python2.7+selenium2实现淘宝滑块自动认证功能
本文为大家分享了python2.7+selenium2实现淘宝滑块自动认证的具体代码,供大家参考,具体内容如下
1.编译环境
操作系统:win7;语言:python2.7+selenium2;ide:pycharm;浏览器:IE10,chrome
2.1意外开始
今天登录淘宝时候发现吧密码搞忘了,选择找回密码时淘宝居然加了滑块认证。
恰巧自己也在学习selenium,就想试一试能不能实现自动拖动滑块。
2.2 度娘查找
由于自己没多少思路,第一选择就是问度娘,终于找到一篇文章,该文章使用C#实现了该功能,并提到需要定位滑块元素在网页和桌面的坐标,而这个功能直接可以用selenium中的查找元素接口搞定,那么剩下最后一个问题就是如何得知滑块的位移量。(原谅我忘记该文章的名字了)
2.3 开始试验
大家在手动操作滑块的时候会发现如果滑块位移不够,它要自动还原就不能触发认证成功环节,所以我用一个笨方法先手动操作看看。打开浏览器按F12,得到代码如下:
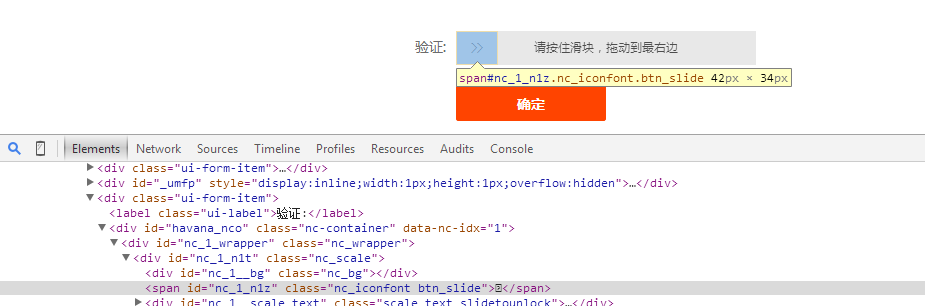
然后拖动滑块位移,发现滑块元素的style一直在变化如图:
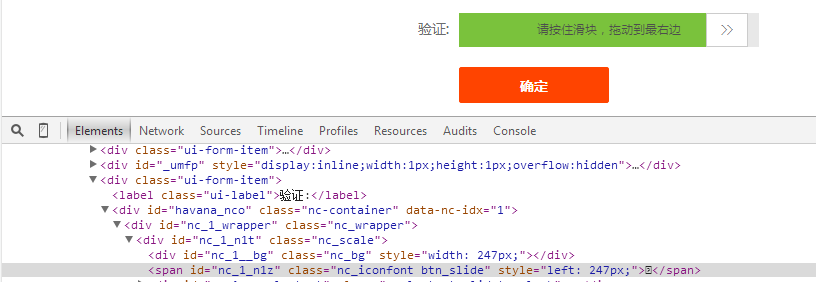
现在大概清楚右位移量为300px,OK开始写代码,经过很多次试验确定滑块移动后有三种情况:
1无响应:请按住滑块,拖到到最右边;
2失败:哎呀,加载失败了,请点击刷新页面
3成功:请点击图中xx字,请在下方输入xx字
解决思路:无响应时,需要重复拖动滑块,直到成功为止;失败了,需要自动点击刷新按钮,使滑块回到无响应状态;成功了,暂时是直接退出浏览器,验证码识别还在研究中,以后补齐。
2.4 完整代码
PS:粘贴上去的代码,我不知道怎么对齐,如果大家直接复制运行,可能会报错,请自动修改。
# encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
#使用谷歌浏览器,方便查看效果,如果追求速度可以用phantomJS
driver=webdriver.Chrome()
#调整最大窗口,否则某些元素无法显示
driver.maximize_window()
#使用淘宝找回密码界面做测试
driver.get('https://passport.taobao.com/ac/password_find.htm?spm=a2107.1.0.0.phBxhD&from_site=0')
time.sleep(5)#等待滑动模块和其他JS文件加载完毕!
while True:
try:
#定位滑块元素
source=driver.find_element_by_xpath("//*[@id='nc_1_n1z']")
#定义鼠标拖放动作
ActionChains(driver).drag_and_drop_by_offset(source,400,0).perform()
#等待JS认证运行,如果不等待容易报错
time.sleep(2)
#查看是否认证成功,获取text值
text=driver.find_element_by_xpath("//div[@id='nc_1__scale_text']/span")
#目前只碰到3种情况:成功(请在在下方输入验证码,请点击图);无响应(请按住滑块拖动);失败(哎呀,失败了,请刷新)
if text.text.startswith(u'请在下方'):
print('成功滑动')
break
if text.text.startswith(u'请点击'):
print('成功滑动')
break
if text.text.startswith(u'请按住'):
continue
except Exception as e:
#这里定位失败后的刷新按钮,重新加载滑块模块
driver.find_element_by_xpath("//div[@id='havana_nco']/div/span/a").click()
print(e)
#退出浏览器,如果浏览器打开多个窗口,可以使用driver.close()关闭当前窗口而不是关闭浏览器
driver.quit()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python使用Selenium+BeautifulSoup爬取淘宝搜索页
- python编程使用selenium模拟登陆淘宝实例代码
- python实现二维码扫码自动登录淘宝
- Python模拟登陆淘宝并统计淘宝消费情况的代码实例分享
相关推荐
-
python编程使用selenium模拟登陆淘宝实例代码
selenium简介 selenium 是一个web的自动化测试工具,不少学习功能自动化的同学开始首选selenium ,相因为它相比QTP有诸多有点: * 免费,也不用再为破解QTP而大伤脑筋 * 小巧,对于不同的语言它只是一个包而已,而QTP需要下载安装1个多G 的程序. * 这也是最重要的一点,不管你以前更熟悉C. java.ruby.python.或都是C# ,你都可以通过selenium完成自动化测试,而QTP只支持VBS * 支持多平台:windows.linux.MAC ,支持多浏
-
Python使用Selenium+BeautifulSoup爬取淘宝搜索页
使用Selenium驱动chrome页面,获得淘宝信息并用BeautifulSoup分析得到结果. 使用Selenium时注意页面的加载判断,以及加载超时的异常处理. import json import re from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.com
-

Python模拟登陆淘宝并统计淘宝消费情况的代码实例分享
支付宝十年账单上的数字有点吓人,但它统计的项目太多,只是想看看到底单纯在淘宝上支出了多少,于是写了段脚本,统计任意时间段淘宝订单的消费情况,看那结果其实在淘宝上我还是相当节约的说. 脚本的主要工作是模拟了浏览器登录,解析"已买到的宝贝"页面以获得指定的订单及宝贝信息. 使用方法见代码或执行命令加参数-h,另外需要BeautifulSoup4支持,BeautifulSoup的官方项目列表页:https://www.crummy.com/software/BeautifulSoup/bs4
-
python实现二维码扫码自动登录淘宝
一个小项目自动登录淘宝联盟抓取数据,由于之前在Github上看过类似用Python写的代码因此选择用Python来写,第一次用Python正式写程序还是被其"简单"所震撼,当然用的时候还是对其(2.7版)编码.迁移环境等问题所困扰,还好后来都解决了. 言归正传,抓取淘宝联盟的数据首先要解决的就是登录的问题,之前一般会碰到验证码的困扰,现在支持二维码扫码登录反而简单了,以下是登录的Python代码,主要是获取二维码打印,然后不断的检查扫码状态,如果过期了重新请求二维码(主要看逻辑,由于有
-
python2.7+selenium2实现淘宝滑块自动认证功能
本文为大家分享了python2.7+selenium2实现淘宝滑块自动认证的具体代码,供大家参考,具体内容如下 1.编译环境 操作系统:win7:语言:python2.7+selenium2:ide:pycharm:浏览器:IE10,chrome 2.1意外开始 今天登录淘宝时候发现吧密码搞忘了,选择找回密码时淘宝居然加了滑块认证. 恰巧自己也在学习selenium,就想试一试能不能实现自动拖动滑块. 2.2 度娘查找 由于自己没多少思路,第一选择就是问度娘,终于找到一篇文章,该文章使用C#实现
-
selenium 反爬虫之跳过淘宝滑块验证功能的实现代码
在处理问题的之前,给大家个第一个锦囊! 你需要将chorme更新到最新版版本84,下载对应的chorme驱动 链接:http://chromedriver.storage.googleapis.com/index.html 注意 划重点!!一定要做这一步,因为我用的83的chorme他是不行滴,~~~~~~~ 问题 1.一周前我的滑块验证代码还是可以OK的,完全没问题!附代码 low一眼 url = "https://login.taobao.com/member/login.jhtml&quo
-
Python 脚本实现淘宝准点秒杀功能
准备软件 下载地址 : https://download.csdn.net/download/tangcv/11968538 pycharm文件太大,不好上传 ,直接去官网下载:https://www.jetbrains.com/pycharm/download/#section=windows 配置环境 1.安装python 双击 然后跟着感觉走, 创建一个专门的文件夹用来放python环境 安装好 2..安装pycharm 1.首先去Pycharm官网,或者直接输入网址:http://www
-
Android ViewDragHelper实现京东、淘宝拖拽详情功能的实现
先上效果图,如果大家感觉不错,请参考实例代码,效果图如下所述: 要实现这个效果有三种方式: ① 手势 ② 动画 ③ ViewDragHelper 这里我使用的是ViewDragHelper类. public class ViewDragLayout extends ViewGroup { //垂直方向的滑动速度 private static final int VEL_THRESHOLD = 300; //垂直方向的滑动距离 private static final int DISTANCE_T
-
Python使用Selenium模块实现模拟浏览器抓取淘宝商品美食信息功能示例
本文实例讲述了Python使用Selenium模块实现模拟浏览器抓取淘宝商品美食信息功能.分享给大家供大家参考,具体如下: import re from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected
-
Vue实现淘宝购物车三级选中功能详解
最近在练习商城项目,记录下实现购物车三级选中的过程(小白一个,水平很菜) 效果图: 实现: 1.全选时所有商品+店铺全部选中:反之全部取消选中 2.店铺选中时,当前店铺内所有商品选中:反之取消选中 3.店铺内商品全选 → 所属店铺选中:反之取消选中店铺 4.店铺+所有商品全选 → 全选按钮选中:反之取消选中 首先说明一下,我使用了vuex来管理购物车数据,所有改变按钮状态的方法都写在mutaition里 const state = { cartList: [], // 购物车列表 totalCo
-
Android项目类似淘宝 电商 搜索功能,监听软键盘搜索事件,延迟自动搜索,以及时间排序的搜索历史记录的实现
最近跳槽去新公司,接受的第一个任务是在 一个电商模块的搜索功能以及搜索历史记录的实现. 需求和淘宝等电商的功能大体差不多,最上面一个搜索框,下面显示搜索历史记录.在EditText里输入要搜索的关键字后,按软键盘的搜索按键/延迟xxxxms后自动搜索.然后将搜索的内容展示给用户/提示用户没有搜到相关信息. 历史记录是按时间排序的,最新的在前面,输入以前搜索过的关键字,例如牛仔裤(本来是第二条),会更新这条记录的时间,下次再看,牛仔裤的排列就在第一位了.并且有清除历史记录的功能. 整理需求,大致需
-
js实现淘宝浏览商品放大镜功能
本文实例为大家分享了js实现淘宝浏览商品放大镜的具体代码,供大家参考,具体内容如下 1.准备两张图片,其中一张图片分辨率为另一张图片的二倍. 2.前端页面布局 //box1位左侧原图,box2为右侧放大图额显示框,son为iv class="box1"> <div class="son"></div> <div class="ceng"></div> </div> <div
-
javascript淘宝主图放大镜功能
工欲善其事,必先利其器.想要实现某一种效果,我们必须要先了解其中的原理. 放大镜的功能就是通过获取鼠标在小图中的位置,然后根据大小图的尺寸比例换算出大图需要显示的部分,然后使用定位让大图要显示的部分出现在右边的边框内. 然后看代码,根据代码看讲解会更容易理解. html部分 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title&
-
纯js仿淘宝京东商品放大镜功能
效果图: 代码如下: <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>无标题</title> <style> *{ margin: 0px; padding: 0px; } .imgContent{ width: 420px; height: 300px; pos