哈夫曼算法构造代码
1.定义
哈夫曼编码主要用于数据压缩。
哈夫曼编码是一种可变长编码。该编码将出现频率高的字符,使用短编码;将出现频率低的字符,使用长编码。
变长编码的主要问题是,必须实现非前缀编码,即在一个字符集中,任何一个字符的编码都不是另一个字符编码的前缀。如:0、10就是非前缀编码,而0、01不是非前缀编码。
2.哈夫曼树的构造
按照字符出现的频率,总是选择当前具有较小频率的两个节点,组合为一个新的节点,循环此过程知道只剩下一个节点为止。
对于5个字符A、B、C、D、E,频率分别用1、5、7、9、6表示,则构造树的过程如下:
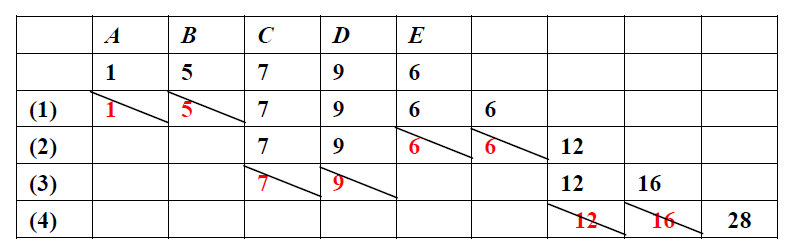
上面过程对应的哈夫曼树为:

假设规定左边为0,右边为1,则变长编码为:
A 1:010
B 5:011
C 7:10
D 9:11
E 6: 00
3.哈夫曼构造代码
#include <iostream>
#include <string.h>
using namespace std;
struct Node{
char c;
int value;
int par;
char tag; //tag='0',表示左边;tag='1',表示右边
bool isUsed; //判断这个点是否已经用过
Node(){
par=-1;
isUsed=false;
}
};
int input(Node*,int); //输入节点信息
int buildedTree(Node*,int); //建哈夫曼树
int getMin(Node*,int); //寻找未使用的,具有最小频率值的节点
int outCoding(Node*,int); //输出哈夫曼编码
int main ()
{
int n;
cin>>n;
Node *nodes=new Node[2*n-1];
input(nodes,n);
buildedTree(nodes,n);
outCoding(nodes,n);
delete(nodes);
return 0;
}
int input(Node* nodes,int n){
for(int i=0;i<n;i++){
cin>>(nodes+i)->c;
cin>>(nodes+i)->value;
}
return 0;
}
int buildedTree(Node* nodes,int n){
int last=2*n-1;
int t1,t2;
for(int i=n;i<last;i++){
t1=getMin(nodes,i);
t2=getMin(nodes,i);
(nodes+t1)->par=i; (nodes+t1)->tag='0';
(nodes+t2)->par=i; (nodes+t2)->tag='1';
(nodes+i)->value=(nodes+t1)->value+(nodes+t2)->value;
}
return 0;
}
int getMin(Node* nodes,int n){
int minValue=10000000;
int pos=0;
for(int i=0;i<n;i++)
{
if((nodes+i)->isUsed == false && (nodes+i)->value<minValue){
minValue=(nodes+i)->value;
pos=i;
}
}
(nodes+pos)->isUsed=true;
return pos;
}
int outCoding(Node* nodes,int n){
char a[100];
int pos,k,j;
char tmp;
for(int i=0;i<n;i++){
k=0;
pos=i;
memset(a,'\0',sizeof(a));
while((nodes+pos)->par!=-1){
a[k++]=(nodes+pos)->tag;
pos=(nodes+pos)->par;
}
strrev(a); //翻转字符串
cout<<(nodes+i)->c<<" "<<(nodes+i)->value<<":"<<a<<endl;
}
return 0;
}
执行示例:

相关推荐
-
哈夫曼的c语言实现代码
我们设置一个结构数组 HuffNode 保存哈夫曼树中各结点的信息.根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有 2n-1 个结点,所以数组 HuffNode 的大小设置为 2n-1 .HuffNode 结构中有 weight, lchild, rchild 和 parent 域.其中,weight 域保存结点的权值, lchild 和 rchild 分别保存该结点的左.右孩子的结点在数组 HuffNode 中的序号,从而建立起结点之间的关系.为了判定一个结点是否已加入到要建立的哈夫曼树
-
C#求解哈夫曼树,实例代码
复制代码 代码如下: class HuffmanTree { private Node[] data; public int LeafNum { get; set; } public Node this[int index] { get { return data[index]; } set { data[index] = value; } } public Hu
-

哈夫曼算法构造代码
1.定义 哈夫曼编码主要用于数据压缩. 哈夫曼编码是一种可变长编码.该编码将出现频率高的字符,使用短编码:将出现频率低的字符,使用长编码. 变长编码的主要问题是,必须实现非前缀编码,即在一个字符集中,任何一个字符的编码都不是另一个字符编码的前缀.如:0.10就是非前缀编码,而0.01不是非前缀编码. 2.哈夫曼树的构造 按照字符出现的频率,总是选择当前具有较小频率的两个节点,组合为一个新的节点,循环此过程知道只剩下一个节点为止. 对于5个字符A.B.C.D.E,频率分别用1.5.7.9.6表示,
-
Java 最优二叉树的哈夫曼算法的简单实现
最优二叉树也称哈夫曼树,讲的直白点就是每个结点都带权值,我们让大的值离根近.小的值离根远,实现整体权值(带权路径长度)最小化. 哈夫曼算法的思想我认为就是上面讲的,而它的算法实现思路是这样的: 从根结点中抽出权值最小的两个(涉及排序,但是我这个实现代码没做严格的排序,只有比较)合并出新的根结点重新加入排序(被抽出来的两个自然是变成非根结点了啊),就这样循环下去,直到合并完成,我们得到一颗最优二叉树--哈夫曼树. 说明: (1)哈夫曼树有n个叶子结点,则我们可以推出其有n-1个分支结点.因此我在定
-
java哈夫曼树实例代码
本文实例为大家分享了哈夫曼树java代码,供大家参考,具体内容如下 package boom; import java.util.ArrayDeque; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.Queue; class Node<T> implements Comparable<Node<T>>{ private T
-
Java实现赫夫曼树(哈夫曼树)的创建
目录 一.赫夫曼树是什么? 1.路径和路径长度 2.节点的权和带权路径长度 3.树的带权路径长度 二.创建赫夫曼树 1.图文创建过程 2.代码实现 一.赫夫曼树是什么? 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度(WPL)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree).哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近. 图1 一棵赫夫曼树 1.路径和路径长度 在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径.
-
C++深入讲解哈夫曼树
目录 哈夫曼树的基本概念 1)路径 2)路径长度 3)权 4)结点的带权路径长度 5)树的带权路径长度 6)哈夫曼树 哈夫曼树的构造算法 哈夫曼树的构造过程 哈夫曼树算法的实现 1)结点的存储结构 2)构建哈夫曼树 哈夫曼树的基本概念 Q:什么是哈夫曼树 A:哈夫曼树又称最优树,是一类带权路径长度最短的树.在正式了解哈夫曼树之前,我们需要了解一些概念. 1)路径 Q:什么是路径 A:从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径. 2)路径长度 Q:什么是路径长度 A:路径上的分支
-
C++使用数组来实现哈夫曼树
目录 写在前面 构造思想 算法设计 构造实例 理解代码 确定结构体 循环找出最小值 调用细节 调试试图 总结 写在前面 哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树.所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数).树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶
-
C++实现哈夫曼树简单创建与遍历的方法
本文以实例形式讲述了C++实现哈夫曼树简单创建与遍历的方法,比较经典的C++算法. 本例实现的功能为:给定n个带权的节点,如何构造一棵n个带有给定权值的叶节点的二叉树,使其带全路径长度WPL最小. 据此构造出最优树算法如下: 哈夫曼算法: 1. 将n个权值分别为w1,w2,w3,....wn-1,wn的节点按权值递增排序,将每个权值作为一棵二叉树.构成n棵二叉树森林F={T1,T2,T3,T4,...Tn},其中每个二叉树都只有一个权值,其左右字数为空 2. 在森林F中选取根节点权值最小二叉树,
-
解读赫夫曼树编码的问题
定义: 结点的带权路径长度为从该结点到树根之间的路径长度与结点上权的乘积.树的带权路径长度为树中所有叶子结点的带权路径长度之和.假设有n个权值,试构造一棵有n个叶子结点的二叉树,每个叶子结点带权为wi,则其中带权路径长度最小的二叉树称做最优二叉树或赫夫曼树. 构造赫夫曼树的方法: (1)根据给定的n个权值{w1,w2,w3......}构成n棵二叉树的集合F={T1,T2,T3,T4......},其中每棵二叉树Ti中只有一个带权为wi的根结点,其左右子树均空. (2)在F中选取两棵根结点的权值
-
Java数据结构之哈夫曼树概述及实现
一.与哈夫曼树相关的概念 概念 含义 1. 路径 从树中一个结点到另一个结点的分支所构成的路线 2. 路径长度 路径上的分支数目 3. 树的路径长度 长度从根到每个结点的路径长度之和 4. 带权路径长度 结点具有权值, 从该结点到根之间的路径长度乘以结点的权值, 就是该结点的带权路径长度 5. 树的带权路径长度 树中所有叶子结点的带权路径长度之和 二.什么是哈夫曼树 定义: 给定n个权值作为n个叶子结点, 构造出的一棵带权路径长度(WPL)最短的二叉树,叫哈夫曼树(), 也被称为最最优二叉树.