Python图像处理之图片文字识别功能(OCR)
OCR与Tesseract介绍
将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR)。可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制。
Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源OCR 系统。
除
了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体(只要这些字体的风格保持不变就可以),也可以识别出任何Unicode 字符。
Tesseract的安装与使用
Tesseract的Windows安装包下载地址为: http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe ,下载后双击直接安装即可。安装完后,需要将Tesseract添加到系统变量中。在CMD中输入tesseract -v, 如显示以下界面,则表示Tesseract安装完成且添加到系统变量中。
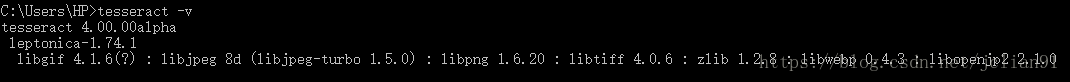
Linux 用户可以通过apt-get 安装:
$sudo apt-get tesseract-ocr
用Tesseract可以识别格式规范的文字,主要具有以下特点:
• 使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体)
• 虽然被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
• 排列整齐,没有歪歪斜斜的字
• 没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
下面将给出几个tesseract识别图片中文字的例子。
首先是E://figures/other/poems.jpg, 输入命令 tesseract E://figures/other/poems.jpg E://figures/other/poems.txt, 则会将poems.jpg中的识别文字写入到poems.txt中,如下图:



接着是稍微有点倾斜的文字图片th.jpg,识别情况如下:

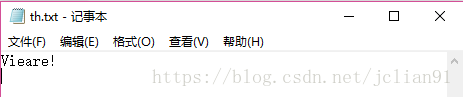
可以看到识别的情况不如刚才规范字体的好,但是也能识别图片中的大部分字母。
最后是识别简体中文,需要事先安装简体中文语言包,下载地址为: https://github.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata ,再讲chi_sim.traineddata放在C:\Program Files (x86)\Tesseract-OCR\tessdata目录下。我们以图片timg.jpg为例:

输入命令:
tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim
识别结果如下:

只识别错了一个字,识别率还是不错的。
最后加一句,Tesseract对于彩色图片的识别效果没有黑白图片的效果好。
pytesseract
pytesseract是Tesseract关于Python的接口,可以使用pip install pytesseract安装。安装完后,就可以使用Python调用Tesseract了,不过,你还需要一个Python的图片处理模块,可以安装pillow.
输入以下代码,可以实现同上述Tesseract命令一样的效果:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg'))
print(text)
运行结果如下:

总结
以上所述是小编给大家介绍的Python图像处理之图片文字识别功能(OCR),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python使用TensorFlow进行图像处理的方法
一.图片的放大缩小 在使用TensorFlow进行图片的放大缩小时,有三种方式: 1.tf.image.resize_nearest_neighbor():临界点插值 2.tf.image.resize_bilinear():双线性插值 3.tf.image.resize_bicubic():双立方插值算法 下面是示例代码: # encoding:utf-8 # 使用TensorFlow进行图片的放缩 import tensorflow as tf import cv2 import numpy
-
Python图像处理之识别图像中的文字(实例讲解)
①安装PIL:pip install Pillow(之前的博客中有写过) ②安装pytesser3:pip install pytesser3 ③安装pytesseract:pip install pytesseract ④安装autopy3: 先安装wheel:pip install wheel 下载autopy3-0.51.1-cp36-cp36m-win_amd64.whl[点击打开链接] 执行命令:pip install E:\360安全浏览器下载\autopy3-0.51.1-cp36
-

python图像处理之镜像实现方法
本文实例讲述了python图像处理之镜像实现方法.分享给大家供大家参考.具体分析如下: 图像的镜像变化不改变图像的形状.图像的镜像变换分为三种:水平镜像.垂直镜像.对角镜像 设图像的大小为M×N,则 水平镜像可按公式 I = i J = N - j + 1 垂直镜像可按公式 I = M - i + 1 J = j 对角镜像可按公式 I = M - i + 1 J = N - j + 1 值得注意的是在OpenCV中坐标是从[0,0]开始的 所以,式中的 +1 在编程时需要改为 -1 这里运行环境
-
python数字图像处理实现直方图与均衡化
在图像处理中,直方图是非常重要,也是非常有用的一个处理要素. 在skimage库中对直方图的处理,是放在exposure这个模块中. 1.计算直方图 函数:skimage.exposure.histogram(image,nbins=256) 在numpy包中,也提供了一个计算直方图的函数histogram(),两者大同小义. 返回一个tuple(hist, bins_center), 前一个数组是直方图的统计量,后一个数组是每个bin的中间值 import numpy as np from s
-
python使用pil进行图像处理(等比例压缩、裁剪)实例代码
PIL中设计的几个基本概念 1.通道(bands):即使图像的波段数,RGB图像,灰度图像 以RGB图像为例: >>>from PIL import Image >>>im = Image.open('*.jpg') # 打开一张RGB图像 >>>im_bands = im.g etbands() # 获取RGB三个波段 >>>len(im_bands) >>>print im_bands[0,1,2] # 输出RG
-
python数字图像处理之高级滤波代码详解
本文提供许多的滤波方法,这些方法放在filters.rank子模块内. 这些方法需要用户自己设定滤波器的形状和大小,因此需要导入morphology模块来设定. 1.autolevel 这个词在photoshop里面翻译成自动色阶,用局部直方图来对图片进行滤波分级. 该滤波器局部地拉伸灰度像素值的直方图,以覆盖整个像素值范围. 格式:skimage.filters.rank.autolevel(image, selem) selem表示结构化元素,用于设定滤波器. from skimage im
-
python图像处理之反色实现方法
本文实例讲述了python图像处理之反色实现方法.分享给大家供大家参考.具体如下: 我们先加载一个8位灰度图像 每一个像素对应的灰度值从0-255 则只需要读取每个像素的灰度值A,再将255-A写入 这样操作一遍后,图像就会反色了 这里运行环境为: Python为:Python2.7.6 OpenCV2.4.10版(可到http://sourceforge.net/projects/opencvlibrary/files/opencv-win/下载) numpy为:numpy-1.9.1-win
-
Python图像处理之图片文字识别功能(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制. Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司).Tesseract 是目前公认最优秀.最精确的开源OCR 系统. 除 了极高的精确度,Tesseract 也具有很高的灵活性.它可
-
图片文字识别(OCR)插件Ocrad.js教程
Ocrad.js 相当于是 Ocrad 项目的纯 JavaScript 版本,使用 Emscripten 自动转换.这是一个简单的 OCR (光学字符识别)程序,可以扫描图像中的文字回文本. 不像 GOCR.js,Ocrad.js 被设计成一个端口,而不是围绕可执行的包装.这意味着后续的图像处理,并不涉及重新初始化可执行代码,以便处理图像尽可能少的进行,因此它需要的时间仅为 GOCR.js 的八分之一. GOCR.js 已在 github 进行开源,下载地址 ocrad.js 的csdn资源下载
-
Python调用百度AI实现图片上文字识别功能实例
目录 简介 步骤 安装百度AI库 注册百度AI开放平台 调用glob库 调用AipOcr库识别文字 可能会遇到的问题 批量操作 总结 简介 Python免费调用百度AI实现图片上面的文字识别 步骤 安装百度AI库 !pip install baidu-aip 注册百度AI开放平台 先注册百度AI,获得ID和密钥.注册方法可参考:注册方法 只需走到 "1.6 获取密钥" 即可.然后记录下自己的APP_ID.API_KEY.SECRET_KEY,就可以开始了. 调用glob库 glob库用
-
Python调用百度OCR实现图片文字识别的示例代码
百度AI提供了一天50000次的免费文字识别额度,可以愉快的免费使用!下面直接上方法: 首先在百度AI创建一个应用,按照下图创建即可,创建后会获得如下: 创建后会获得如下信息: APP_ID = '******' API_KEY = '************' SECRET_KEY = '**************' 下面就是百度API包的安装,在终端cmd输入如下语句直接pip方式安装,注意是 baidu-api 哦! pip install --user baidu-aip 接下来上py
-
Python基于内置库pytesseract实现图片验证码识别功能
这篇文章主要介绍了Python基于内置库pytesseract实现图片验证码识别功能,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 环境准备: 1.安装Tesseract模块 git文档地址:https://digi.bib.uni-mannheim.de/tesseract/ 下载后就是一个exe安装包,直接右击安装即可,安装完成之后,配置一下环境变量,编辑 系统变量里面 path,添加下面的安装路径: 2.如果您想使用其他语言,请下载相应的
-
C# SDK实现百度云OCR的文字识别功能
最近项目要用到文字识别功能,所以花了几天时间整理了一下.今天就记录一下用C#实现文字识别的过程. 一.登录百度云进入控制台界面,创建应用获取秘钥 1.在百度云的产品里找到文字识别 2.找到通用文字识别点击立即使用.然后进入控制台.(这里可能会进入购买页面,可以直接购买免费版) 3.在控制台点击创建应用.然后填写相关内容就可以获得应用秘钥. 二.获得C#SDK 1.百度云C#SDK下载:下载地址 2.可以到官网直接下载:下载链接 三.将C#SDK导入VS 找到解决方案里的引用目录,右键,选择第一个
-
Node+OCR实现图像文字识别功能
开发目的 这算是node应用的第二个小应用吧,主要目的是熟悉node和express框架.原理很简单:在node搭建的环境下引用第三方包处理图片数据并返回给前台信息. 实现效果,百度提供的图片识别,经过测试识别车牌号等规范文字数字还是比较准确的 环境需求 1.Express 是一个非常流行的node.js的web框架.基于connect(node中间件框架).提供了很多便于处理http请求等web开发相关的扩展. 2.OCR: 通用文字识别 Node SDK目录结构: ├── src │
-
python利用百度AI实现文字识别功能
本文为大家分享了python实现文字识别功能大全,供大家参考,具体内容如下 1.通用文字识别 # -*- coding: UTF-8 -*- from aip import AipOcr # 定义常量 APP_ID = '11352343' API_KEY = 'Nd5Z1NkGoLDvHwBnD2bFLpCE' SECRET_KEY = 'A9FsnnPj1Ys2Gof70SNgYo23hKOIK8Os' # 初始化AipFace对象 aipOcr = AipOcr(APP_ID, API_K
-
Java使用Tessdata做OCR图片文字识别的详细思路
说到文字识别,目前除了用一些现成的api,大概就是 tessdata.canvas或者 ocrad等. 1.百度接口用过(可以自己去百度开发者申请,免费的),识别率吧,还可以,但也不是百分百的,但是次数使用有限制,虽然也是够用,但是被限制总是害怕超过不让用. 2.canvas的话是需要对图片做具体的处理,涉及到图片的翻转.置灰.文字间隔的设定等等,成功率很高,但是公司产品验证码是各式各样的,没办法用这种方法处理,所以暂时放弃了. 3.ocrad这个目前用过其.js版本,识别率还是比较低的,具体使
-
Python 图片文字识别的实现之PaddleOCR
目录 项目使用 项目结构 环境部署 1.安装Anaconda,构造虚拟环境 2.依赖包下载 测试代码 参数补充 总结 前言 什么是OCR? 光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程.简而言之,检测图像中的文本资料,并且识别出文本的内容. 那么有哪些应用场景呢? 其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息.车辆车牌号识别.自动驾驶等.我们的生活中,机器学习已