python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10
工具:fiddler postman 安卓模拟器
首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍。
配置允许https
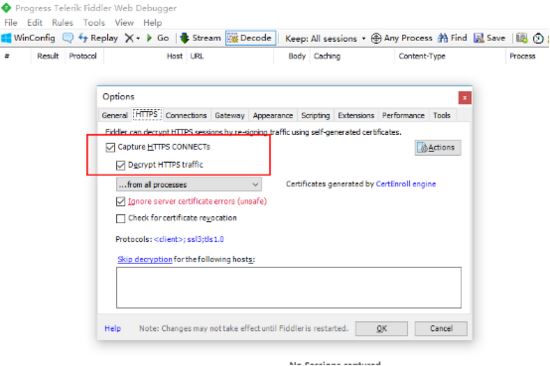
配置允许远程连接 也就是打开http代理
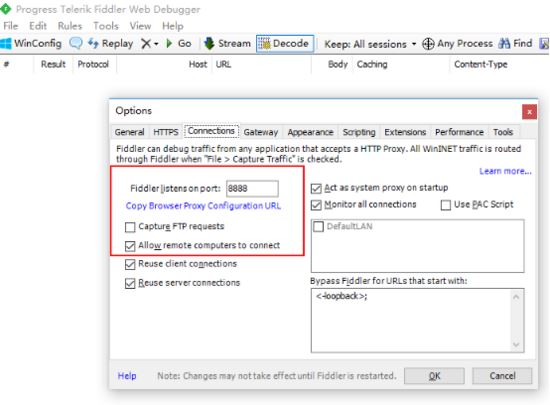
电脑ip: 192.168.1.110
然后 确保手机和电脑是在一个局域网下,可以通信。由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的。
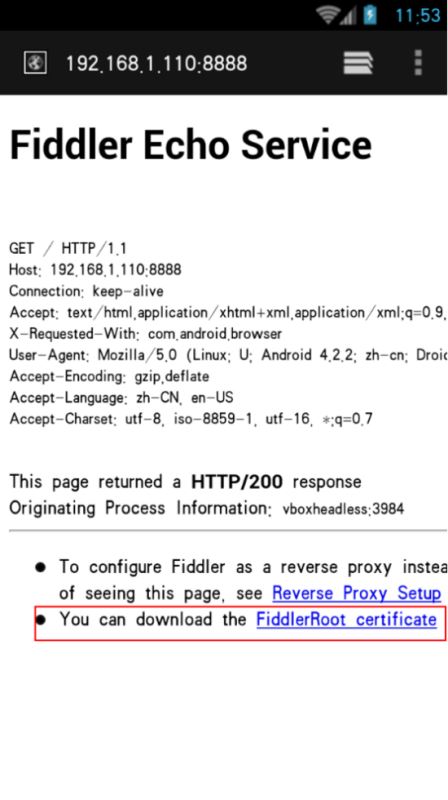
打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能抓包
安装证书之后,在 WiFi设置 修改网络 手动指定http代理
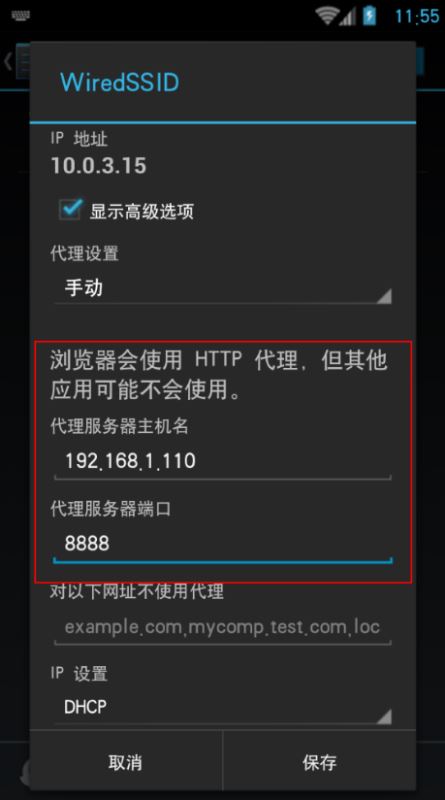
保存后就可以了,fiddler就可以抓到app的数据了,打开快手 刷新,可以 看到有很多http请求进来,一般接口地址之类的很明显的,可以看到 是json类型的
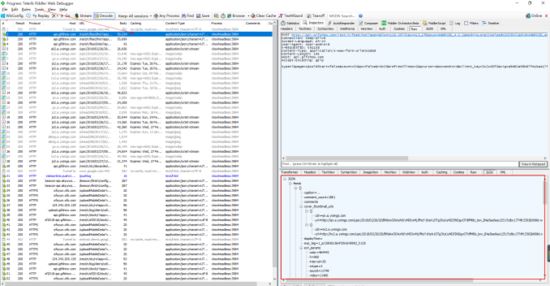
http post请求,返回数据是json ,展开后发现一共是20条视频信息,先确保是否正确,找一个视频链接看下。
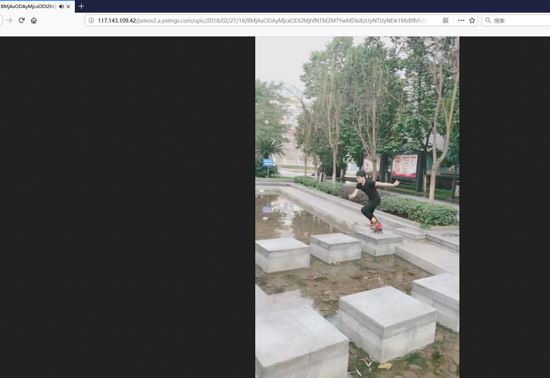
ok 是可以播放的 很干净也没有水印。
那么现在打开 postman 来模拟这个post 看看有没有检验参数
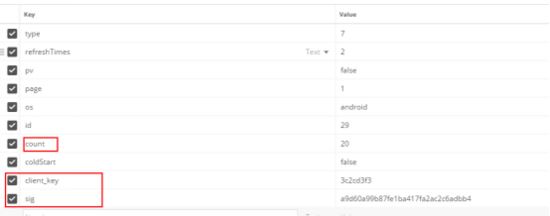
一共是这么多参数,我以为 client_key 和 sign 会验证...可是 后面 发现我错了 啥也没验证 就这样提交过去就行...
form-data 方式提交则报错
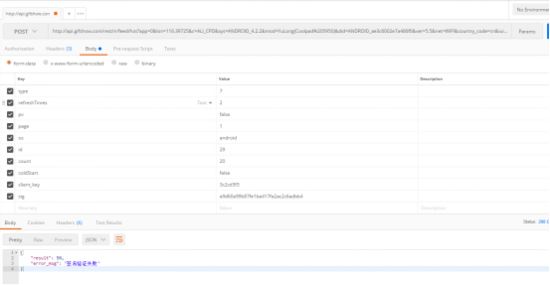
那换 raw 这种
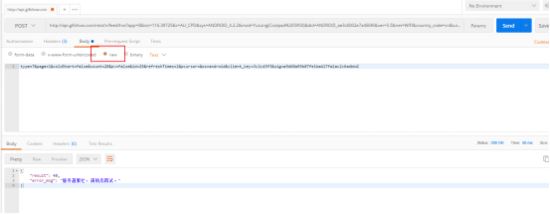
报错信息不一样了,试试加上 headers
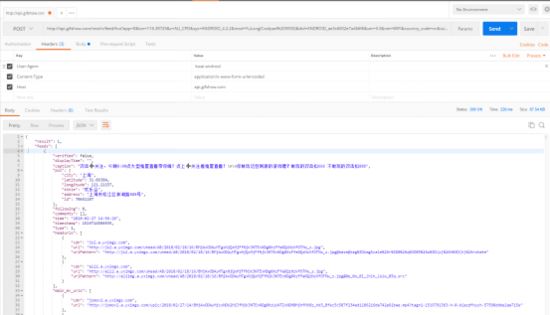
nice 成功返回数据,我又多试几次,发现每次返回结果不一样,都是 20个视频,刚才其中post参数中 有个page=1 可能一直都是第一页 就像一直在手机上不往下翻了 就开始一直刷新那样,反正 也无所谓,只要返回数据 不重复就好。
下面就开始上代码
# -*-coding:utf-8-*-
# author : Corleone
import urllib2,urllib
import json,os,re,socket,time,sys
import Queue
import threading
import logging
# 日志模块
logger = logging.getLogger("AppName")
formatter = logging.Formatter('%(asctime)s %(levelname)-5s: %(message)s')
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter
logger.addHandler(console_handler)
logger.setLevel(logging.INFO)
video_q = Queue.Queue() # 视频队列
def get_video():
url = "http://101.251.217.210/rest/n/feed/hot?app=0&lon=121.372027&c=BOYA_BAIDU_PINZHUAN&sys=ANDROID_4.1.2&mod=HUAWEI(HUAWEI%20C8813Q)&did=ANDROID_e0e0ef947bbbc243&ver=5.4&net=WIFI&country_code=cn&iuid=&appver=5.4.7.5559&max_memory=128&oc=BOYA_BAIDU_PINZHUAN&ftt=&ud=0&language=zh-cn&lat=31.319303 "
data = {
'type': 7,
'page': 2,
'coldStart': 'false',
'count': 20,
'pv': 'false',
'id': 5,
'refreshTimes': 4,
'pcursor': 1,
'os': 'android',
'client_key': '3c2cd3f3',
'sig': '22769f2f5c0045381203fc57d1b5ad9b'
}
req = urllib2.Request(url)
req.add_header("User-Agent", "kwai-android")
req.add_header("Content-Type", "application/x-www-form-urlencoded")
params = urllib.urlencode(data)
try:
html = urllib2.urlopen(req, params).read()
except urllib2.URLError:
logger.warning(u"网络不稳定 正在重试访问")
html = urllib2.urlopen(req, params).read()
result = json.loads(html)
reg = re.compile(u"[\u4e00-\u9fa5]+") # 只匹配中文
for x in result['feeds']:
try:
title = x['caption'].replace("\n","")
name = " ".join(reg.findall(title))
video_q.put([name, x['photo_id'], x['main_mv_urls'][0]['url']])
except KeyError:
pass
def download(video_q):
path = u"D:\快手"
while True:
data = video_q.get()
name = data[0].replace("\n","")
id = data[1]
url = data[2]
file = os.path.join(path, name + ".mp4")
logger.info(u"正在下载:%s" %name)
try:
urllib.urlretrieve(url,file)
except IOError:
file = os.path.join(path, u"神经病呀"+ '%s.mp4') %id
try:
urllib.urlretrieve(url, file)
except (socket.error,urllib.ContentTooShortError):
logger.warning(u"请求被断开,休眠2秒")
time.sleep(2)
urllib.urlretrieve(url, file)
logger.info(u"下载完成:%s" % name)
video_q.task_done()
def main():
# 使用帮助
try:
threads = int(sys.argv[1])
except (IndexError, ValueError):
print u"\n用法: " + sys.argv[0] + u" [线程数:10] \n"
print u"例如:" + sys.argv[0] + " 10" + u" 爬取视频 开启10个线程 每天爬取一次 一次2000个视频左右(空格隔开)"
return False
# 判断目录
if os.path.exists(u'D:\快手') == False:
os.makedirs(u'D:\快手')
# 解析网页
logger.info(u"正在爬取网页")
for x in range(1,100):
logger.info(u"第 %s 次请求" % x)
get_video()
num = video_q.qsize()
logger.info(u"共 %s 视频" %num)
# 多线程下载
for y in range(threads):
t = threading.Thread(target=download,args=(video_q,))
t.setDaemon(True)
t.start()
video_q.join()
logger.info(u"-----------全部已经爬取完成---------------")
main()
下面测试

多线程下载 每次下载 2000 个视频左右 默认下载到D:\快手
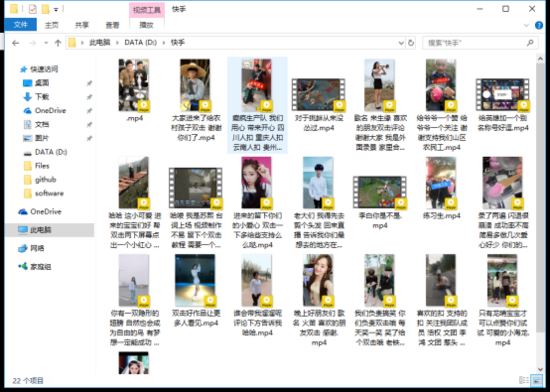
好了 这次就到这结束了,其实也很简单,快手竟然没有加密。。。因为 爬 抖音的时候 就碰到问题了.....
总结
以上所述是小编给大家介绍的python爬虫爬取快手视频多线程下载,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- Python实现的多线程http压力测试代码
- 深入理解 Python 中的多线程 新手必看
- python并发编程之多进程、多线程、异步和协程详解
- Python控制多进程与多线程并发数总结
- python3写爬取B站视频弹幕功能
- 以视频爬取实例讲解Python爬虫神器Beautiful Soup用法
相关推荐
-

Python控制多进程与多线程并发数总结
一.前言 本来写了脚本用于暴力破解密码,可是1秒钟尝试一个密码2220000个密码我的天,想用多线程可是只会一个for全开,难道开2220000个线程吗?只好学习控制线程数了,官方文档不好看,觉得结构不够清晰,网上找很多文章也都不很清晰,只有for全开线程,没有控制线程数的具体说明,最终终于根据多篇文章和官方文档算是搞明白基础的多线程怎么实现法了,怕长时间不用又忘记,找着麻烦就贴这了,跟我一样新手也可以参照参照. 先说进程和线程的区别: 地址空间:进程内的一个执行单元;进程至少有一个线程;它们共
-
python并发编程之多进程、多线程、异步和协程详解
最近学习python并发,于是对多进程.多线程.异步和协程做了个总结. 一.多线程 多线程就是允许一个进程内存在多个控制权,以便让多个函数同时处于激活状态,从而让多个函数的操作同时运行.即使是单CPU的计算机,也可以通过不停地在不同线程的指令间切换,从而造成多线程同时运行的效果. 多线程相当于一个并发(concunrrency)系统.并发系统一般同时执行多个任务.如果多个任务可以共享资源,特别是同时写入某个变量的时候,就需要解决同步的问题,比如多线程火车售票系统:两个指令,一个指令检查票是否卖完
-
python3写爬取B站视频弹幕功能
需要准备的环境: 一个B站账号,需要先登录,否则不能查看历史弹幕记录 联网的电脑和顺手的浏览器,我用的Chrome Python3环境以及request模块,安装使用命令,换源比较快: pip3 install request -i http://pypi.douban.com/simple 爬取步骤: 登录后打开需要爬取的视频页面,打开开发者工具台,Chrome可以使用F12快捷键,选择network监听请求 点击查看历史弹幕,获取请求 其中rolldate后面的数字表示该视频对应的弹幕号,返
-
以视频爬取实例讲解Python爬虫神器Beautiful Soup用法
1.安装BeautifulSoup4 easy_install安装方式,easy_install需要提前安装 easy_install beautifulsoup4 pip安装方式,pip也需要提前安装.此外PyPi中还有一个名字是 BeautifulSoup 的包,那是 Beautiful Soup3 的发布版本.在这里不建议安装. pip install beautifulsoup4 Debain或ubuntu安装方式 apt-get install Python-bs4 你也可以通过源码安
-
Python实现的多线程http压力测试代码
本文实例讲述了Python实现的多线程http压力测试代码.分享给大家供大家参考,具体如下: # Python version 3.3 __author__ = 'Toil' import sys, getopt import threading def httpGet(url, file): import http.client conn = http.client.HTTPConnection(url) conn.request("GET", file) r = conn.getr
-
深入理解 Python 中的多线程 新手必看
示例1 我们将要请求五个不同的url: 单线程 import time import urllib2 defget_responses(): urls=[ 'http://www.baidu.com', 'http://www.amazon.com', 'http://www.ebay.com', 'http://www.alibaba.com', 'http://www.jb51.net' ] start=time.time() forurlinurls: printurl resp=urll
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
Python爬虫爬取有道实现翻译功能
准备 首先安装爬虫urllib库 pip install urllib 获取有道翻译的链接url 需要发送的参数在form data里 示例 import urllib.request import urllib.parse url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' data = {} data['i'] = 'i love python' data['from'] = 'AUTO'
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
python爬虫爬取某网站视频的示例代码
把获取到的下载视频的url存放在数组中(也可写入文件中),通过调用迅雷接口,进行自动下载.(请先下载迅雷,并在其设置中心的下载管理中设置为一键下载) 实现代码如下: from bs4 import BeautifulSoup import requests import os,re,time import urllib3 from win32com.client import Dispatch class DownloadVideo: def __init__(self): self.r = r
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的
-
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频. 一.实现登录账号 这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码.登录后,采用session保持登录. 1.获取验证码地址 第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608 颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此
-
如何实现python爬虫爬取视频时实现实时进度条显示
目录 一.全部代码展示 二.解释 1.with closing with用法(实现上下文管理) closing用法(完美解决上述问题) 2.文件流stream 3.response.headers['content-length'] 4.response.iter_content() 5.\r和% 三.结果展示 四.总结 前言: 在爬取并下载网页上的视频的时候,我们需要实时进度条,这可以帮助我们更直观的看到视频的下载进度. 一.全部代码展示 from contextlib import clos
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am