10 行Python 代码实现 AI 目标检测技术【推荐】
只需10行Python代码,我们就能实现计算机视觉中目标检测。
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg")) for eachObject in detections: print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
没错,用这寥寥10行代码,就能实现目前AI产品中应用广泛的目标检测技术。
看完了代码,下面容我们聊聊目标检测背后的技术背景,并解读这10行Python代码的由来和实现原理。
目标检测简介
人工智能的一个重要领域就是计算机视觉,它是指计算机及软件系统识别和理解图像与视频的科学。计算机视觉包含很多细分方向,比如图像识别、目标检测、图像生成和图像超分辨率等。其中目标检测由于用途广泛,在计算机视觉领域的意义最为深远。
目标检测是指计算机和软件系统能够定位出图像/画面中的物体,并识别出它们。目标检测技术已经广泛应用于人脸检测、车辆检测、人流量统计、网络图像、安防系统和无人车等领域。和其它计算机视觉技术一样,目标检测未来会进一步成为人工智能的重要组成部分,有着广阔的发展前景。
不过,在软件应用和系统中使用现代目标检测方法以及根据这些方法创建应用,并非简单直接。早期的目标检测实现主要是应用一些经典算法,比如OpenCV中支持的算法。然而这些算法的表现并不稳定,在不同情况下差异巨大。
2012年深度学习技术的突破性进展,催生了一大批高度精准的目标检测算法,比如R-CNN,Fast-RCNN,Faster-RCNN,RetinaNet和既快又准的SSD及YOLO。使用这些基于深度学习的方法和算法,需要理解大量的数学和深度学习框架。现在全世界有数以百万计的开发者在借助目标检测技术创造新产品新项目,但由于理解和使用较为复杂困难,仍有很多人不得要领。
为了解决这个困扰开发者们的问题,计算机视觉专家Moses Olafenwa带领团队推出了Python库ImageAI,能让开发人员只需寥寥数行代码就能很容易的将最先进的计算机视觉技术应用到自己的项目和产品中。
我们开头所示的10行代码实现,就是要用到ImageAI。
如何借助ImageAI轻松实现目标检测
使用ImageAI执行目标检测,你只需以下4步:
1.在电脑上安装Python
2.安装ImageAI及其环境依赖
3.下载目标检测模块文件
4.运行示例代码,就是我们展示的那10行
下面我们一步步详细讲解。
1)从Python官网下载和安装Python 3
2)通过pip安装如下环境依赖
1.Tensorflow
pip install tensorflow
2.Numpy
pip install numpy
3.SciPy
pip install scipy
4.OpenCV
pip install opencv-python
5.Pillow
pip install pillow
6.Matplotlib
pip install matplotlib
7.H5py
pip install h5py
8.Keras
pip install keras
9.ImageAI
pip install
3)通过该 链接下载RetinaNet 模型文件用于目标检测。
到了这里我们已经安装好了所有依赖,就可以准备写自己的首个目标检测代码了。 创建一个Python文件,为其命名(比如FirstDetection.py),然后将如下代码写到文件中,再把RetinaNet模型文件以及你想检测的图像拷贝到包含该Python文件的文件夹里。
FirstDetection.py
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg")) for eachObject in detections: print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
然后运行代码,等待控制台打印结果。等控制台打印出结果后,就可以打开FirstDetection.py所在的文件夹,你就会发现有新的图像保存在了里面。比如下面两张示例图像,以及执行目标检测后保存的两张新图像。
目标检测之前:


目标检测之后:
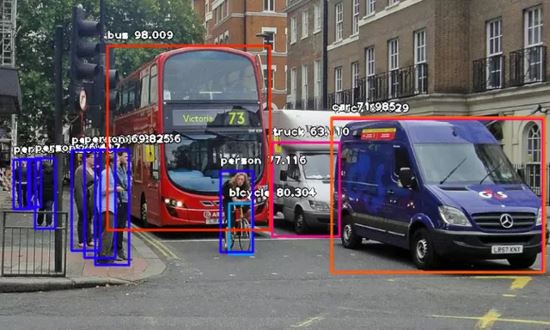

我们可以看到图像上显示了检测出的物体名称及概率。
解读10行代码
下面我们解释一下这10行代码的工作原理。
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd()
在上面3行代码中,我们在第一行导入了ImageAI目标检测类,在第二行导入Python os类,在第三行定义了一个变量,获取通往我们的Python文件、RetinaNet模型文件和图像所在文件夹的路径。
detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))
在上面5行代码中,我们在第一行定义我们的目标检测类,在第二行设定RetinaNet的模型类型,在第三行将模型路径设置为RetinaNet模型的路径,在第四行将模型加载到目标检测类中,然后我们在第五行调用检测函数,并在输入和输出图像路径中进行解析。
for eachObject in detections: print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
在上面两行代码中,我们迭代了第一行中detector.detectObjectFromImage函数返回的所有结果,然后打印出第二行中模型对图像上每个物体的检测结果(名称和概率)。
ImageAI支持很多强大的目标检测自定义功能,其中一项就是能够提取在图像上检测到的每个物体的图像。只需将附加参数extract_detected_objects=True解析为detectObjectsFromImage函数,如下所示,目标检测类就会为图像物体创建一个文件夹,提取每张图像,将它们保存在新创建的文件夹中,并返回一个包含通过每张图像的路径的额外数组。
detections, extracted_images = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"), extract_detected_objects=True)
我们用前面的第一张图像作为例子,可以得到图像中检测到的各个物体的单独图像:

ImageAI提供了很多功能,能够用于各类目标检测任务的自定义和生产部署。包括:
-调整最小概率:默认概率小于50%的物体不会显示,如有需要,你可以自行调整这个数字。
-自定义目标检测:使用提供的CustomObject类,你可以检测一个或多个特定物体。
-调整检测速度:可以通过将检测速度设为“快”“更快”“最快”三个不同等级,调整检测速度。
-输入输出类型:你可以自定义图像的路径,Numpy数组或图像的文件流为输入输出。
诚然,单看这10行代码每一行,谈不上惊艳,也借助了不少库,但是仅用10行代码就能让我们轻松实现之前很麻烦的目标检测,还是能谈得上“给力”二字。
总结
以上所述是小编给大家介绍的10 行Python 代码实现 AI 目标检测技术,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

详解Python发送email的三种方式
Python发送email的三种方式,分别为使用登录邮件服务器.使用smtp服务.调用sendmail命令来发送三种方法 Python发送email比较简单,可以通过登录邮件服务来发送,linux下也可以使用调用sendmail命令来发送,还可以使用本地或者是远程的smtp服务来发送邮件,不管是单个,群发,还是抄送都比较容易实现.本米扑博客先介绍几个最简单的发送邮件方式记录下,像html邮件,附件等也是支持的,需要时查文档即可. 一.登录邮件服务器 通过smtp登录第三方smtp邮箱发送邮件,支
-
使用50行Python代码从零开始实现一个AI平衡小游戏
集智导读: 本文会为大家展示机器学习专家 Mike Shi 如何用 50 行 Python 代码创建一个 AI,使用增强学习技术,玩耍一个保持杆子平衡的小游戏.所用环境为标准的 OpenAI Gym,只使用 Numpy 来创建 agent. 各位看官好,我(作者 Mike Shi--译者注)将在本文教大家如何用 50 行 Python 代码,教会 AI 玩一个简单的平衡游戏.我们会用到标准的 OpenAI Gym 作为测试环境,仅用 Numpy 创建我们的 AI,别的不用. 这个小游戏就是经典的
-
玩转python selenium鼠标键盘操作(ActionChains)
用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击.双击.点击鼠标右键.拖拽等等.而selenium给我们提供了一个类来处理这类事件--ActionChains selenium.webdriver.common.action_chains.ActionChains(driver) 这个类基本能够满足我们所有对鼠标操作的需求. 1.ActionChains基本用法 首先需要了解ActionChains的执行原理,当你调用ActionChains的方法时,不会立即执行
-
Python中asyncio与aiohttp入门教程
很多朋友对异步编程都处于"听说很强大"的认知状态.鲜有在生产项目中使用它.而使用它的同学,则大多数都停留在知道如何使用 Tornado.Twisted.Gevent 这类异步框架上,出现各种古怪的问题难以解决.而且使用了异步框架的部分同学,由于用法不对,感觉它并没牛逼到哪里去,所以很多同学做 Web 后端服务时还是采用 Flask.Django等传统的非异步框架. 从上两届 PyCon 技术大会看来,异步编程已经成了 Python 生态下一阶段的主旋律.如新兴的 Go.Rust.Eli
-
关于python下cv.waitKey无响应的原因及解决方法
按下键的时候,焦点要落在窗口上,不能落在cmd窗口上. 另外,一般在imshow()后要使用waitKey(),给图像绘制留下时间,不然窗口会出现无响应情况,并且图像无法显示出来. int waitKey(int delay=0) - 延时delay = 0 函数则延时无限长,必须有键按下才继续执行. - 延时delay > 0 函数返回值为按下的键的ASCII码值,超时则返回-1. OpenCV: waitKey waitKey Waits for a pressed key. C++: in
-
对Python正则匹配IP、Url、Mail的方法详解
如下所示: """ Created on Thu Nov 10 14:07:36 2016 @author: qianzhewoniuqusanbu """ import re def RegularMatchIP(ip): '''进行正则匹配ip,加re.IGNORECASE是让结果返回bool型''' pattern=re.match(r'\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?
-
Python基于百度AI的文字识别的示例
使用百度AI的文字识别库,做出的调用示例,其中filePath是图片的路径,可以自行传入一张带有文字的图片,进行识别. 下载baidu-aip这个库,可以直接使用pip下载:pip install baidu-aip,也可以在PyCharm等开发工具中下载. 然后运行下列代码即可. # -*- coding: UTF-8 -*- from aip import AipOcr import json # 定义常量 APP_ID = '9851066' API_KEY = 'LUGBatgyRGoe
-
人工智能(AI)首选Python的原因解析
一.为何人工智能(AI)首选Python? 读完这篇文章你就知道了.我们看谷歌的TensorFlow基本上所有的代码都是C++和Python,其他语言一般只有几千行 .如果讲运行速度的部分,用C++,如果讲开发效率,用Python,谁会用Java这种高不成低不就的语言搞人工智能呢? Python虽然是脚本语言,但是因为容易学,迅速成为科学家的工具(MATLAB也能搞科学计算,但是软件要钱,且很贵),从而积累了大量的工具库.架构,人工智能涉及大量的数据计算,用Python是很自然的,简单高效. P
-
AI人工智能 Python实现人机对话
在人工智能进展的如火如荼的今天,我们如果不尝试去接触新鲜事物,马上就要被世界淘汰啦~ 本文拟使用Python开发语言实现类似于WIndows平台的"小娜",或者是IOS下的"Siri".最终达到人机对话的效果. [实现功能] 这篇文章将要介绍的主要内容如下: 1.搭建人工智能--人机对话服务端平台 2.实现调用服务端平台进行人机对话交互 [实现思路] AIML AIML由Richard Wallace发明.他设计了一个名为 A.L.I.C.E. (Artificia
-
10 行Python 代码实现 AI 目标检测技术【推荐】
只需10行Python代码,我们就能实现计算机视觉中目标检测. from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_b
-
10行Python代码计算汽车数量的实现方法
当你还是个孩子坐车旅行的时候,你玩过数经过的汽车的数目的游戏吗? 在这篇文章中,我将教你如何使用10行Python代码构建自己的汽车计数程序.以下是环境及相应的版本库: Python版本 3.6.9 cvlib: 0.2.2 opencv-python: 4.1.1.26 tensorflow: 1.14.0 matplotlib: 3.1.1 Keras: 2.2.5 下面的代码用于导入所需的python库.从存储中读取图像.对图像执行目标检测.用边界框显示图像以及关于检测目标的标签.计算图像
-
10行Python代码就能实现的八种有趣功能详解
目录 一.生成二维码 二.生成词云 三.批量抠图 四.文字情绪识别 五.识别是否带了口罩 六.简易信息轰炸 七.识别图片中的文字 八.简单的小游戏 Python凭借其简洁的代码,赢得了许多开发者的喜爱.因此也就促使了更多开发者用Python开发新的模块,从而形成良性循环,Python可以凭借更加简短的代码实现许多有趣的操作.下面我们来看看,我们用不超过10行代码能实现些什么有趣的功能. 一.生成二维码 二维码又称二维条码,常见的二维码为QR Code,QR全称Quick Response,是一个
-
10 行 Python 代码教你自动发送短信(不想回复工作邮件妙招)
最近工作上有个需求,当爬虫程序遇到异常的时候,需要通知相应的人员进行修复.如果是国外可能是通过邮件的方式来通知,但国内除了万年不变的 qq 邮箱,大部分人都不会去再申请其他的账号,qq 邮箱也是闲的蛋疼的时候才会瞄一眼.你还记得上次看邮箱的内容是什么时候吗? 所以在国内最好的通知方式是通过手机短信,今天就教大家利用 python 10 行代码实现短信发送. Twilio 短信代理服务已经有非常多成熟的方案,比如国内的阿里云.这次我介绍的是国外的一个代理商「Twilio」,使用邮箱注册即送 15
-
10行Python代码实现Web自动化管控的示例代码
本博客将为各位分享Python Helium库,其是在 Selenium库基础上封装的更加高级的 Web 自动化工具,它能够通过网页端可见的标签.名称来和 Web 进行交互,据说比Selenium库简单50%,Helium库主要功能包括:模拟鼠标点击.滑动功能:模拟键盘按键功能:刷新网页功能等. 通过使用Helium库,了解其基本的API使用,即使不熟悉HTML.CSS等网页知识,也可轻松完成网页自动化开发设计,实现学习.工作所需. 1.模块安装 Helium库安装使用pip指令即可实现,如下所
-
利用ImageAI库只需几行python代码实现目标检测
什么是目标检测 目标检测关注图像中特定的物体目标,需要同时解决解决定位(localization) + 识别(Recognition).相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示). 通俗的说,Object Detection的目的是在目标图中将目标用一个框框出来,并且识别出这个框中的是啥,而且最好的话是能够将图片的所
-
50行Python代码实现人脸检测功能
现在的人脸识别技术已经得到了非常广泛的应用,支付领域.身份验证.美颜相机里都有它的应用.用iPhone的同学们应该对下面的功能比较熟悉 iPhone的照片中有一个"人物"的功能,能够将照片里的人脸识别出来并分类,背后的原理也是人脸识别技术. 这篇文章主要介绍怎样用Python实现人脸检测.人脸检测是人脸识别的基础.人脸检测的目的是识别出照片里的人脸并定位面部特征点,人脸识别是在人脸检测的基础上进一步告诉你这个人是谁. 好了,介绍就到这里.接下来,开始准备我们的环境. 准备工作 本文的人
-
Python Opencv实现单目标检测的示例代码
一 简介 目标检测即为在图像中找到自己感兴趣的部分,将其分割出来进行下一步操作,可避免背景的干扰.以下介绍几种基于opencv的单目标检测算法,算法总体思想先尽量将目标区域的像素值全置为1,背景区域全置为0,然后通过其它方法找到目标的外接矩形并分割,在此选择一张前景和背景相差较大的图片作为示例. 环境:python3.7 opencv4.4.0 二 背景前景分离 1 灰度+二值+形态学 轮廓特征和联通组件 根据图像前景和背景的差异进行二值化,例如有明显颜色差异的转换到HSV色彩空间进行分割. 1
-
Python 使用Opencv实现目标检测与识别的示例代码
在上章节讲述到图像特征检测与匹配 ,本章节是讲述目标检测与识别.后者是在前者的基础上进一步完善. 在本章中,我们使用HOG算法,HOG和SIFT.SURF同属一种类型的描述符.功能代码如下: import cv2 def is_inside(o, i): ox, oy, ow, oh = o ix, iy, iw, ih = i # 如果符合条件,返回True,否则返回False return ox > ix and oy > iy and ox + ow < ix + iw and o