浅谈python爬虫使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少。原因他也大概分析了下,就是后面的图片是动态加载的。他的问题就是这部分动态加载的图片该怎么爬取到。
分析
他的代码比较简单,主要有以下的步骤:使用BeautifulSoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
data=requests.get("https://tieba.baidu.com/index.html",headers=headers)
html=BeautifulSoup(data.text,'lxml')
前面提到过,有部分图片是动态加载的,那么首先我们得弄清楚,这部分图片是怎么动态加载的。在浏览器中打开百度贴吧的首页,可以明显的看到,在往下滚动滚动条的时候,当滚动到底部的时候,滚动条缩短了,并向上移动了一段距离。这个现象也正是有DOM元素动态的添加到了html文档的一个表现。动态加载数据无非就是ajax请求,而ajax本质上就是XMLHttpRequest请求(简称xhr)。在谷歌浏览器中,我们可以通过开发者工具的network面板来监测xhr请求。
刚打开首页时的xhr请求,这里的请求都和要爬取的图片无关。
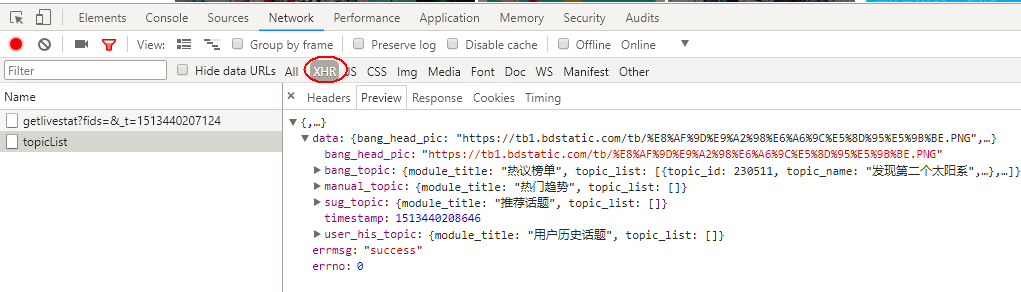
滚动条向下第1次滚动到底部,这里请求的是第20-40条热门动态,包含要爬取图片。
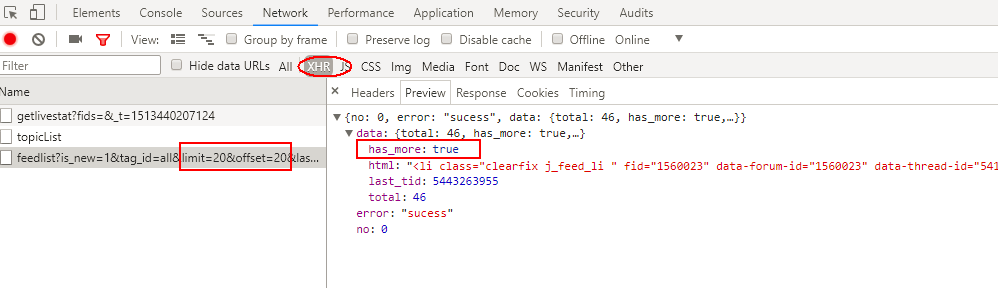
滚动条向下第2次滚动到底部,这里请求的是第40-60条热门动态,包含要爬取图片。并且返回的的has_more:false表明没有跟多数据了。
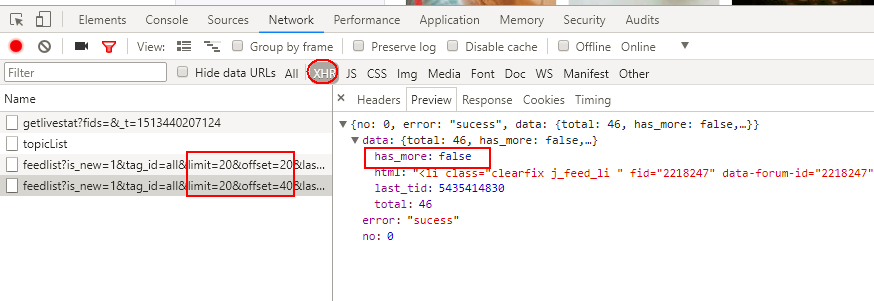
滚动条向下第3次滚动到底部,再无xhr请求。
解决方案
根据上面的分析,我们已经明白,单纯使用BeautifulSoup进行爬虫的时候,只能爬取到1-20条热门动态里面的图片。为了爬取到完整的热门动态里面的图片,我们则需要模拟浏览器的滚动条滚动,让网页去触发xhr请求更多的热门动态。
在python中,如果需要模拟浏览器的行为,可以使用selenium库。selenium库是一个自动化测试框架,可以用来模拟测试浏览器的各种行为,这里我们使用它来模拟浏览器打开百度贴吧的首页,并模拟滚动条向下滚动到底部的操作。
安装
pip install selenium
下载浏览器驱动
火狐浏览器驱动,其下载地址是:https://github.com/mozilla/geckodriver/releases
谷歌浏览器驱动,其下载地址是:http://chromedriver.storage.googleapis.com/index.html?path=2.33/
opera浏览器驱动,其下载地址是:https://github.com/operasoftware/operachromiumdriver/releases
对照自己电脑安装的浏览器和对应的版本,分别从上面的地址下载驱动文件,也可以从我的github项目中统一下载以上几个驱动(地址:https://github.com/Sesshoumaru/attachments/tree/master/Selenium%20WebDriver)。下载解压后,将所在的目录添加系统的环境变量中。当然你也可以将下载下来的驱动放到python安装目录的lib目录中,因为它本身已经存在于环境变量(我就是这么干的)。
使用python代码模拟浏览器行为
要使用selenium先需要定义一个具体browser对象,这里就定义的时候就看你电脑安装的具体浏览器和安装的哪个浏览器的驱动。这里以火狐浏览器为例:
from selenium import webdriver browser = webdriver.Firefox()
再模拟打开贴吧首页:
browser.get(https://tieba.baidu.com/index.html)
再模拟滚动条滚动到底部
for i in range(1, 5):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
最后再使用BeautifulSoup,解析图片标签:
html = BeautifulSoup(browser.page_source, "lxml")
imgs = html.select("#new_list li img")
几个注意点
必须安装浏览器和浏览器驱动,并且浏览器和浏览器驱动要配到
即如果使用谷歌浏览器模拟网页行为,则需要下载谷歌浏览器驱动;
如果使用火狐浏览器模拟网页行为,则需要下载火狐浏览器驱动
浏览器驱动所在的目录要在环境变量中,或者定义浏览器browser的时候指定驱动的路径
selenium更多用法
查找元素
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("https://tieba.baidu.com/index.html")
new_list = browser.find_element_by_id('new_list')
user_name = browser.find_element_by_name ('user_name')
active = browser.find_element_by_class_name ('active')
p = browser.find_element_by_tag_name ('p')
# find_element_by_name 通过name查找单个元素
# find_element_by_xpath 通过xpath查找单个元素
# find_element_by_link_text 通过链接查找单个元素
# find_element_by_partial_link_text 通过部分链接查找单个元素
# find_element_by_tag_name 通过标签名称查找单个元素
# find_element_by_class_name 通过类名查找单个元素
# find_element_by_css_selector 通过css选择武器查找单个元素
# find_elements_by_name 通过name查找多个元素
# find_elements_by_xpath 通过xpath查找多个元素
# find_elements_by_link_text 通过链接查找多个元素
# find_elements_by_partial_link_text 通过部分链接查找多个元素
# find_elements_by_tag_name 通过标签名称查找多个元素
# find_elements_by_class_name 通过类名查找多个元素
# find_elements_by_css_selector 通过css选择武器查找多个元素
获取元素信息
btn_more = browser.find_element_by_id('btn_more')
print(btn_more.get_attribute('class')) # 获取属性
print(btn_more.get_attribute('href')) # 获取属性
print(btn_more.text) # 获取文本值
元素交互操作
btn_more = browser.find_element_by_id('btn_more')
btn_more.click() # 模拟点击,可以模拟点击加载更多
input_search = browser.find_element(By.ID,'q')
input_search.clear() # 清空输入
执行JavaScript
# 执行JavaScript脚本
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python模拟鼠标点击实现方法(将通过实例自动化模拟在360浏览器中自动搜索python)
- Python使用win32com实现的模拟浏览器功能示例
- 在Python中使用mechanize模块模拟浏览器功能
相关推荐
-
Python使用win32com实现的模拟浏览器功能示例
本文实例讲述了Python使用win32com实现的模拟浏览器功能.分享给大家供大家参考,具体如下: # -*- coding:UTF-8 -*- #!/user/bin/env python ''' Created on 2010-9-1 @author: chenzehe ''' import win32com.client from time import sleep loginurl='http://passport.cnblogs.com/login.aspx' loginouturl
-
在Python中使用mechanize模块模拟浏览器功能
知道如何快速在命令行或者python脚本中实例化一个浏览器通常是非常有用的. 每次我需要做任何关于web的自动任务时,我都使用这段python代码去模拟一个浏览器. import mechanize import cookielib # Browser br = mechanize.Browser() # Cookie Jar cj = cookielib.LWPCookieJar() br.set_cookiejar(cj) # Browser options br.set_handle_eq
-

Python模拟鼠标点击实现方法(将通过实例自动化模拟在360浏览器中自动搜索python)
一.准备工作: 安装pywin32,后面开发需要pywin32的支持,否则无法完成与windows层面相关的操作. pywin32的具体安装及注意事项: 1.整体开发环境: 基于windows7操作系统; 提前安装python(因为篇幅问题,在此不详细讲解python环境的安装,大家可以自备楼梯): 大家可以在cmd中测试下python环境是否安装好: 大家可以看到我电脑上已经安装好了Python,并显示版本与是V 3.6.2. 注:自己电脑上的Python版本号一定要知道,后面安装pywin3
-
浅谈python爬虫使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动态加载的图片该怎么爬取到. 分析 他的代码比较简单,主要有以下的步骤:使用BeautifulSoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来. headers = { 'User-Agent':'Mozilla/5.0 (Win
-
浅谈Python爬虫原理与数据抓取
通用爬虫和聚焦爬虫 根据使用场景,网络爬虫可分为通用爬虫和聚焦爬虫两种. 通用爬虫 通用网络爬虫 是 捜索引擎抓取系统(Baidu.Google.Yahoo等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 通用搜索引擎(Search Engine)工作原理 通用网络爬虫从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果. 第一步:抓取网页
-
浅谈Python爬虫基本套路
什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析.或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析. 有什么作用? 通过有效的爬虫手段批量采集数据,可以降低人工成本,提高有效数据量,给予运营/销售的数据支撑,加快产品发展. 业界的情况 目前互联网产品竞争激烈,业界大部分都会使用爬虫技术对
-
Python使用Selenium模拟浏览器自动操作功能
概述 在进行网站爬取数据的时候,会发现很多网站都进行了反爬虫的处理,如JS加密,Ajax加密,反Debug等方法,通过请求获取数据和页面展示的内容完全不同,这时候就用到Selenium技术,来模拟浏览器的操作,然后获取数据.本文以一个简单的小例子,简述Python搭配Tkinter和Selenium进行浏览器的模拟操作,仅供学习分享使用,如有不足之处,还请指正. 什么是Selenium? Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在
-
Python paramiko 模块浅谈与SSH主要功能模拟解析
疫情还没结束,小编只能宅在家里,哪哪也去不了,今天突发奇想给大家分享一篇教程关于Python paramiko 模块浅谈与SSH主要功能模拟解析. 大家都知道,通过SSH服务可以远程连接到Linux服务器,查看上面的日志状态,批量配置远程服务器,文件上传,文件下载等,Python的paramiko模块同样实现了这一功能. 首先我们需要安装这一模块,pycharm环境中如下操作 一,安装paramiko模块 PyCharm→Preferences→Project:项目名→Project Inter
-
Python爬虫之Selenium实现关闭浏览器
前言:WebDriver提供了两个关闭浏览器的方法,一个是前边使用quit()方法,另一个是close()方法 close():关闭当前窗口 quit():关闭所有窗口 quit()是关闭所有窗口,就不过多说了,测试一下close() from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() driver.get("h
-
python使用selenium模拟浏览器进入好友QQ空间留言功能
首先下载selenium模块,pip install selenium,下载一个浏览器驱动程序(我这里使用谷歌). #导入 #注意python各版本find_element()方法的变化(python3.10) from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By # 创建一个模拟浏览器对象,然
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
浅谈python中对于json写入txt文件的编码问题
最近一直在研究python+selenium+beautifulsoup的爬虫,但是存入数据库还有写入txt文件里面的时候一直都是unicode编码的格式. 接下来就是各种翻阅文档,查找谷歌和度娘,但是都没有具体的说明是什么问题. 结果根据自己的代码发现,原来是一句代码写到后面去了. name = json.dumps('中国你好', ensure_ascii=False) #重点就是这一句代码 date = time.strftime('%Y-%m-%d', time.localtime(ti
-
python 爬虫之selenium可视化爬虫的实现
之所以把selenium爬虫称之为可视化爬虫 主要是相较于前面所提到的几种网页解析的爬虫方式 selenium爬虫主要是模拟人的点击操作 selenium驱动浏览器并进行操作的过程是可以观察到的 就类似于你在看着别人在帮你操纵你的电脑,类似于别人远程使用你的电脑 当然了,selenium也有无界面模式 快速入门 selenium基本介绍: selenium 是一套完整的web应用程序测试系统, 包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Contro