin.readlines()
for url in urllist:
try:
url='http://'+url.strip()
r=requests.post(url)
fout.write(url+' : OK with status_code: '+str(r.status_code))
print(url+' : OK with status_code: '+str(r.status_code))
except:
fout.write(url+' : error\n')
print(url+' : error\n')
fin.close()
fout.close()
通过读取文件中的url进行访问;
由于文件中url缺少一些信息,因此统一加上http://;
.strip()方法是为了去掉末尾的\n,否则会访问错误;
之所以采用try/except是因为经过测试发现,有些网站打不开会直接导致程序中断,而有些网站则是能够进去,但是网站本身没有内容或再报一些其他错,所以对于能访问的网站还会进一步检查状态码进行鉴别。
以上这篇利用Pyhton中的requests包进行网页访问测试的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python3使用requests包抓取并保存网页源码的方法
本文实例讲述了Python3使用requests包抓取并保存网页源码的方法.分享给大家供大家参考,具体如下: 使用Python 3的requests模块抓取网页源码并保存到文件示例: import requests html = requests.get("http://www.baidu.com") with open('test.txt','w',encoding='utf-8') as f: f.write(html.text) 这是一个基本的文件保存操作,但这里有几个值得注意的
-

Python的requests网络编程包使用教程
早就听说requests的库的强大,只是还没有接触,今天接触了一下,发现以前使用urllib,urllib2等方法真是太搓了-- 这里写些简单的使用初步作为一个记录 一.下载 官方项目页: https://pypi.python.org/pypi/requests/#downloads 可以从上面直接下载. 二.发送无参数的get请求 >>> r = requests.get('http://httpbin.org/get') >>> print r.text { &q
-
python 使用 requests 模块发送http请求 的方法
Requests具有完备的中英文文档, 能完全满足当前网络的需求, 它使用了urllib3, 拥有其所有的特性! 最近在学python自动化,怎样用python发起一个http请求呢? 通过了解 request 模块可以帮助我们发起http请求 步骤: 1.首先import 下 request 模块 2.然后看请求的方式,选择对应的请求方法 3.接受返回的报文信息 例子:get 方法 import requests url ="https://www.baidu.com" res =
-
python中requests模块的使用方法
本文实例讲述了python中requests模块的使用方法.分享给大家供大家参考.具体分析如下: 在HTTP相关处理中使用python是不必要的麻烦,这包括urllib2模块以巨大的复杂性代价获取综合性的功能.相比于urllib2,Kenneth Reitz的Requests模块更能简约的支持完整的简单用例. 简单的例子: 想象下我们试图使用get方法从http://example.test/获取资源并且查看返回代码,content-type头信息,还有response的主体内容.这件事无论使用
-
python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基
-
python3使用requests模块爬取页面内容的实战演练
1.安装pip 我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip. $ sudo apt install python-pip 安装成功,查看PIP版本: $ pip -V 2.安装requests模块 这里我是通过pip方式进行安装: $ pip install requests 运行import requests,如果没提示错误,那说明已经安装成功了! 检验是否安装成功 3.安装beautifulsou
-
如何使用Python的Requests包实现模拟登陆
前段时间喜欢用python去抓一些页面玩,但都基本上都是用get请求一些页面,再通过正则去过滤. 今天试了一下,模拟登陆个人网站.发现也比较简单.读懂本文需要对http协议和http会话有一定的理解. 注明:因为模拟登陆的是我的个人网站,所以以下代码对个人网站和账号密码做了处理. 网站分析 爬虫的必备第一步,分析目标网站.这里使用谷歌浏览器的开发者者工具分析. 通过登陆抓取,看到这样一个请求. 上方部分为请求头,下面部分为请求是传的参数.由图片可以看出,页面通过表单提交了三个参数.分别为_csr
-
python利用requests库进行接口测试的方法详解
前言 之前介绍了接口测试中需要关注得测试点,现在我们来看看如何进行接口测试,现在接口测试工具有很多种,例如:postman,soapui,jemter等等,对于简单接口而言,或者我们只想调试一下,使用工具是非常便捷而且快速得,但是对于更复杂得场景,这些工具虽然也能实现,但是难度要比写代码更大,而且定制化受到工具得功能影响,会 遇到一些障碍,当然我们还要实现自动化等等,鉴于以上因素,我们还是要学会使用代码进行接口测试,便于维护与扩展,或者算是我们知识得补充把~ requests库是python用来
-
利用Pyhton中的requests包进行网页访问测试的方法
为了测试一组网页是否能够访问,采取python中的requests包进行批量的访问测试,并输出访问结果. 一.requests包的安装 打开命令行(win+r输入cmd启动); 打开pythion安装目录下的Python\Python36-32\Scripts,将其中的pip文件拖动到命令行中; 在之后输入install requests命令; 二.访问方法 import requests fin = open('urls.txt', 'r') fout = open('result.txt',
-
PHP中使用file_get_contents抓取网页中文乱码问题解决方法
本文实例讲述了PHP中使用file_get_contents抓取网页中文乱码问题解决方法.分享给大家供大家参考.具体方法如下: file_get_contents函数本来就是一个非常优秀的php自带本地与远程文件操作函数,它可以让我们不花吹挥之力把远程数据直接下载,但我在使用它读取网页时会碰到有些页面是乱码了,这里就来给各位总结具体的解决办法. 根据网上有朋友介绍说原因可能是服务器开了GZIP压缩,下面是用firebug查看我的网站的头信息,Gzip是开了的,请求头信息原始头信息,代码如下: 复
-
在python中使用requests 模拟浏览器发送请求数据的方法
如下所示: import requests url='http://####' proxy={'http':'http://####:80'} headers={ "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding": "gzip, deflate, br", "Accept-Lang
-
对python中使用requests模块参数编码的不同处理方法
python中使用requests模块http请求时,发现中文参数不会自动的URL编码,并且没有找到类似urllib (python3)模块中urllib.parse.quote("中文")手动URL编码的方法.研究了半天发现requests模块对中文参数有3种不同的处理方式. 一.requests模块自动URL编码参数 要使参数自动URL编码,需要将请求参数以字典的形式定义,如下demo: import requests proxy = {"http":"
-
php中cookie实现二级域名可访问操作的方法
本文实例讲述了php中cookie实现二级域名可访问操作的方法.分享给大家供大家参考.具体方法如下: cookie在一些应用中很常用,假设我有一个多级域名要求可以同时访问主域名绑定的cookie,下面就来给大家具体介绍在php中利用setcookie实现二级域名可以成功访问主域名cookie值的方法. 有时候两个域名可能在不同的服务器上,但是我们依然希望二级域名能够顺利访问主域名的cookie,主域名可以顺利访问二级域名的cookie,比如sc.jb51.net 希望能访问 www.jb51.n
-
vue在手机中通过本机IP地址访问webApp的方法
vue中通过localhost:8080,就可以访问浏览项目,但是如果改成本机IP则会报错 通过localhost:8080访问效果 通过本机IP显示效果 如果想通过手机输入本机IP访问需要在package.json中配置 package.json配置 最后在手机通过IP就可以访问到webApp,或借助草料二维码生成修改后项目地址的二维码,掏出手机扫一扫即可~ 通过机IP访问效果 Tips:需要手机和电脑在一个局域网(wifi)下 总结 以上所述是小编给大家介绍的vue在手机中通过本机IP地址访
-
Python中模块与包有相同名字的处理方法
前言 在编程开发中,个人觉得,只要按照规范去做,很少会出问题.刚开始学习一门技术时,的确会遇到很多的坑.踩的坑多了,这是好事,会学到更多东西,也会越来越觉得按照规范做的重要性,规范的制定就是用来规避问题的.有时候确实应该听听有经验人的建议,不要一意孤行.这好像不是本文的重点,其实我重点是想表达,尽量按规范做事,这样会少走很多弯路. 我现在使用的主力编程语言是 Python,在接触 Python 至今,我感觉我踩的坑还是极少的,基本上没有遇到什么奇怪的问题.实际上,这并不是一件好事,不踩坑,很多躺
-
centos中nginx按日期自动分割访问日志的方法
Web 访问日志 (access_log) 记录了所有外部客户端对Web服务器的访问行为,包含了客户端IP,访问日期,访问的URL资源,服务器返回的HTTP状态码等重要信息. 一条典型的Web访问日志如下: 复制代码 代码如下: 192.168.50.195 - - [17/Jun/2016:23:59:12 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) Ap
-
Win2008中安装的MSSQL2005后无法访问的解决方法
很久笔者没有来这里写东西了,因为真的很忙. 最近笔者一直在使用Win2008系统,不过发现一个很奇怪的问题,那就是在该系统上安装了SQL2005后,再在其他计算机访问该主机显示不能访问. 其他主机上也安装了SQL2005,可是连接Win2008系统上的SQL时就出现了这样的报错信息. 当时笔者很困惑,是为什么? 因为Win2003系统中,从来不会有这样的问题发生. 笔者错误的任务,是Win2008系统和SQL2005系统的不兼容,或者有不匹配的问题导致了这样的问题发生. 经过很长时间的想法,笔者
-
linux中启动tomcat后浏览器无法访问的解决方法
前言 不论是要启动,还是要关闭tomcat服务,都是要去到tomcat安装目录下的bin路径,当然你要是电脑关机自然是不需要的. 但最近在启动后发现了一个问题:Centos服务器,本地和服务器ip互ping正常(本机ping服务器,服务器ping本地),但是服务器上部署好tomcat后,本机却无法通过浏览器访问服务器tomcat的8080端口. 比如服务器公网ip为:123.123.123.123,启动tomcat后默认端口为8080,通过123.123.123.123:8080访问时,无法访问